
模块(module)
概念
在 Oinone 系统的架构中,模块(module)是核心组成元素之一,可以被理解为域(domain)的一个具象化概念。模块的来源有两种:一种是基于后端代码定义,另一种是通过无代码新增。具体的代码定义方式,请参考“[占位符]”,而无代码定义的相关信息则可在“[占位符]”找到。在 Oinone 体系中,模块对应两种实体:模块和应用。
- 模块: 这是一类特定能力的集合,它可以依赖其他模块,也可以被其他模块依赖。
- 应用: 它是一种特殊的模块,具备模块的所有特性,并在此基础上可被终端用户访问。
使用
在前端开发中,module通常以应用的形式出现,它们往往对前端用户保持透明。在接下来的讨论中,我们主要围绕应用来探讨module的使用。从应用的角度出发,我们可以在前端开发中识别出以下几种典型使用场景,并通过具体的业务案例来加以说明
- 应用菜单扩展: 实现自定义母版来定义特定应用的菜单
- 表格布局扩展: 用于自定义布局的工具,以定义特定应用的表格布局
在这些场景中,我们着重实现了应用层面的隔离,确保每个模块都能在应用的维度上独立运作
查找
在实际业务开发中,有3个方式可以找到应用
- 浏览器url查找(查找速度快,可能不准)
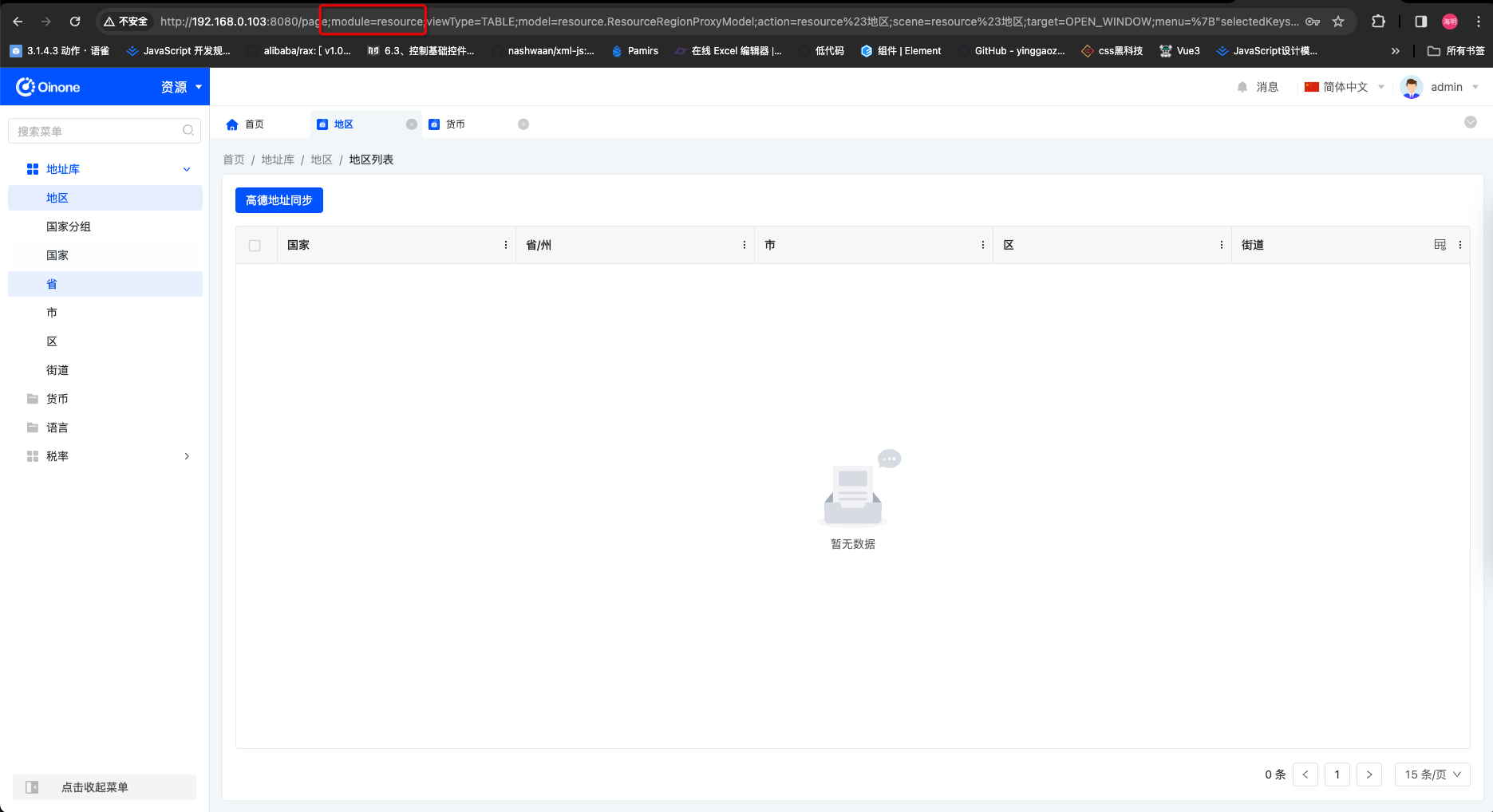

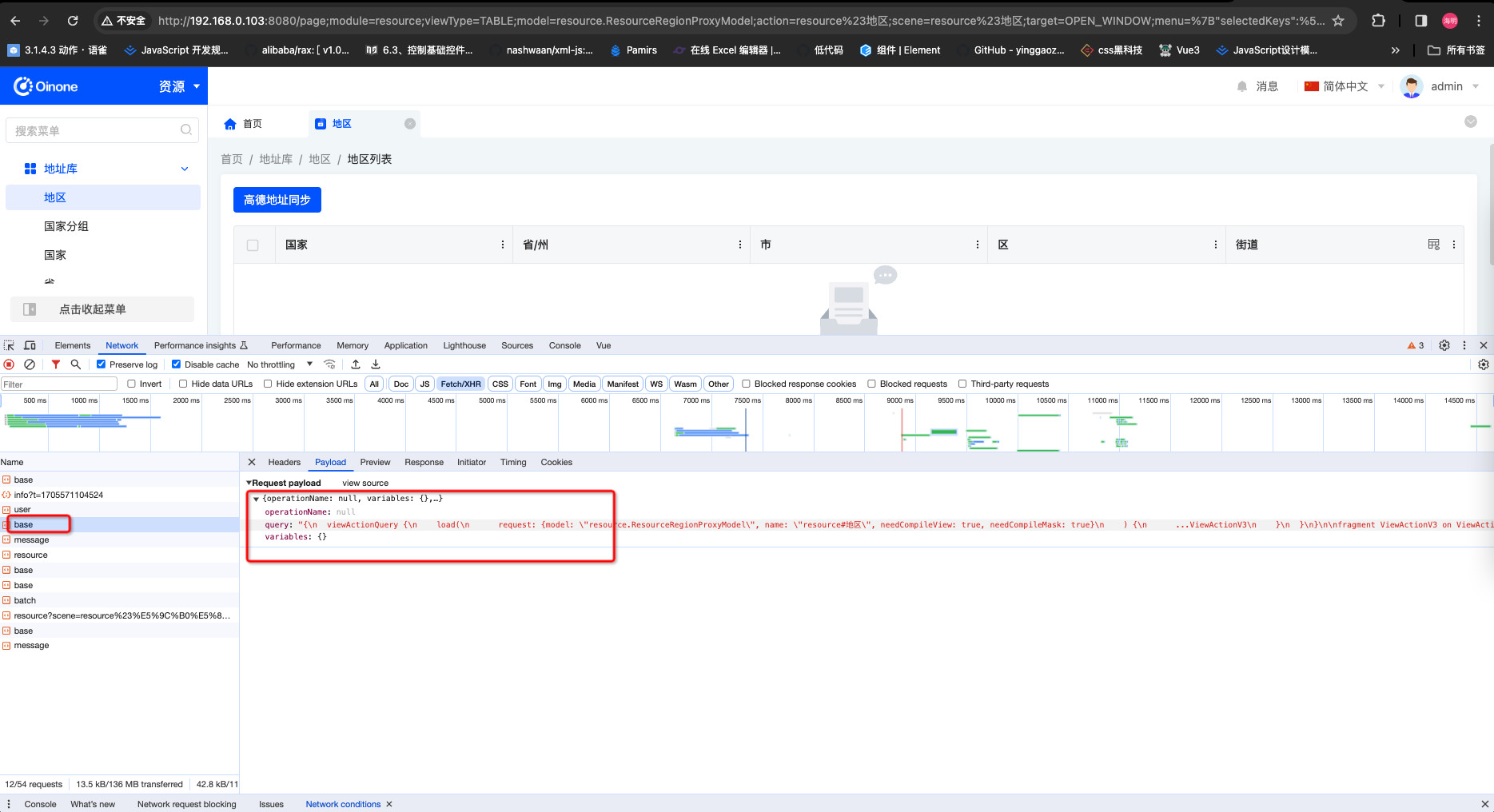
- 接口返回查找
第一步找到截图类似请求
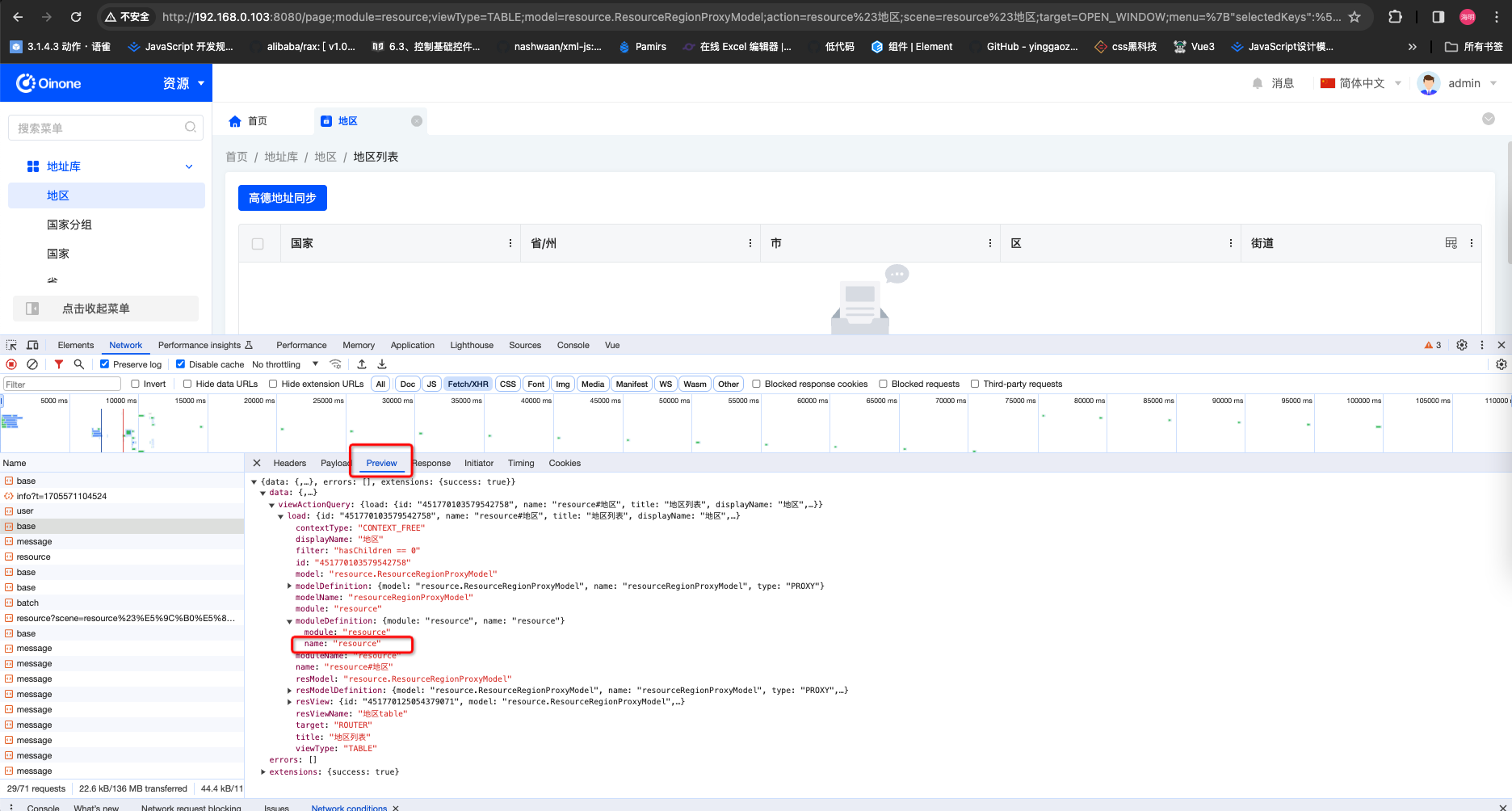
第二步根据返回找应用
- vue调试器选中对应的组件查找
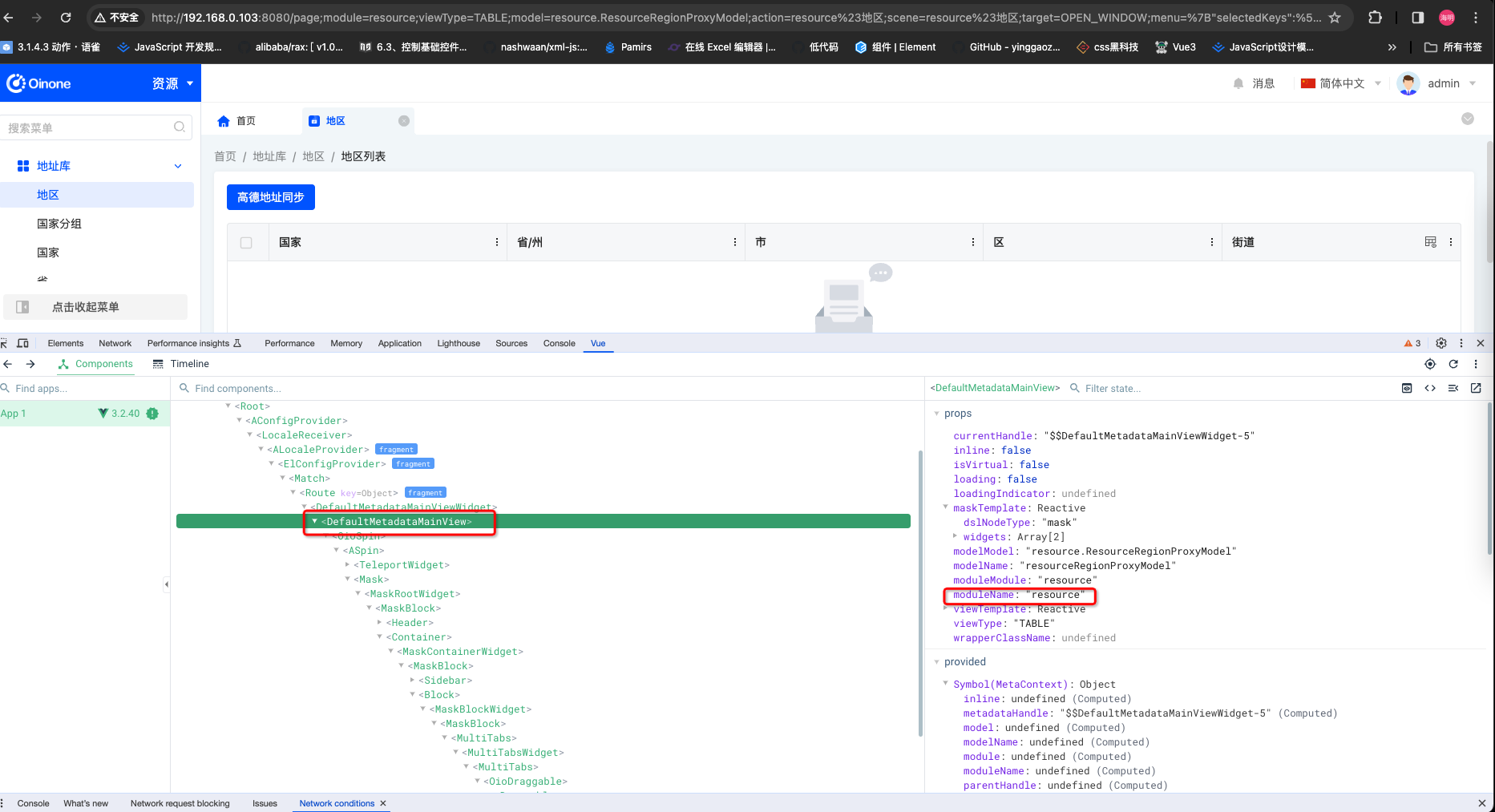
推荐使用浏览器url查找,若与预期不符,可用另外两种方式查找
模型(model)
概念
在 Oinone 系统的架构中,模型(model)是另一个关键核心组成部分。模型在业务层面主要体现之一为数据库的实体表,它是承载业务实现的基础结构。要了解模型的详细介绍,请参考“[占位符]”,前端所用的模型,对应后端代码定义来说,代表的是模型的编码。
关于模型的定义,我们提供了两种方法:
- 代码定义: 对于需要通过编程实现的模型定义,您可以参考“[占位符]”来了解具体的代码实现方法;
- 无代码定义:如果您倾向于使用无代码工具来定义模型,具体的操作和流程可以在“[占位符]”中找到
使用
在前端开发中,模型是前端运行的必要条件,以下场景中,模型不直接感知:
- 视图渲染
- 页面之间跳转交互
- 与后端交互
以下场景中,模型会直接决定前端的渲染逻辑
- 母版扩展:为某模型扩展母版
- 布局扩展:为某模型扩展布局
- 页面扩展:为某模型扩展个性化页面
- 字段扩展: 扩展字段时加上模型的范围
- 动作扩展: 扩展动作时加上模型的范围
以上场景中,涵盖了前端工作的方方面面,在OInone体系中,模型不止是后端运行得基础,同样也决定了前端如何运行,那这样做有什么好处呢?
- 前后端几乎不需要联调,联调的协议用模型来承载
- 前端无需定义路由、权限埋点
查找
在实际业务开发中,有3个方式可以找到模型
- 浏览器url查找
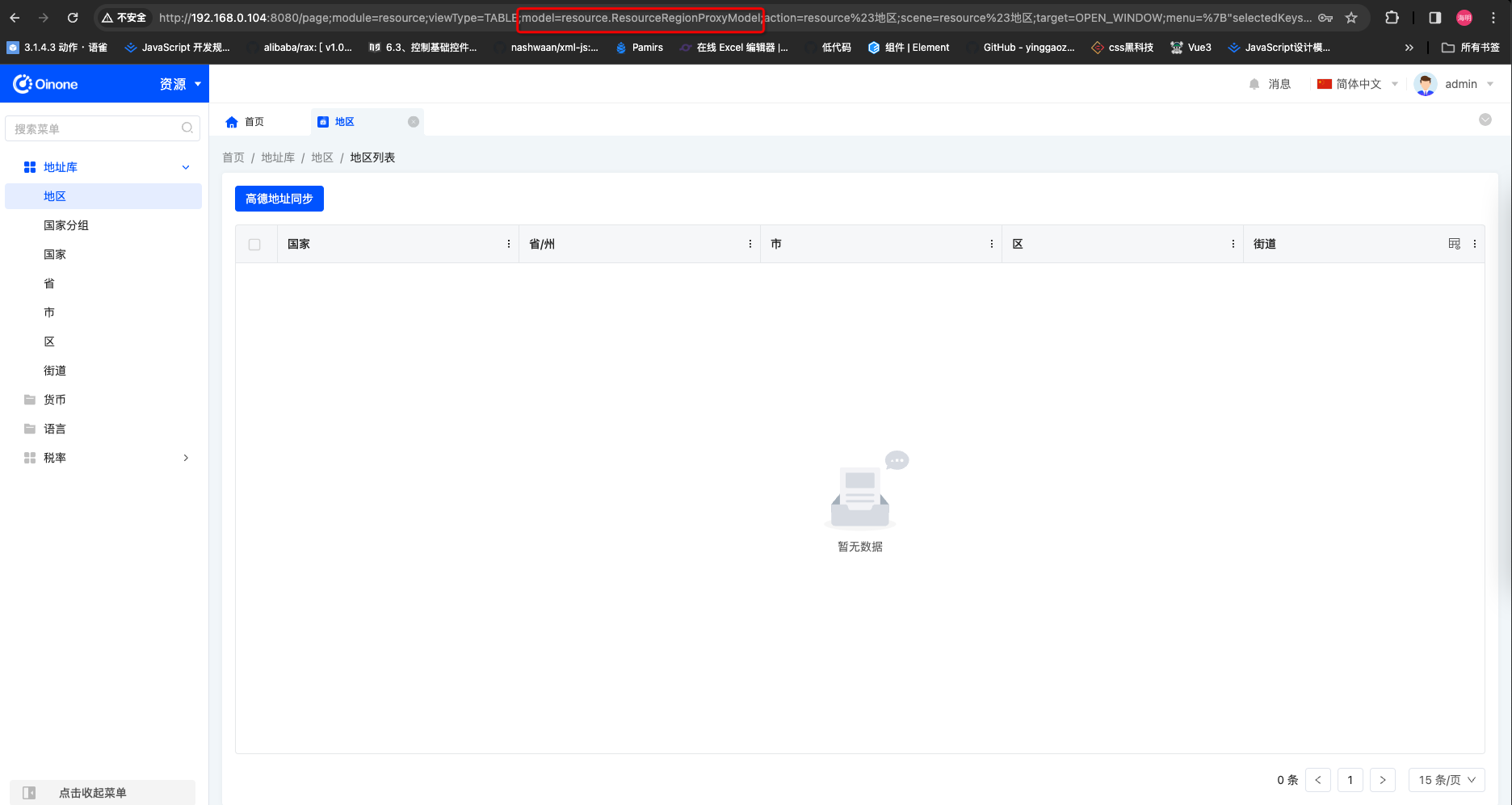
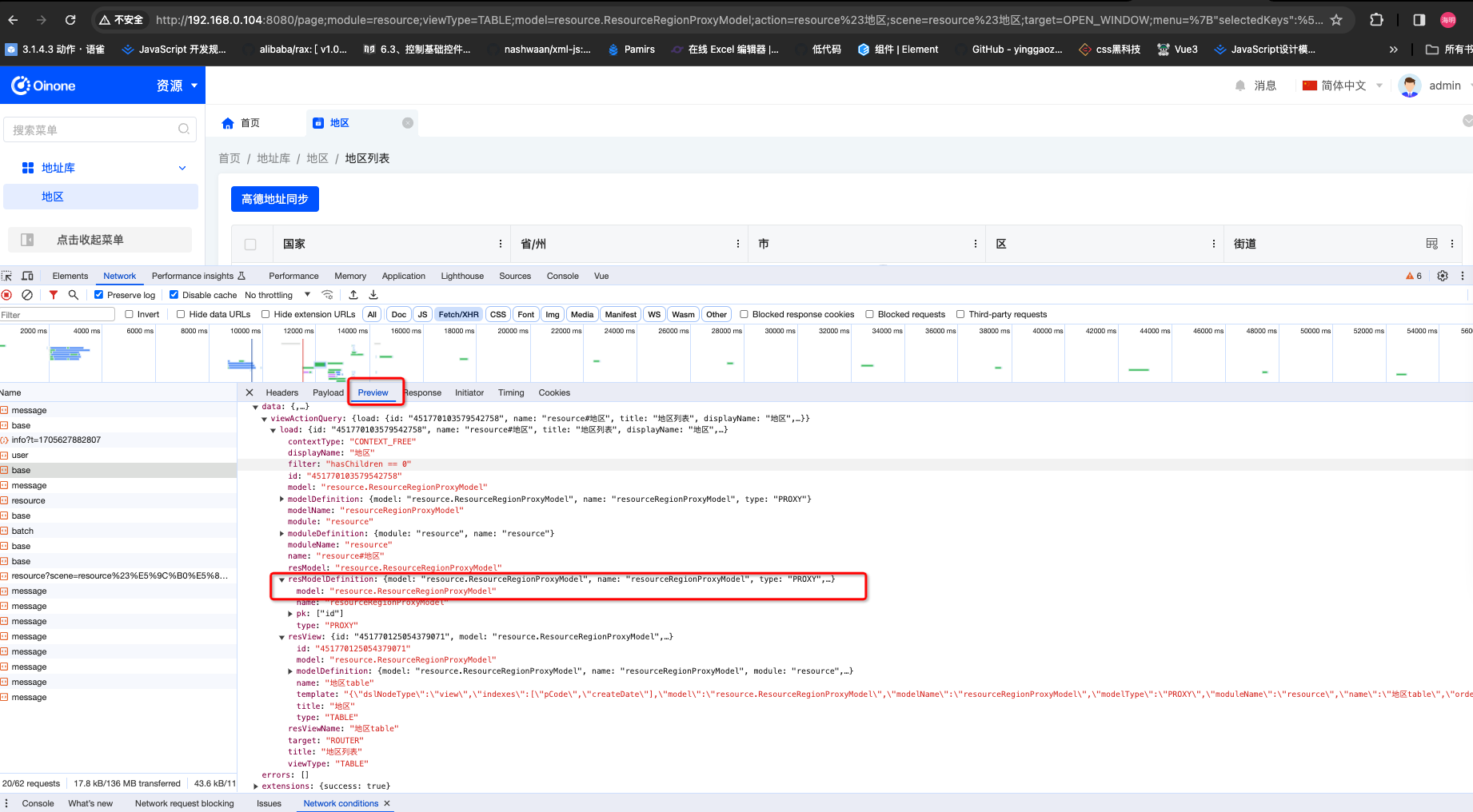
- 接口返回查找
第一步找到类似截图请求
第二步根据返回找模型
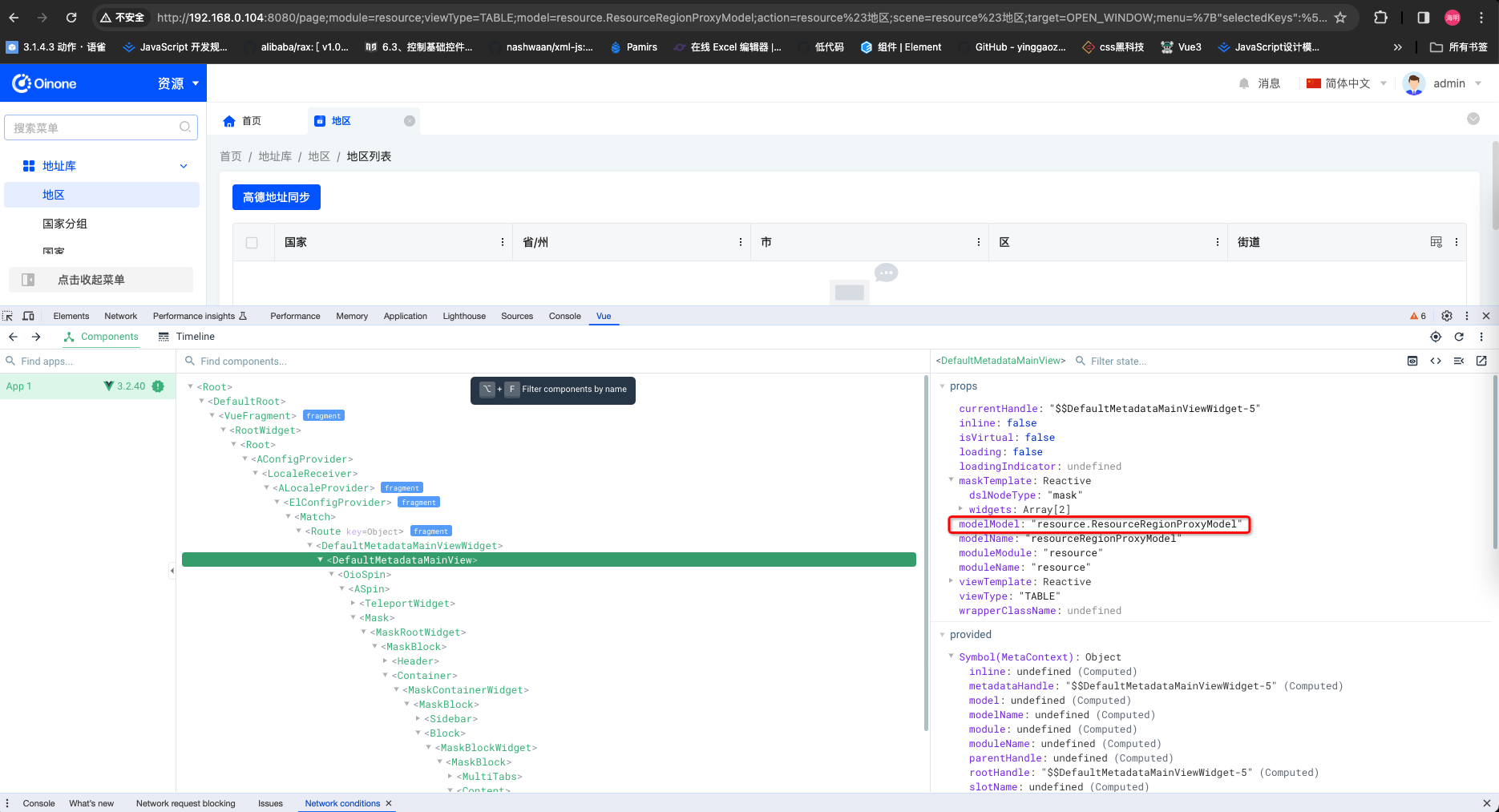
- vue调试器选中对应的组件查找
动作(action)
概念
动作(action)定义了终端用户得交互,它描述了前端与前端、前端与后端之间的交互。
动作涵盖了前端以下部分:
- 页面跳转(router)
- 调用后端接口
- 页内交互(打开弹窗、打开抽屉)
它有两部分的来源:
- 模型内定义动作
- 窗口动作(页面跳转、打开弹窗、打开抽屉)
- 服务器动作(调接口)
- 前端定义客户端动作,可自定义其它逻辑,例如: 把选中行的某一列数据复制一下
使用
动作的使用绝大部分的情况是由平台自动执行的,在平台执行不符合预期时可以使用自定义动作自行扩展
查找
- vue调试器选中对应的组件查找
- 选中服务器动作(ServerAction)
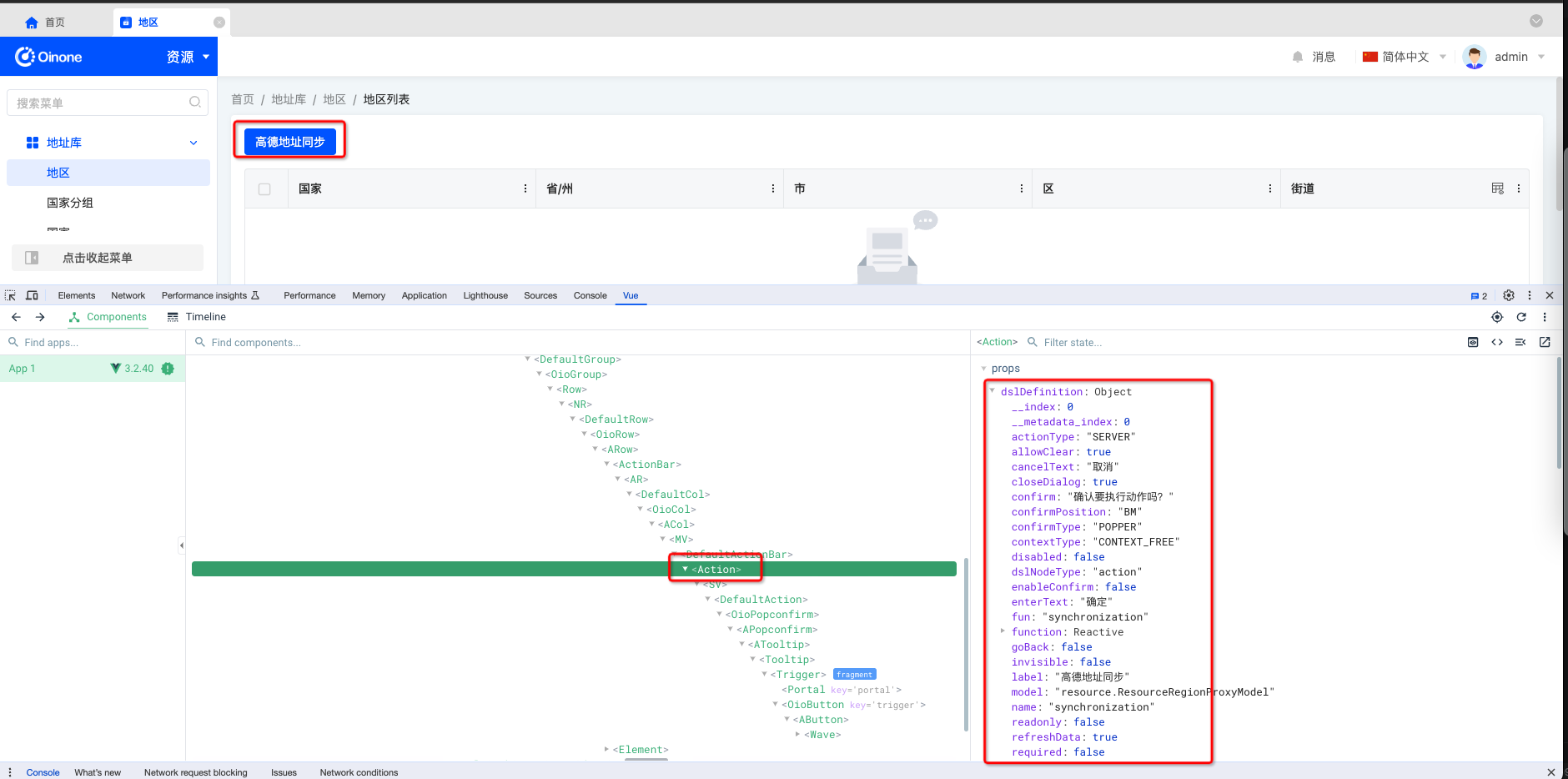
- 选中窗口动作(ViewAction)
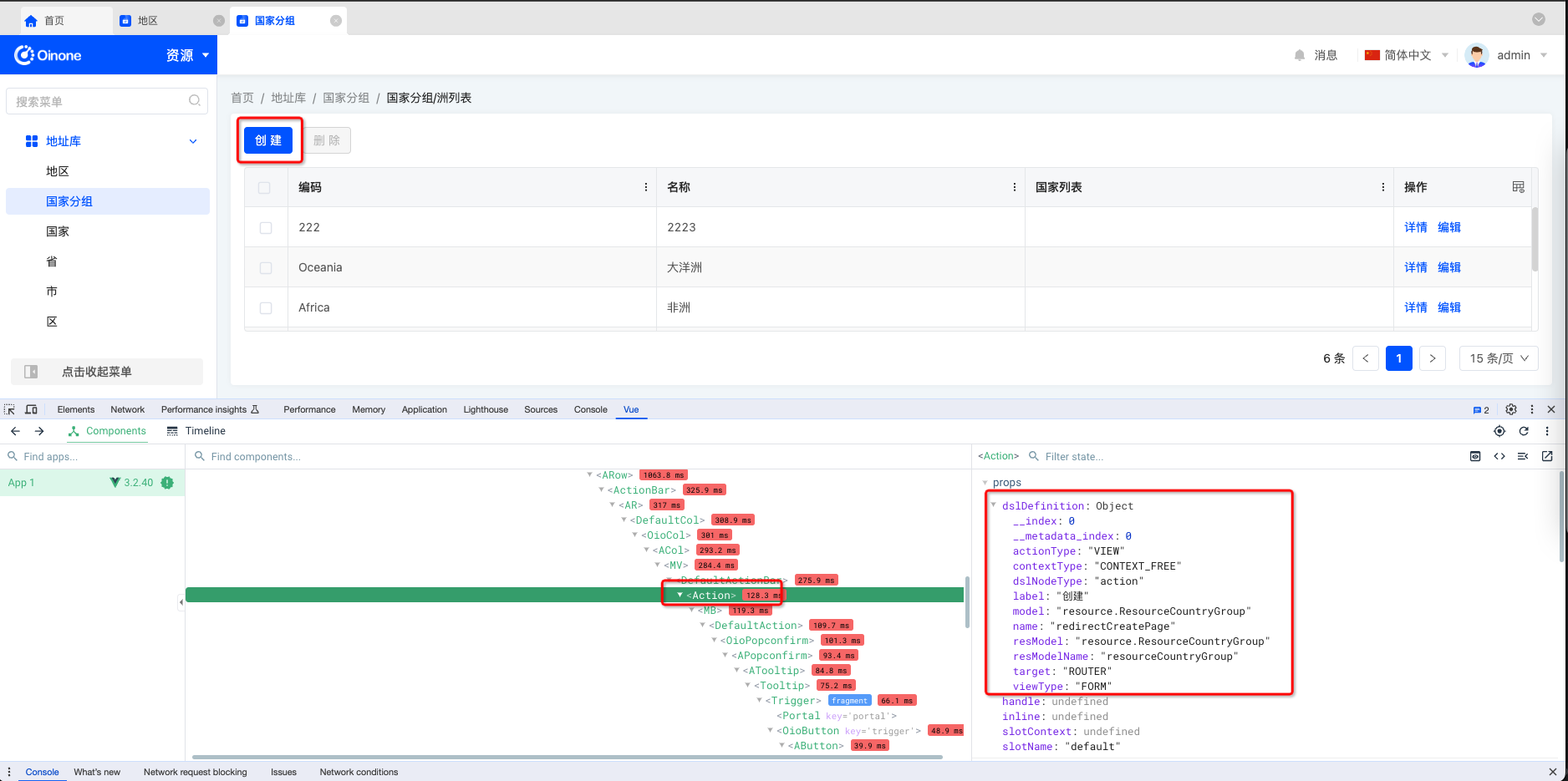
字段(field)
概念
在我们的后端模型中,字段(Field)是核心的定义元素,它们在数据库中表现为数据表的列。更重要的是,这些字段在前端应用中发挥着数据传输的关键作用。例如,当前端需要调用后端接口时,它会发送如下结构的数据:
这里的 "name" 是一个字段实例,它连接了前后端的交互。在后端,该字段不仅用于数据存储,也参与逻辑运算。
字段在 Oinone 系统中的加强应用
在 Oinone 系统中,字段的功能得到了扩展。除了基本的前后端数据交互,字段的定义还直接影响前端的用户界面(UI)交互。例如:
-
前端交互组件的选择:前端交互组件的类型取决于字段的数据类型。对于 String 类型的 "name" 字段,前端会使用输入框来收集用户输入的 "张三"。
-
数据存储和类型定义:在后端,"name" 字段被明确定义为 String 类型,这决定了它如何存储和处理数据。
字段与前端组件定义的解耦
一个关键的设计原则是,前端组件的定义与具体的字段值或字段名(如 "name" 或 "张三")不直接相关,而是基于字段的数据类型(此例中为 String)。这种设计实现了:
- 前端组件的一致性:确保所有组件的输入输出遵循同一数据类型(如 String)。
- 高度的组件复用性:在满足 UI 要求的前提下,任何 String 类型的字段都可以使用这种通用的组件设计。
使用
Oinone 系统中的视图与字段交互的灵活性
Oinone 系统为每种视图和字段类型(Ttype)提供了默认的交互模式。这不仅保证了前端工程启动时所有界面的即时展示,也为开发者带来了高度的灵活性和扩展能力。以下是这一设计理念的关键点:
1. 视图与字段交互的默认实现
每种视图都有对应字段类型(Ttype)的默认交互实现,确保用户界面一致且直观。这使得在前端工程启动时,所有界面能够无需额外配置即可正常展示。
2. 灵活性与扩展能力
尽管系统提供了默认的交互方式,开发者仍然拥有自定义这些交互方式的能力。这意味着开发者可以根据应用需求,设计更加贴合业务逻辑和用户体验的交互模式。
3. 覆盖和替换默认组件
最为重要的是,开发者不仅可以添加新的交互方式,还可以完全覆盖和替换系统的默认组件。这提供了极大的自由度,使开发者能够根据具体场景重新设计和实现界面组件,从而达到完全定制化的用户体验。
查找
- vue调试器选中对应的组件查找
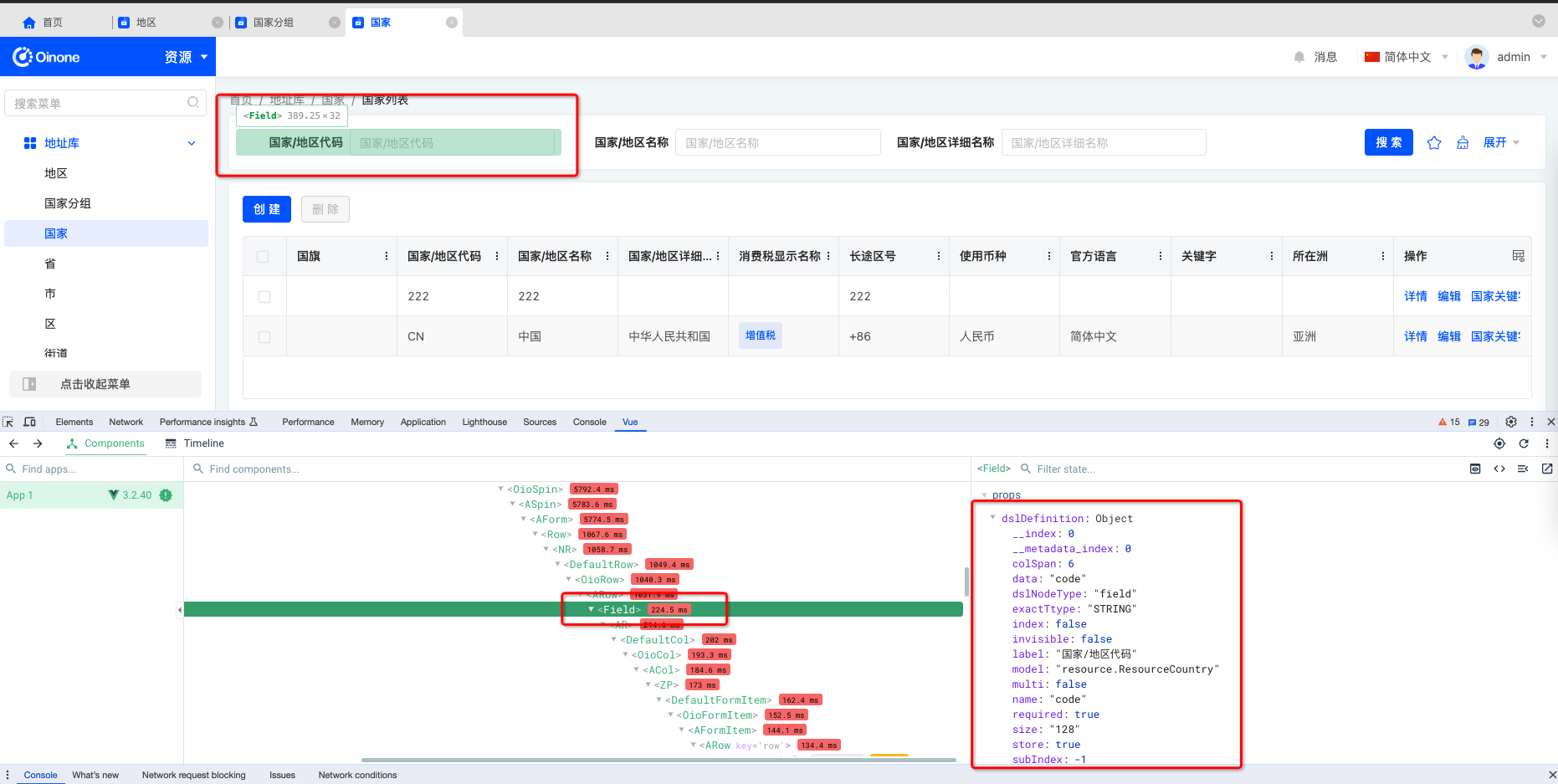
视图类型(viewType)
概念
在 Oinone 系统中,视图是模型在前端的具体表现形式。视图的核心组成和功能如下:
1. 组成要素
- 字段:视图中的字段代表了模型的数据结构,它们是界面上数据显示和交互的基础。
- 动作:视图包含的动作定义了用户可以进行的操作,如添加、编辑、删除等。
- 前端UI:视图的界面设计,包括布局、元素样式等,决定了用户的交互体验。
2. 数据源与交互
- 数据源:视图的数据直接来源于后端模型。这意味着前端视图展示的内容是根据后端模型中定义的数据结构动态生成的。
- 交互:视图不仅展示数据,还提供与数据交互的能力。这些交互也是基于后端模型定义的,包括数据的增删改查等操作。
3. 灵活性
- 视图可以灵活选择是否采用模型的交互。这意味着开发者可以根据需求决定视图仅展示模型的数据,或者同时提供与数据的交互功能。
使用
在 Oinone 系统中,用户可以通过无代码界面设计器轻松配置视图。系统内置了以下主要视图类型:
-
表格(Table)
-
表单(Form)
-
详情(Detail)
-
搜索(Search)
-
画廊(Gallery)
-
树(Tree)
界面设计器配置
- 简便配置:系统提供无代码界面设计器,使用户能够轻松配置内置视图。
- 系统支持视图:表格、表单、详情等内置视图类型可以直接通过设计器进行配置,包括字段的展示和交互。
自定义页面
- 个性化需求:如果用户需求超出系统内置视图的范围,可以选择创建自定义页面。
- 高级专家认证:高级专家认证的用户,理解透前端元数据,可以将自定义页面转化为内置视图之一。
- 与无代码结合:高级专家认证用户可以结合无代码界面设计器,将个性化的页面与系统内置视图深度融合。
通过这种深度的整合和自定义的能力,系统提供了更灵活、更个性化的前端界面配置和设计体验。
查找
- 浏览器url查找
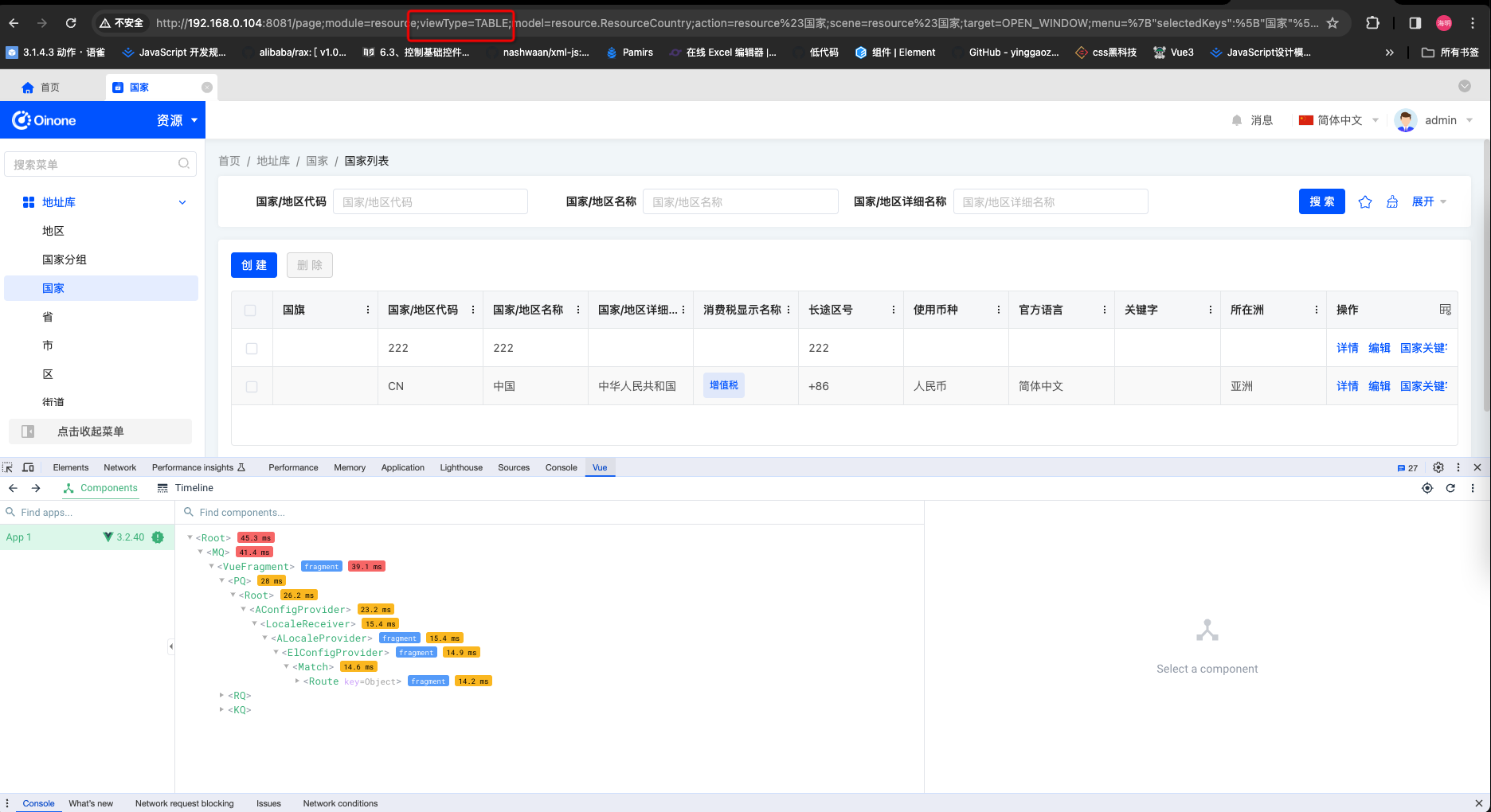
-vue调试器查找
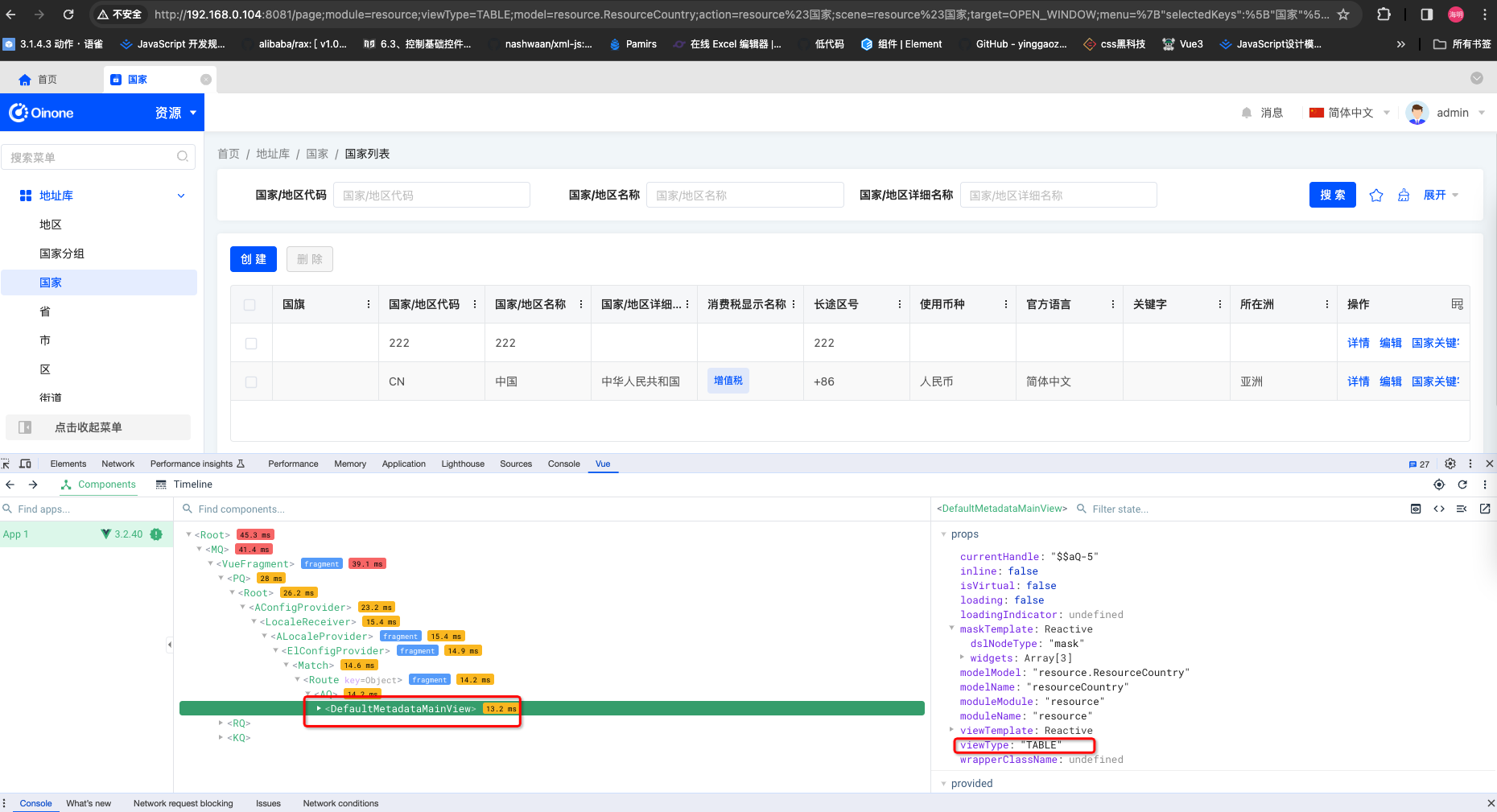
-代码查找
-找到如下代码,点击后看所有类型的定义

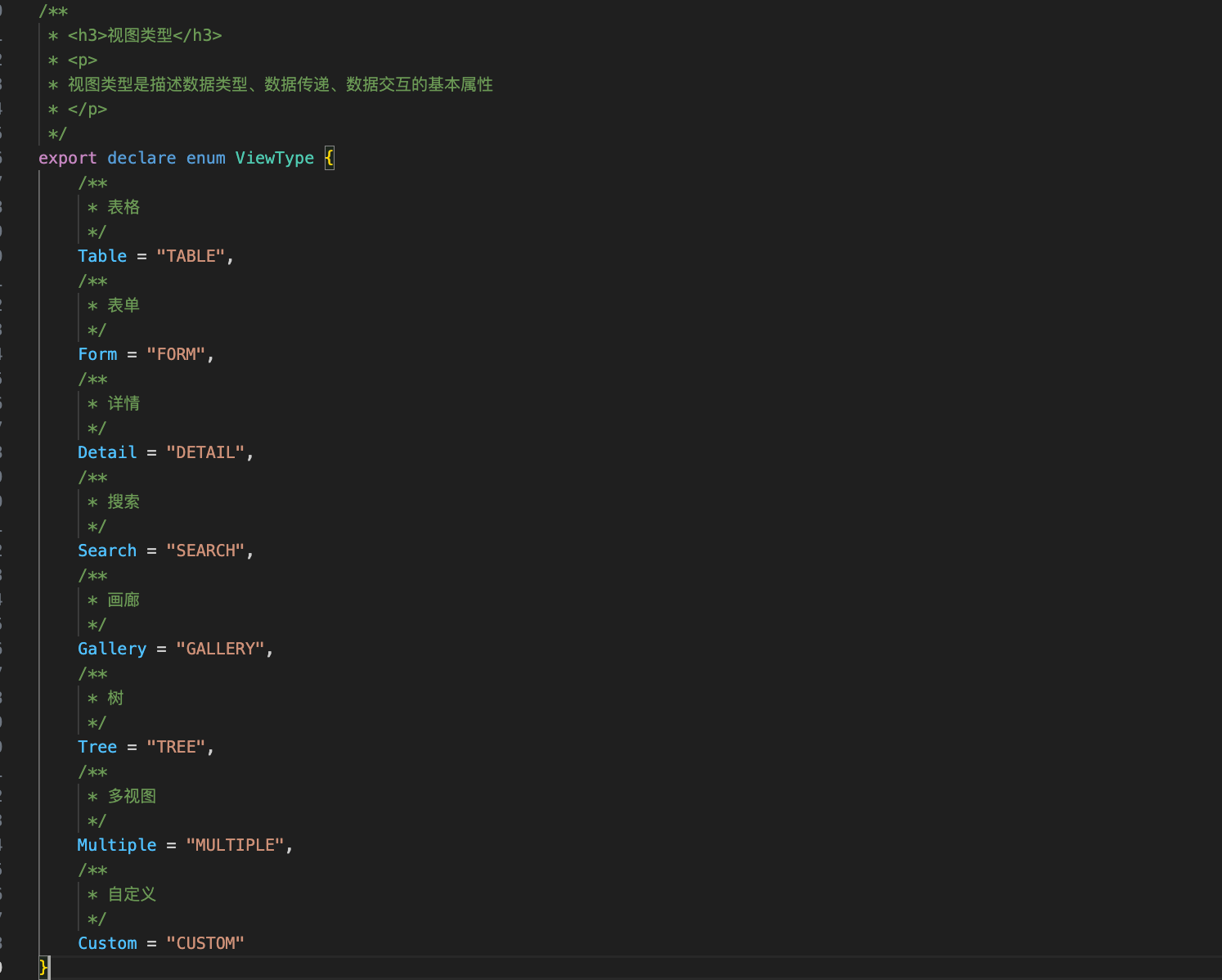
字段类型(ttype)
概念
在 Oinone 系统中,每个字段的数据类型都与后端的 ttype(类型)一一对应。这意味着每个前端字段类型都有其对应的后端数据类型。开发者可以根据这些 ttype 定义某类类型的组件,以便在前端实现对应类型的数据展示和交互
使用
在 Oinone 系统中,字段类型的前后端协议已经枚举了所有存在的业务类型,满足了多样化的业务场景需求。这些字段类型在前端是只读的,前端开发者只能查看,而不能定义和变更。
内置字段类型包括:
-
字符串(String)
-
文本(Text)
-
HTML
-
电话号码(Phone)
-
电子邮件(Email)
-
整数(Integer)
-
长整数(Long)
-
浮点数(Float)
-
货币(Currency)
-
日期时间(DateTime)
-
日期(Date)
-
时间(Time)
-
年份(Year)
-
布尔(Boolean)
-
枚举(Enum)
-
映射(Map)
-
关联(Related)
-
一对一(OneToOne)
-
一对多(OneToMany)
-
多对一(ManyToOne)
-
多对多(ManyToMany)
-
对象(Object)
这些内置字段类型涵盖了多种业务场景,同时在前端上的只读特性确保了数据类型的一致性和稳定性。
查找
- 每一个字段必然有ttype,选中字段查看对应的ttype
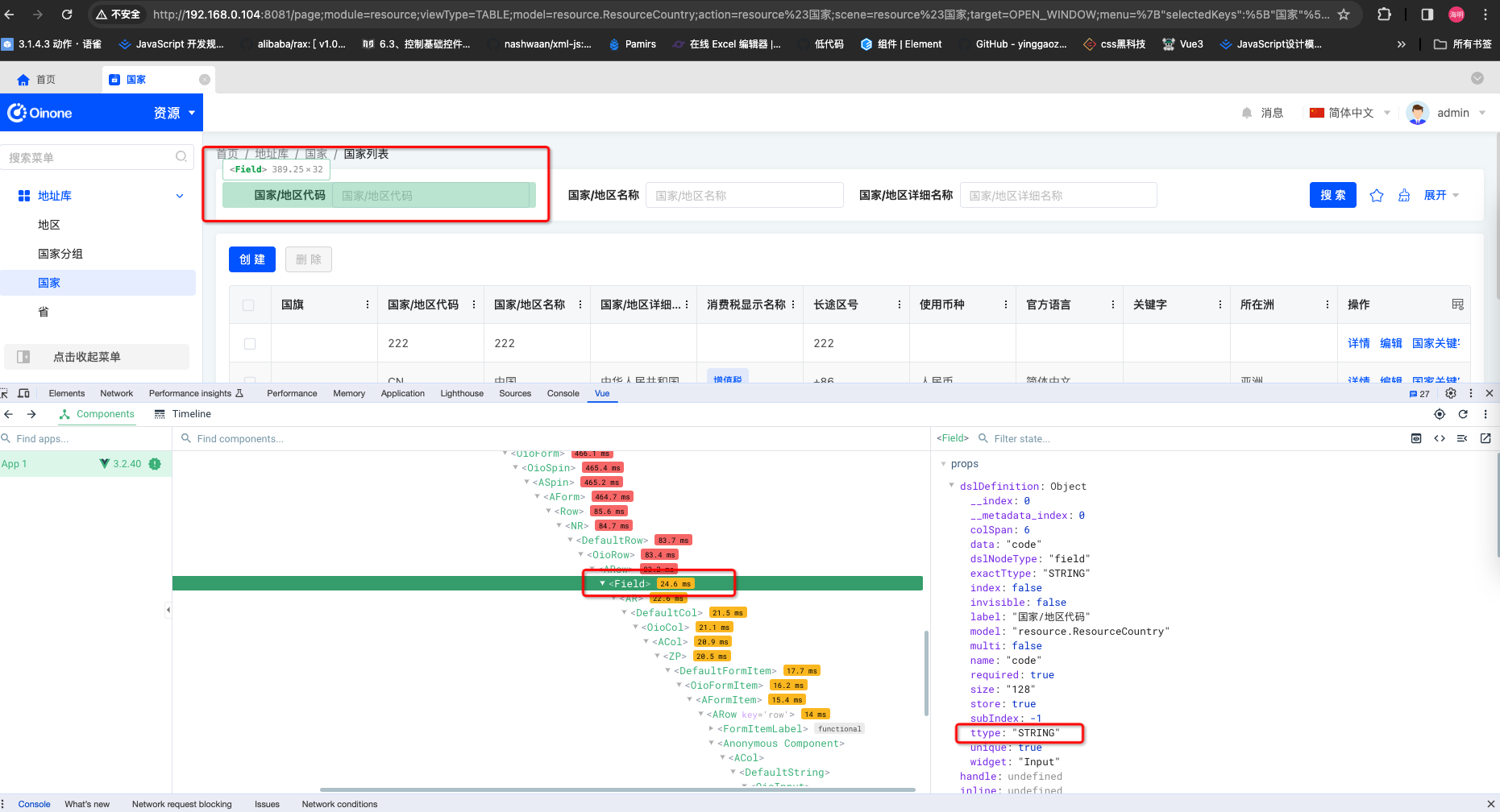
部件(widget)
概念
在 Oinone 系统中,widget 是字段组件的另一个筛选条件,可以被理解为组件的别名。当字段没有指定别名时,该组件将覆盖所有符合 ttype 和 viewType 条件的组件。widget 适用于在特定页面中定义组件的出现,提供了更灵活的定制能力。
使用
使用场景:
-
组件别名:widget 可以被视为字段组件的别名,用于在配置中标识和引用特定的组件。
-
条件筛选:通过 widget,可以在部分页面中定义组件的出现,而不影响其他页面的配置。
注意事项:
-
默认覆盖:当字段未指定 widget 时,该组件将覆盖所有符合 ttype 和 viewType 条件的组件。
-
页面定制:使用 widget,开发者可以更精细地定制组件在不同页面中的呈现方式。
通过合理使用 widget,系统提供了更加灵活和个性化的组件配置方式,使得不同页面可以呈现不同的组件。
查找
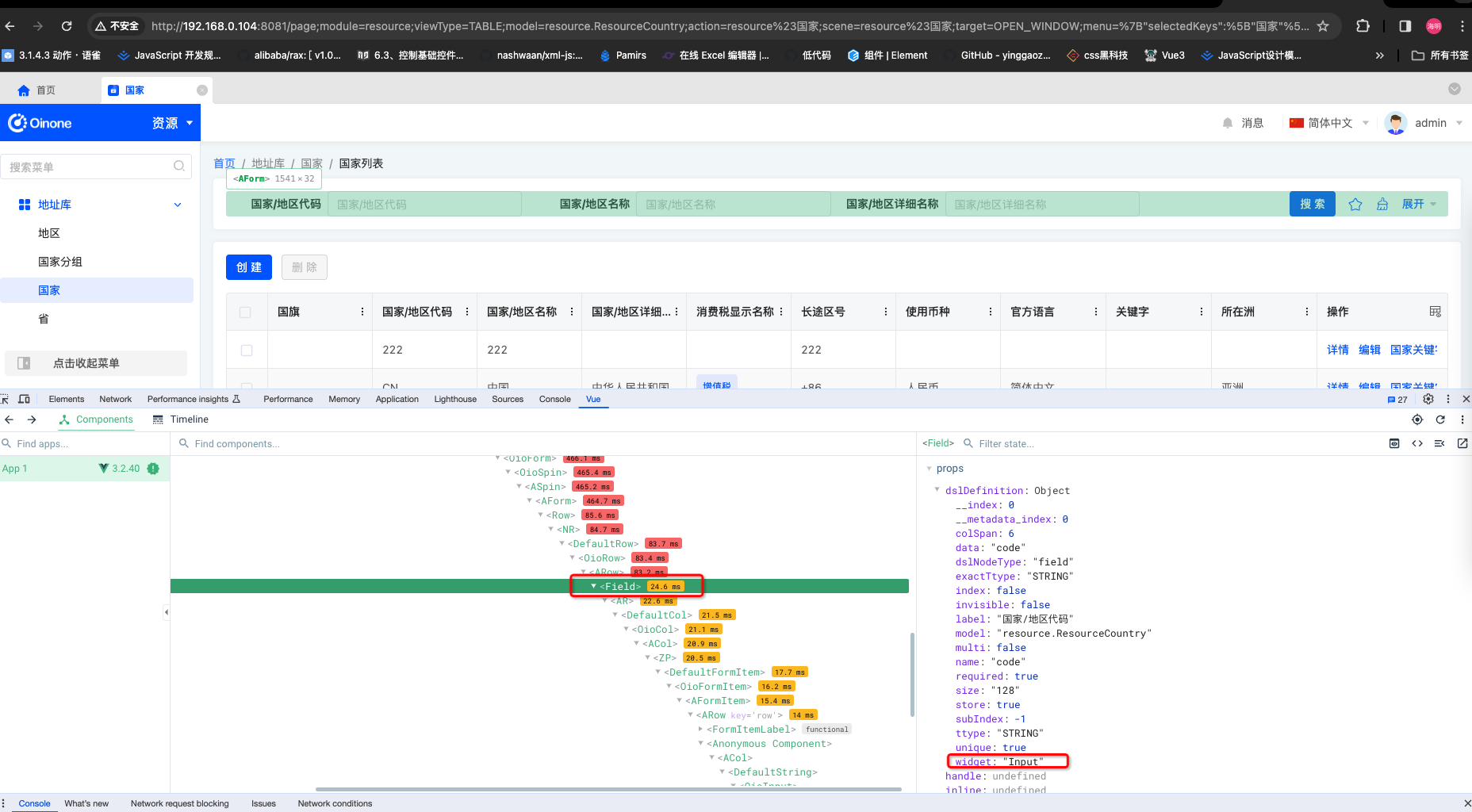
在 Oinone 系统中,用户可以选择查看当前字段对应的 widget。这个操作并非必选项,若未选择,系统将使用默认的字段渲染方式。然而,若用户选择了 widget,它必须与当前字段相同,以确保正确覆盖当前字段的渲染方式。
操作步骤:
-
选中字段:在字段配置界面,用户可以选择特定字段进行配置。
-
查看 Widget:用户可以查看当前字段对应的 widget,以了解当前字段的渲染方式。
-
非必选项:查看当前字段的 widget 是一个非必选项,用户可以选择使用默认的字段渲染方式。
-
Widget 一致性:如果用户选择了 widget,确保它与当前字段相同,以便正确覆盖当前字段的渲染方式。
通过这种设计,系统提供了灵活的字段配置选项,同时保证了渲染方式的一致性和准确性。
多值(multi)
概念
在 Oinone 系统中,multi 是字段的一个扩充选项,主要解决普通数据类型字段存储多个值的情况。举例来说,如果某个字段定义为 String 类型,后端存储的是单个图片的地址,而需要上传多张图片时,后端需要将该字段定义为 List<String> 类型。在前端,multi 允许将普通数据类型的 String 转换为 Array<String> 进行传输。
使用
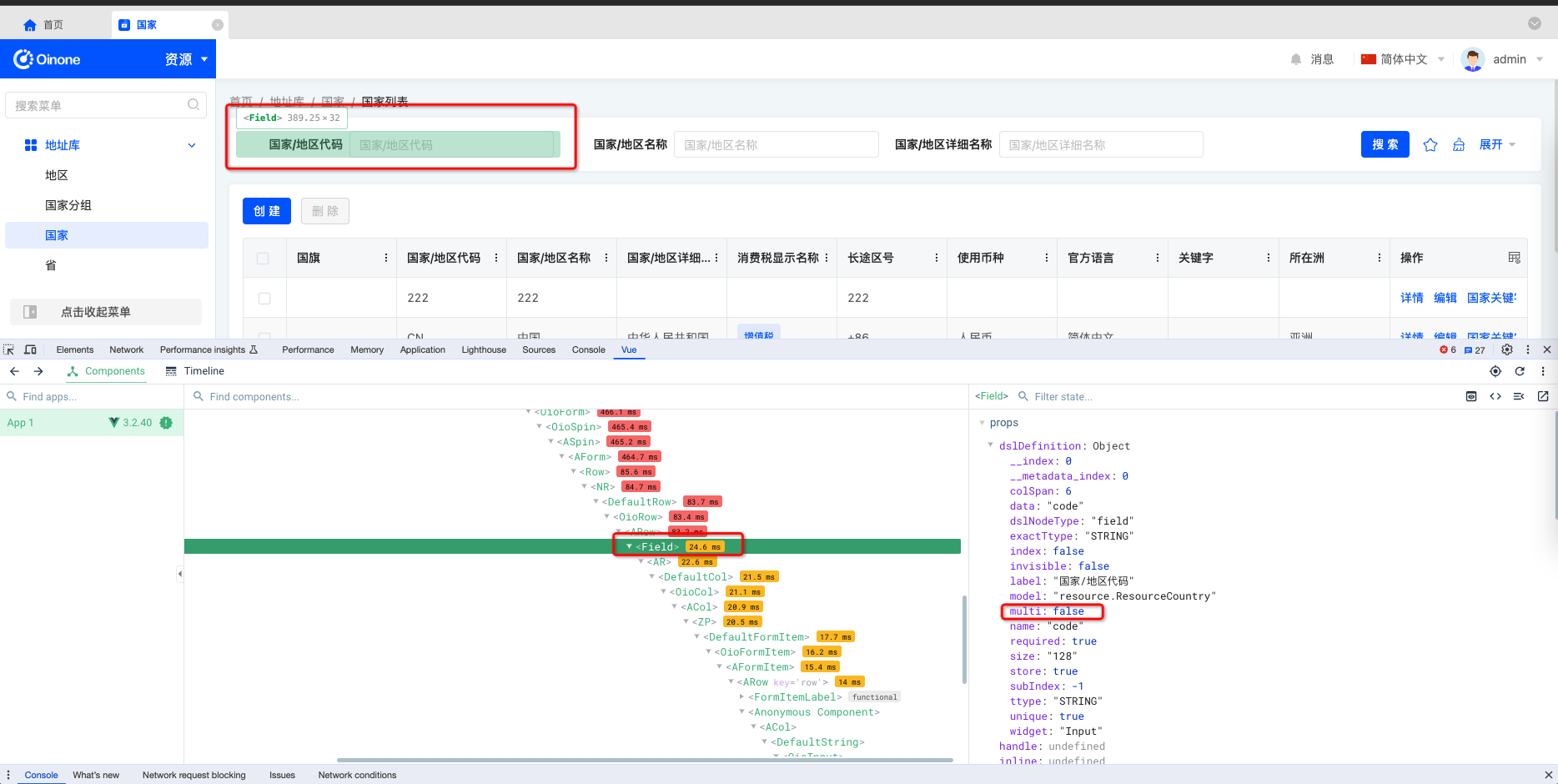
在 Oinone 系统中,前端使用时需要在字段注册上标记 multi。这个标记的取值(true 或 false)并非由前端决定,而是由后端在定义字段时确定的。前端只具有查看权限,无法变更这个标记。
操作步骤:
-
multi 标记:multi 标记表示该字段是否支持存储多个值,由后端在字段定义时决定,缺省时默认为false。
-
前端权限:前端只有查看权限,不能在字段注册时变更 multi标记的取值。
查找
- 每一个字段必然有multi,选中字段查看对应的multi,若没有声明,默认为false
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9264.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验