
一、后端基础环境准备
安装JDK1.8 ,高于1.8_221以上(下载地址见书籍【附件一】)
-
打开Windows环境变量配置页
此电脑 => 右键属性 => 系统高级设置 => 环境变量
-
配置环境变量
在用户环境变量中新建变量为JAVA_HOME的项,值为JDK安装之后的路径
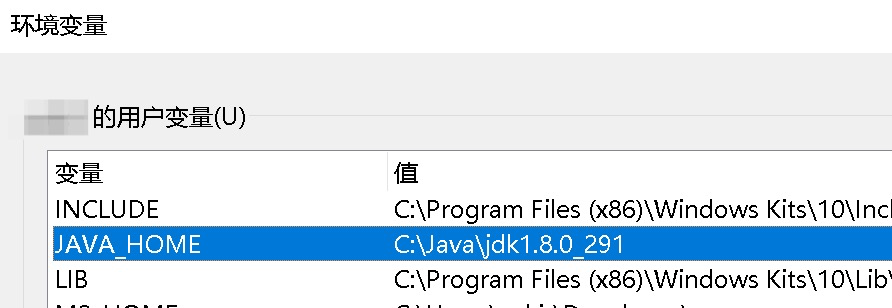

编辑变量为Path的项添加一个值%JAVA_HOME%\bin

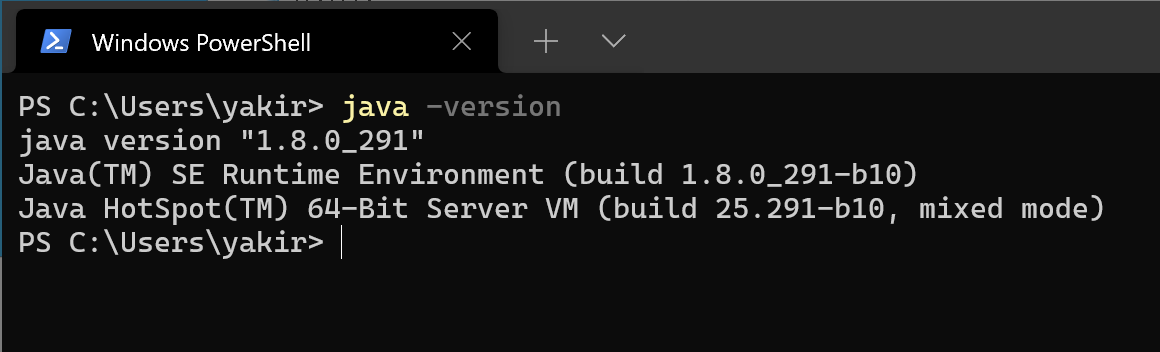
- PowerShell或者CMD中验证,输出类似信息为安装配置成功
安装 Apache Maven 3.8+ (下载地址见书籍【附件一】)
-
删除Maven安装目录下的conf/settings.xml
-
配置mvn的settings,下载附件settings-open.xml,并重命名为settings.xml,建议直接放在【C:\Users\你的用户名.m2】下面。下载地址见oinone开源社区群公告,也可以联系oinone合作伙伴或服务人员
-
配置环境变量 在用户环境变量中新建变量为M2_HOME的项,值为Maven安装路径

编辑变量为Path的项添加一个值%M2_HOME%\bin
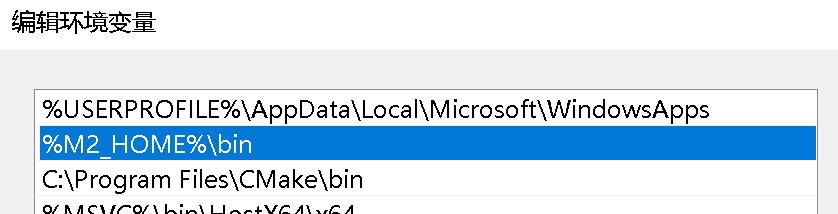
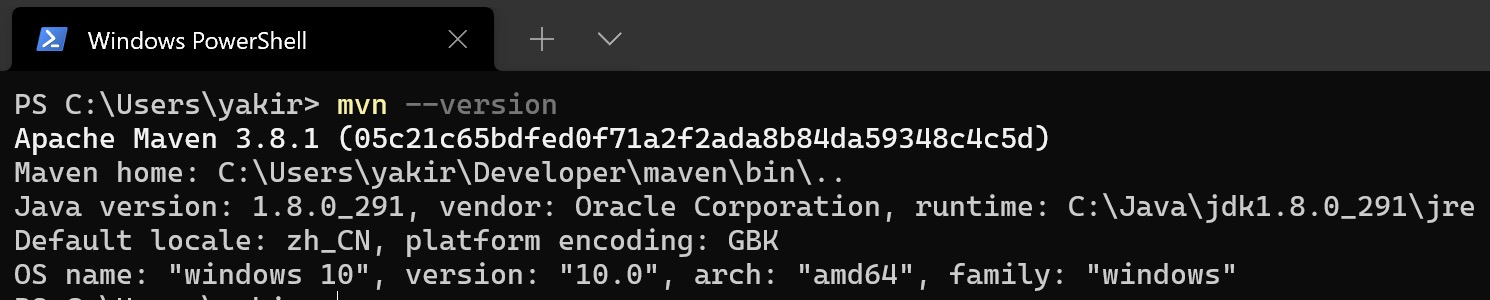
- 验证
安装 Jetbrains IDEA (下载地址见书籍【附件一】)
-
插件安装 下载地址 密码: mdji
-
如果IDEA安装了Lombok插件,请禁用Lombok插件
-
点击菜单项File => Settings => Plugins

下载插件包 (联系Oinone官方客服)
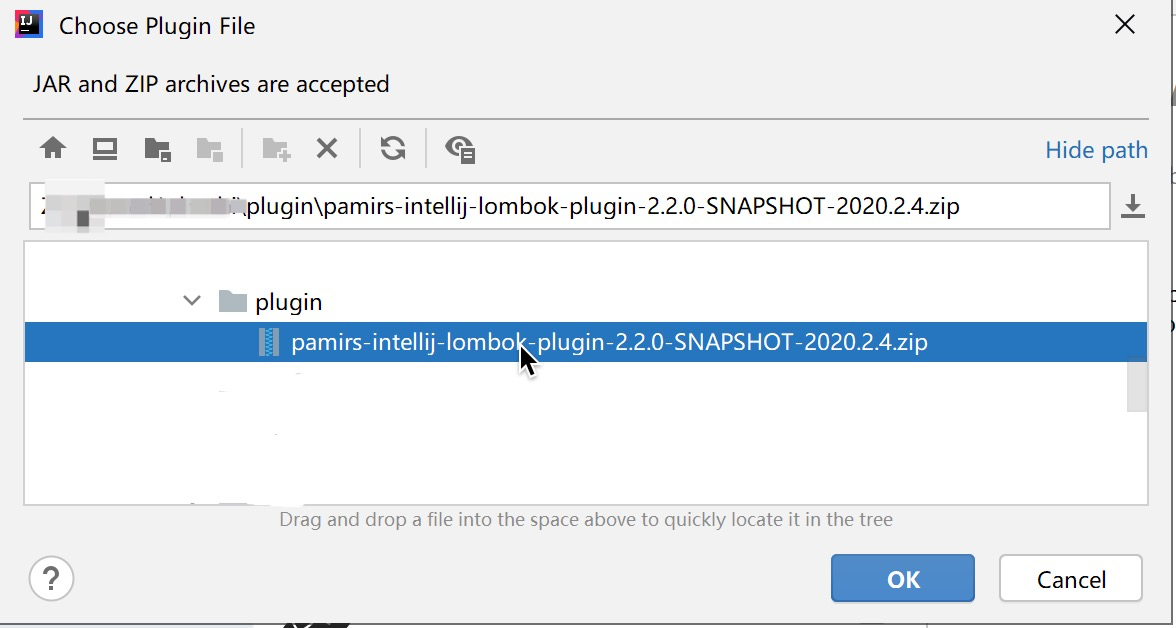

安装MySQL 8 (下载地址见书籍【附件一】)
-
解压下载的ZIP安装包, 复制到自定义安装目录
-
设置环境变量 MYSQL_BASE_DIR
提换成MySQL安装目录路径
- 把 %MYSQL_BASE_DIR%\bin 加入到系统环境变量中
在PowerShell中可以使用 Get-Command mysqld 命令验证环境变量是否配置成功,执行成功输出mysqld的所在路径
- 初始化
在命令行中执行 mysqld --initialize-insecure --user=mysql
-
安装
mysqld -install
-
启动MySQL服务
mysqld -install
-
设置root用户密码
alter user \'root\'@\'localhost\' identified with mysql_native_password by \'oinone\'; flush privileges;
安装DB GUI工具
Datagrip、MySQLWorkbench、DBEaver 选其一 ### 安装Git (下载地址见书籍【附件一】)
安装GraphQL测试工具Insomnia(下载地址见书籍【附件一】)
安装RocketMQ(下载地址见书籍【附件一】)
-
修改安装目录下bin中对应文件的默认配置
a. runserver.cmd文件内容 -Xms2g -Xmx2g为 -Xms1g -Xmx1g
b. runbroker.cmd文件内容 -Xms2g -Xmx2g为 -Xms1g -Xmx1g,以及-XX:G1HeapRegionSize=1m
-
启动RocketMQ NameServer命令 RocketMQ安装目录\bin\mqnamesrv.cmd start
-
启动RocketMQ Broker命令 RocketMQ安装目录\bin\mqbroker.cmd -n localhost:9876
-
停止 RocketMQ命令 mqshutdown.cmd broker mqshutdown.cmd namesrv
安装ElasticSearch 版本 8.4.1(下载地址见书籍【附件一】) (非必须)
ES运行时需要JDK18及以上版本JDK运行环境, ES安装包中包含了一个JDK18版本
set JAVA_HOME=ES安装路径\jdk
- 启动
ES安装路径\bin\elasticsearch.bat
- 停止 ctrl+c 或者关闭cmd、PowerShell的窗口
安装Redis (下载地址见书籍【附件一】)
-
解压安装包到安装目录
-
在PowerShell进入到Redis安装目录
-
在PowerShell中执行.\redis-server.exe,输出图中类似信息(如下图3-35所示):
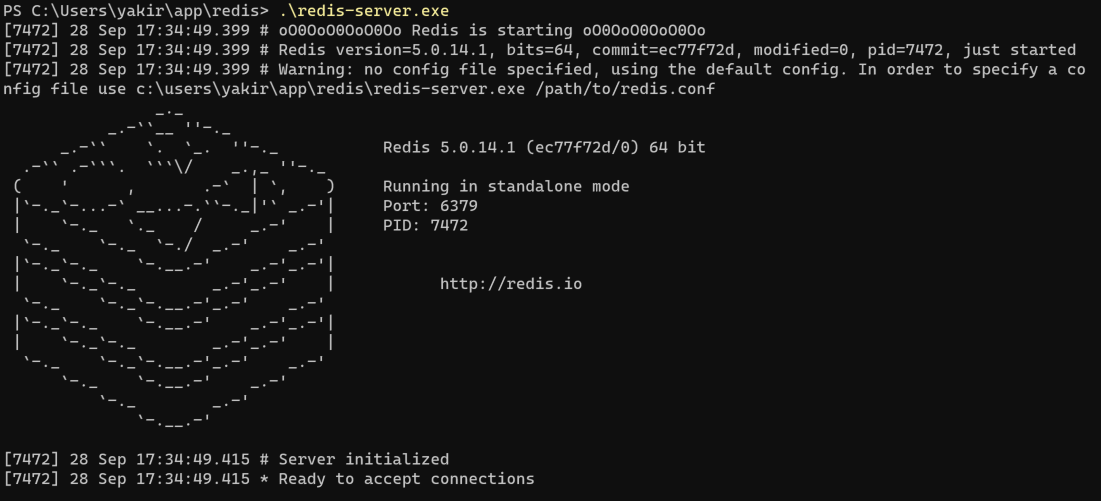
- 新开PowerShell窗口, 进入到Redis安装目录, 执行 .\redis-cli.exe回车,输入 ping 回车输出 PONG即表示Redis安装成功

Zookeeper安装(下载地址见书籍【附件一】)
-
解压安装, 在 PowerShell中执行 tar zxvf 安装包路径(tar.gz包) -C Zk安装目录
-
进入 Zk安装目录\conf\ 复制 zoo_sample.cfg文件为 zoo.cfg
-
修改zoo.cfg文件的内容 (其中dataDir需要自己设定)
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=需要设置路径用来保存zk数据
maxClientCnxns=120
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
admin.enableServer=false- 进入 Zk安装目录\bin\执行 zkServer.cmd 5新开PowerShell窗口, 进入到Zk安装目录, 执行 zkCli.cmd, 连接成功后输入 ls /输出类似信息即安装成功

二、前端环境准备
a.下载zip包之后解压到安装目录
b. 配置环境变量
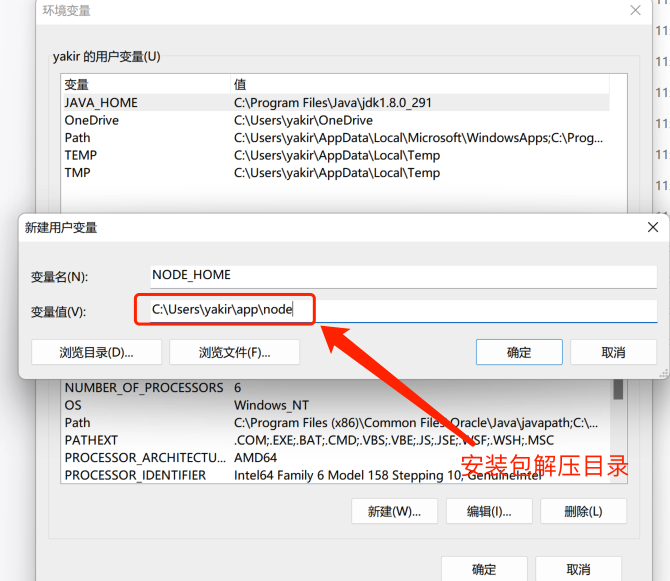
ⅰ. 添加NODE_HOME环境变量
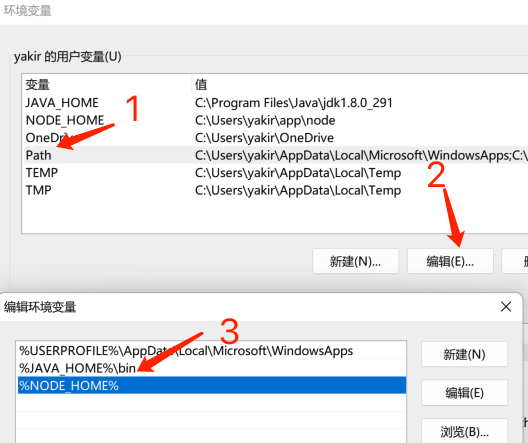
ⅱ. 编辑PATH环境变量
c. 打开PowerShell输入
node --version
npm --version输出类似信息,即为成功安装node与npm
- 安装vue-cli
npm install @vue/cli@4.5.17 -g安装完成之后执行vue --version,输出类似信息,即为成功安装vue-cli

- 配置NPM源
npm config set registry http://nexus.shushi.pro/repository/kunlun/- 登录NPM源账
npm login --registry "http://nexus.shushi.pro/repository/kunlun/"
# username、password、email 请见oinone开源社区群公告,也可以联系oinone合作伙伴或服务人员
npm info underscore
- 安装cnpm (参见https://www.npmjs.com/package/cnpm)
npm install cnpm -g --registry=https://registry.npmmirror.com cnpm.cmd --version图3-1-51 安装cnpm
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9226.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验