
在4.1.13【Action之校验】、3.4.1【构建第一个Function】等文章中,都用到PamirsSession.getMessageHub()来设置返回消息,基本上都是在传递后端逻辑判断的异常信息,而且在系统报错时也会通过它来返回错误信息,前端接收到错误信息则会以提示框的方式进行错误提示。其实后端除了可以返回错误信息以外,还可以返回调试、告警、成功、信息等级别的信息给前端。但是默认情况下前端只提示错误信息,可以通过前端的统一配置放开提示级别,有点类似后端的日志级别。
一、不同信息类型的举例
Step1 新建PetTypeAction
借用PetType模型的表格页做为信息传递的测试入口,为PetType模型新增一个ServerAction,在代码中对信息的所有类型进行模拟
package pro.shushi.pamirs.demo.core.action;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.PetCatItem;
import pro.shushi.pamirs.demo.api.model.PetType;
import pro.shushi.pamirs.meta.annotation.Action;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.api.dto.common.Message;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.meta.enmu.ActionContextTypeEnum;
import pro.shushi.pamirs.meta.enmu.InformationLevelEnum;
import pro.shushi.pamirs.meta.enmu.ViewTypeEnum;
@Model.model(PetType.MODEL_MODEL)
@Component
public class PetTypeAction {
@Action(displayName = "消息",bindingType = ViewTypeEnum.TABLE,contextType = ActionContextTypeEnum.CONTEXT_FREE)
public PetType message(PetType data){
PamirsSession.getMessageHub().info("info1");
PamirsSession.getMessageHub().info("info2");
PamirsSession.getMessageHub().error("error1");
PamirsSession.getMessageHub().error("error2");
PamirsSession.getMessageHub().msg(new Message().msg("success1").setLevel(InformationLevelEnum.SUCCESS));
PamirsSession.getMessageHub().msg(new Message().msg("success2").setLevel(InformationLevelEnum.SUCCESS));
PamirsSession.getMessageHub().msg(new Message().msg("debug1").setLevel(InformationLevelEnum.DEBUG));
PamirsSession.getMessageHub().msg(new Message().msg("debug2").setLevel(InformationLevelEnum.DEBUG));
PamirsSession.getMessageHub().msg(new Message().msg("warn1").setLevel(InformationLevelEnum.WARN));
PamirsSession.getMessageHub().msg(new Message().msg("warn2").setLevel(InformationLevelEnum.WARN));
return data;
}
}Step2 (前端)修改提示级别
在项目初始化时使用CLI构建初始化前端工程,在src/middleware有拦截器的默认实现,修改信息提示的默认级别为【ILevel.SUCCESS】
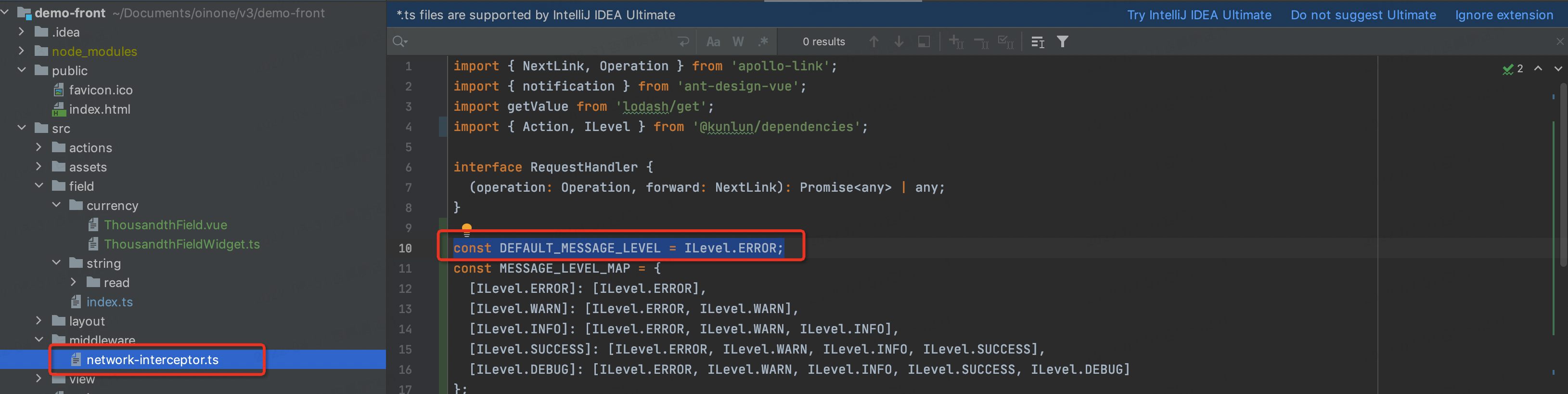

const DEFAULT_MESSAGE_LEVEL = ILevel.SUCCESS;图4-1-23-3(前端)修改提示级别
Step3 重启系统看效果
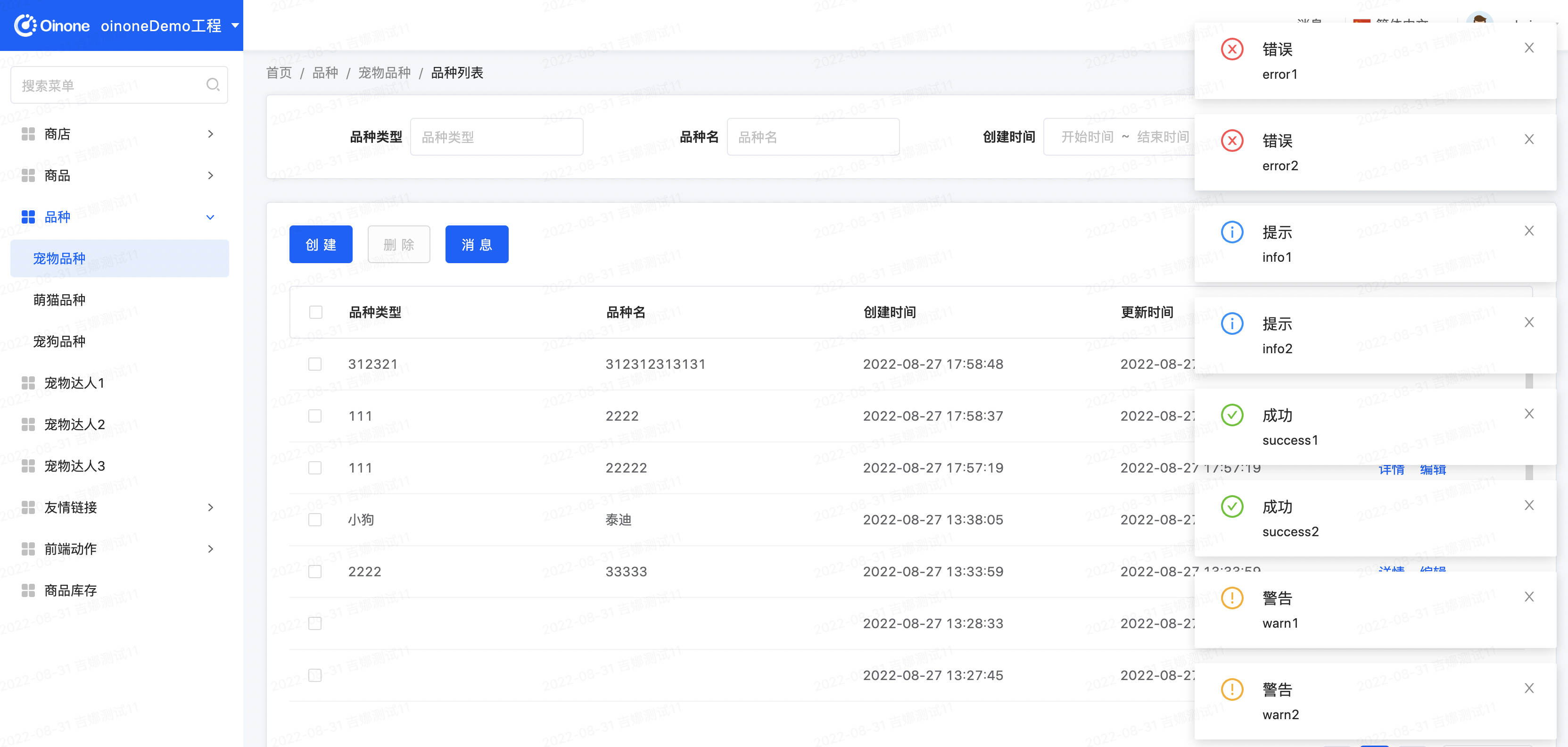
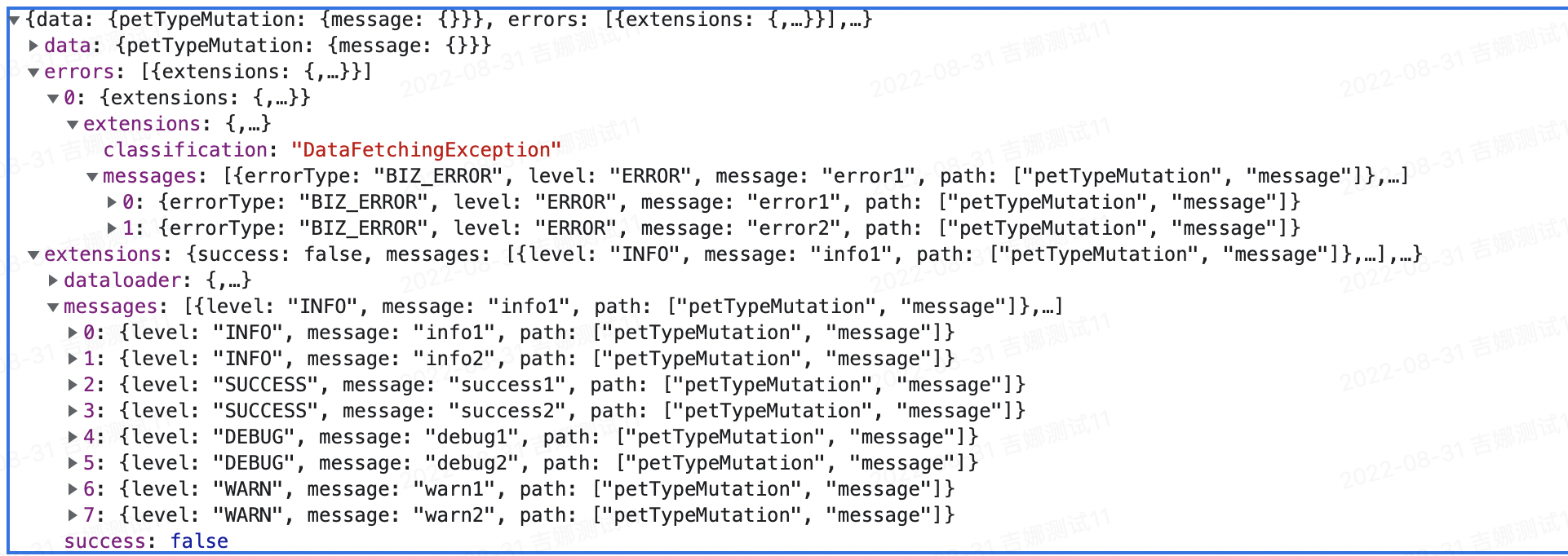
从页面效果中看到已经不在是只提示错误信息。从协议端看错误级别的信息是在errors下,其他级别的信息是在extensions下。
二、MessageHub的其他说明
是实现上看MessageHub是基于GQL协议,前后端都有配套实现。同时前端还提供了订阅MessageHub的信息功能,以满足前端更多交互要求,前端MessageHub提供的订阅能力使用教程详见4.2.2前端高级特性之【框架之MessageHub】一文。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9298.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验