
SPI(Service Provider Interface)服务提供接口,是一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展和替换组件,简单来说就是用来解耦,实现组件的自由插拔,这样我们就能在平台提供的基础组件外扩展新组件或覆盖平台组件。
| 目前定义SPI组件 | |
|---|---|
| ViewWidget | 视图组件 |
| FieldWidget | 字段组件 |
| ActionWidget | 动作组件 |
表4-2-3-1 目前定义SPI组件
前提知识点
1. 通过注解定义一种SPI接口(Interface)
@SPI.Base<IViewFilterOptions, IView>('View', ['id', 'name', 'type', 'model', 'widget'])
export abstract class ViewWidget<ViewData = any> extends DslNodeWidget {
}2. 通过注解注册提供View类型接口的一个或多个实现
@SPI.Base<IViewFilterOptions, IView>('View', ['id', 'name', 'type', 'model', 'widget'])
export abstract class ViewWidget<ViewData = any> extends DslNodeWidget {
}3. 视图的xml内通过配置来调用已定义的一种SPI组件
<view widget="form" model="demo.shop">
<field name="id" />
</view>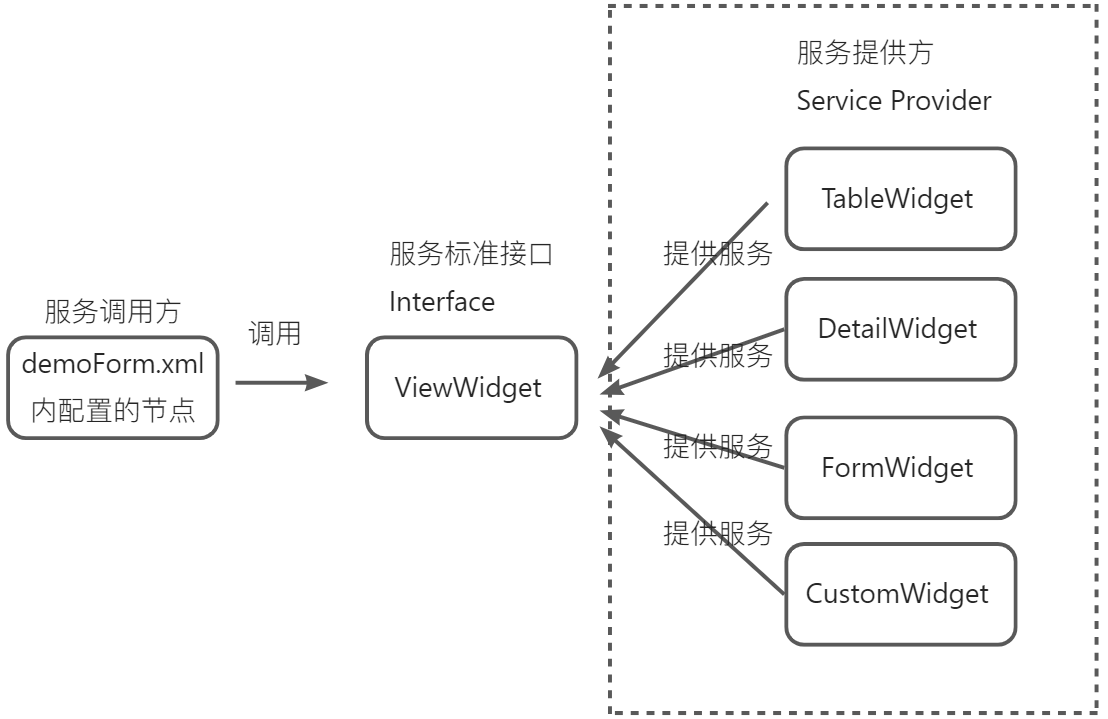

当有多个服务提供方时,按以下规则匹配出最符合条件的服务提供方
SPI匹配规则
SPI组件没有严格的按匹配选项属性限定,而是一个匹配规则
-
按widget最优先匹配,配置了widget等于是指定了需要调用哪个widget,此时其他属性直接忽略
-
按最大匹配原则(匹配到的属性越多优先级越高)
-
按后注册优先原则
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9304.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验