
一、基础介绍
当业务在线化后,用于内部管理的产品主数据,叠加一堆销售属性变成了商品被推倒了前台,成为导购链路中最最重要的信息载体。看似最基础和最简单的商品模块也有很多门道。主要集中在以下几个方面:
-
商品的属性如何管理、呈现、参与导购(类目、搜索的过滤条件)
-
如何解决固定不变的内部管理需求与基于销售特性长期变化的运营需求之间的矛盾
-
在多渠道情况渠道商品,如何映射到实际sku进行履约
二、模型介绍
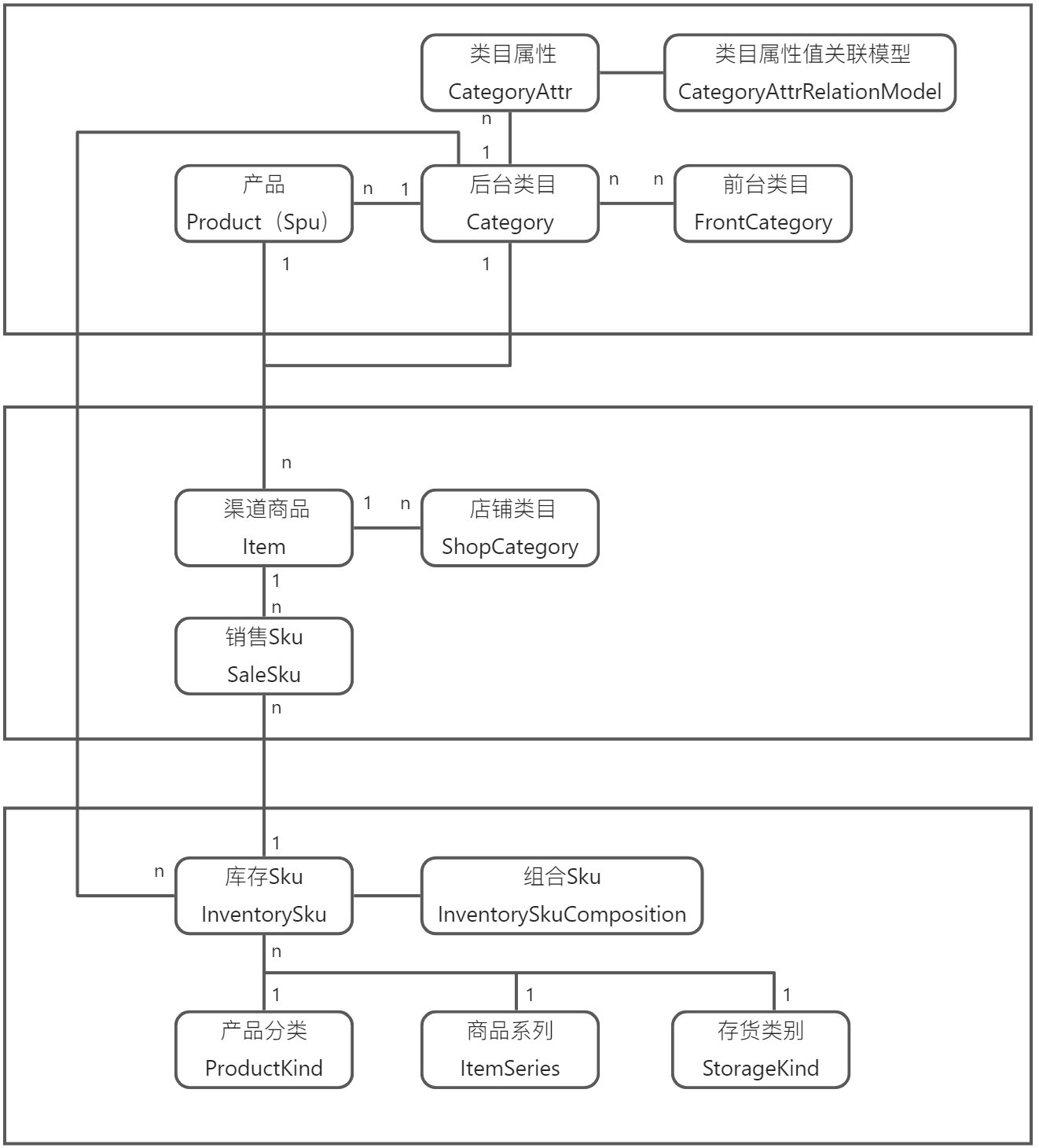

-
类目属性,解决“商品的属性如何管理、呈现、参与导购(类目、搜索的过滤条件)”
-
前后台类目设计,解决“如何解决固定不变的内部管理需求与基于销售特性长期变化的运营需求之间的矛盾”
-
销售Sku和库存Sku设计,解决“在多渠道情况渠道商品,如何映射到实际sku进行履约”
要把这些问题搞清楚,得先把名词统一下:
| 领域 | 名称 | oinone的定义 | 说明 | 举例 |
|---|---|---|---|---|
| 平台运营视角 | Spu | Product –>Spu2.1.9 –> 3.0.0 | SPU(Standard Product Unit):标准化产品单元。SPU是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性 | iPhone X可以确定一个产品 |
| 后台类目 | 后台类目(Category) | 商品分类分级管理,以及规范该类目下公共属性可以分为普通属性、销售属性 | 比如类目:3c数码/手机销售属性:内存大小、颜色等普通属性:分辨率 | |
| 前台类目 | 前台类目(FrontCategory) | 平台导购类目 | 通过前台类目关联后台类目或后台类目属性,用于满足运营需求 | |
| 大体上SPU处于最上层、Item属于下一级,而SKU属于最低一层。SPU是平台层面,Item是商家层面,SKU是商家的Item确定销售属性SPU非必须,在平台类交易中,平台方为了规范商家发布商品信息,进行统一运营时需要 | ||||
| 商家销售视角 | Item | 渠道商品(Item) | 简单来说是:SPU加上归属商家、以及商家自有的价格与描述 | 商家A的iPhone X |
| Sku | 销售Sku(SaleSku) | SKU=Stock Keeping Unit(库存保有单位)。是对每一个产品和服务的唯一标示符,该系统的使用SKU的值根于数据管理,使公司能够跟踪系统,如仓库和零售商店或产品的库存情况。 | iPhone X 64G 银色 则是一个SKU。 | |
| 店铺类目 | ShopCategory | 商家店铺导购类目 | 在平台类电商,商家都会有自己独立的店铺主页,商家类目跟前台类目作用类似,只是局限影响范围为商家店铺内 | |
| 销售SKU中会有一个InvSkuCode来关联InventorySku,比如:品牌上在不同渠道(淘宝、京东、自建电商)中会有不同的销售SKU,在从渠道同步销售SKU会根据外部code | ||||
| 商家管理视角 | 产品或库存Sku | InventorySku | 跟销售领域的sku的定义类似,但销售领域是为了规范购买行为,这里规范企业内部管理。 | iPhone X 64G 银色 |
| 组合Sku | InventorySkuComposition | 空调有内外机组合而成,这就是一个组合sku | ||
| 产品分类 | ProductKind | 企业内部管理划分 | ||
| 商品系列 | ItemSeries | 指互相关联或相似的产品,是按照一定的分类标准对企业生产经营的全部产品进行划分的结果。一个产品系列内往往包括多个产品项目。产品系列的划分标准有产品功能、消费上的连带性、面向的顾客群、分销渠道、价格范围等 | ||
| 存货类别 | StorageKind | 为了反映存货的组成内容,正确计算产品的生产成本以及销售成本,会计上必须对存货进行科学地分类,按存货的不同类别进行核算 |
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9321.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验