
场景说明
场景描述:全员营销标准产品的功能并未有任务发放的审批流,在实际执行中,当营销专员配置好任务后,需部门领导对整个活动如该任务内容、形式、参与人员进行审批。
业务需求:在发布任务这个流程中增加审批节点。
实战训练
Step1 原业务分析
- 点击菜单【任务中心】通过URL上的model参数找到对应模型编码为【gemini.biz.GeminiTaskProxy】

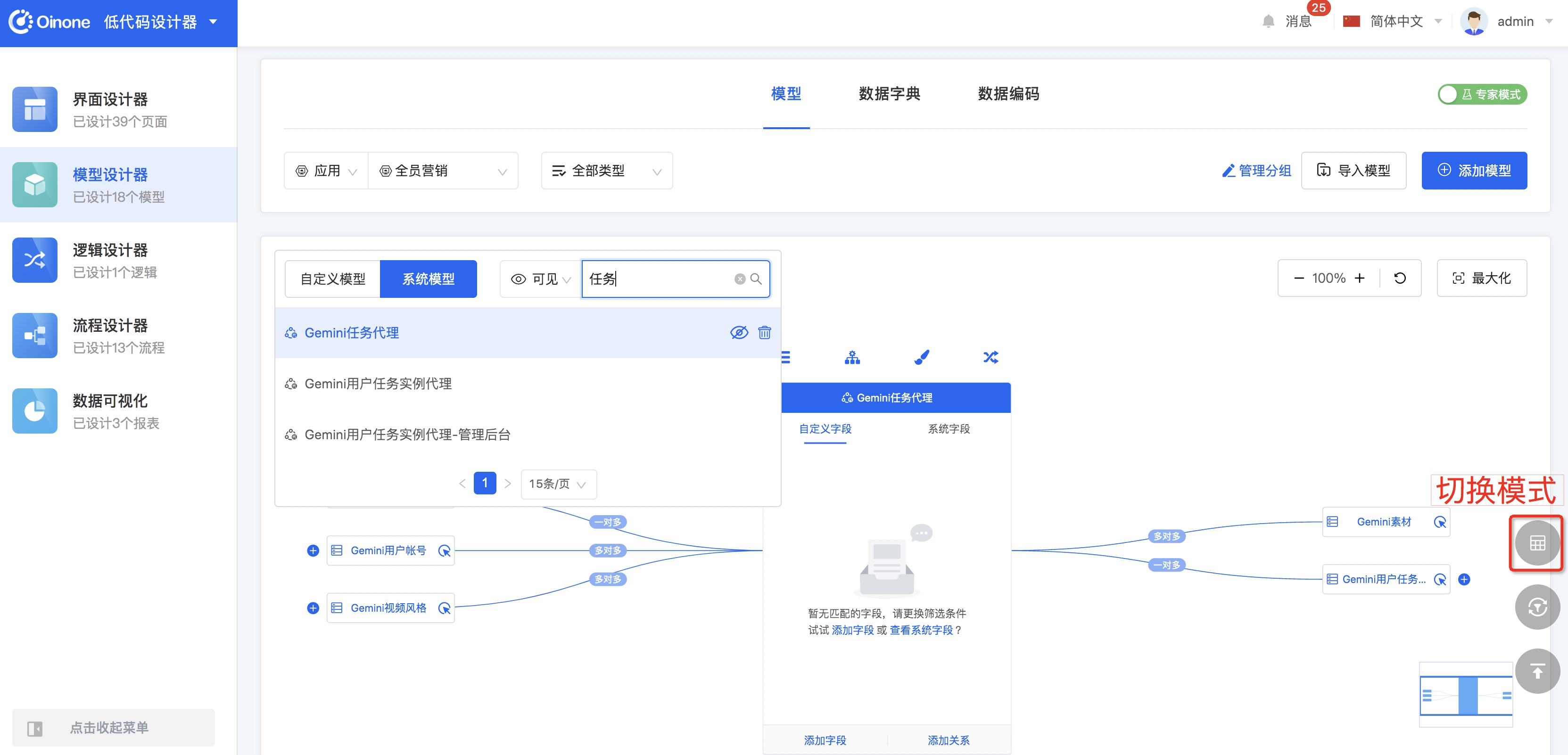
- 进入模型设计器主页面,应用选择【全员营销】、选择【系统模型】、通过搜索关键字【任务】选择【Gemini任务代理】,展示方式从图模式切换到表单模式,对比【模型编码】
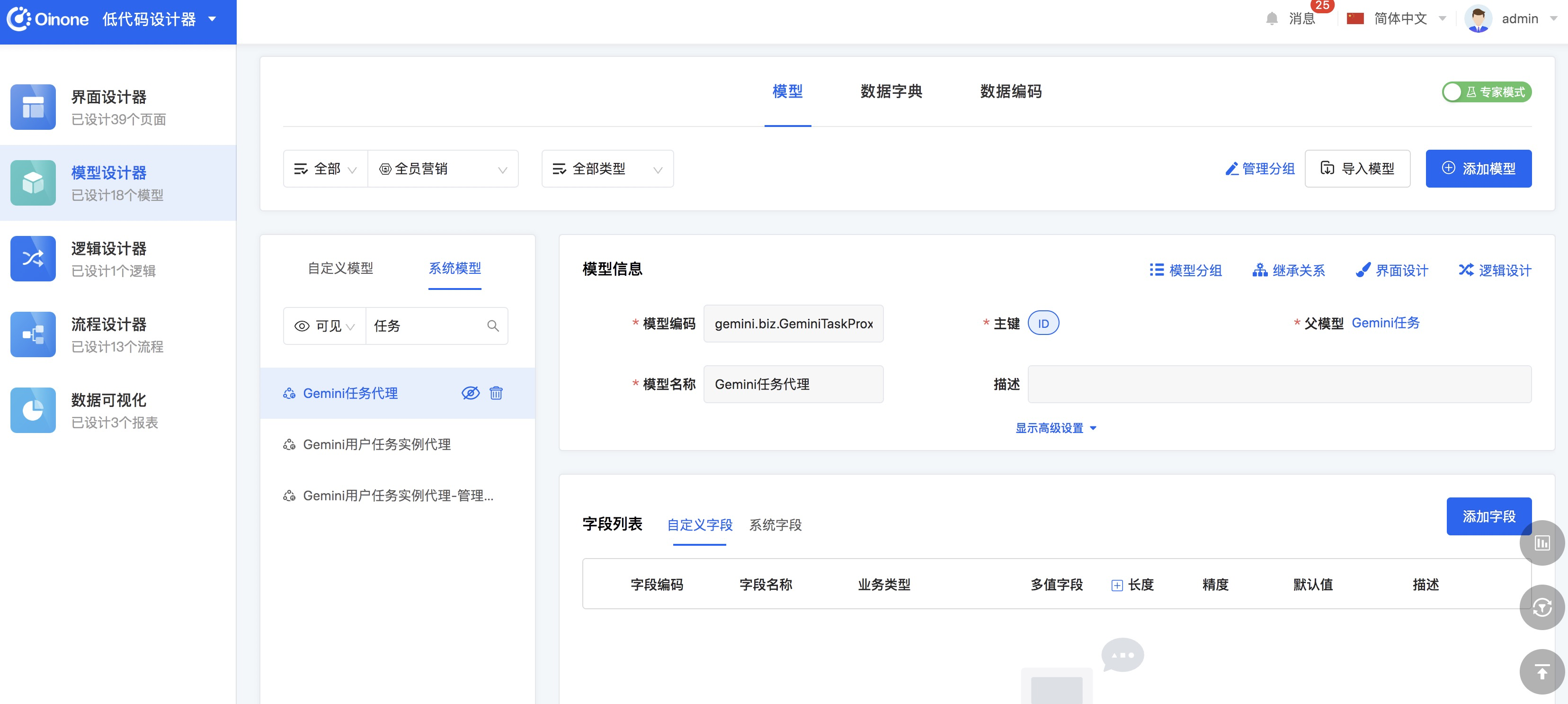
-
但目前模型为代理模型,代理模型是用于代理存储模型的数据管理器能力,同时又可以扩展出非存储数据信息的交互功能的模型。因为在代理模型中新增的字段都是非存储字段,所以如果要增加【审核状态】的字段一定以要在存储模型增加。其父模型的查看有两种方式
-
表单模式下可以直接看父模型
-
在图模式和表单模式下点击继承关系
-

- 点击【Gemini任务】,进入【Gemini任务】的模型设计界面,可以看出该模型所在模块为【全员营销核心业务】,从【系统字段】中找到【任务状态】字段,点击查看字段详情,我们可以看到【业务类型】为数据字典,字典类型为【任务状态】。
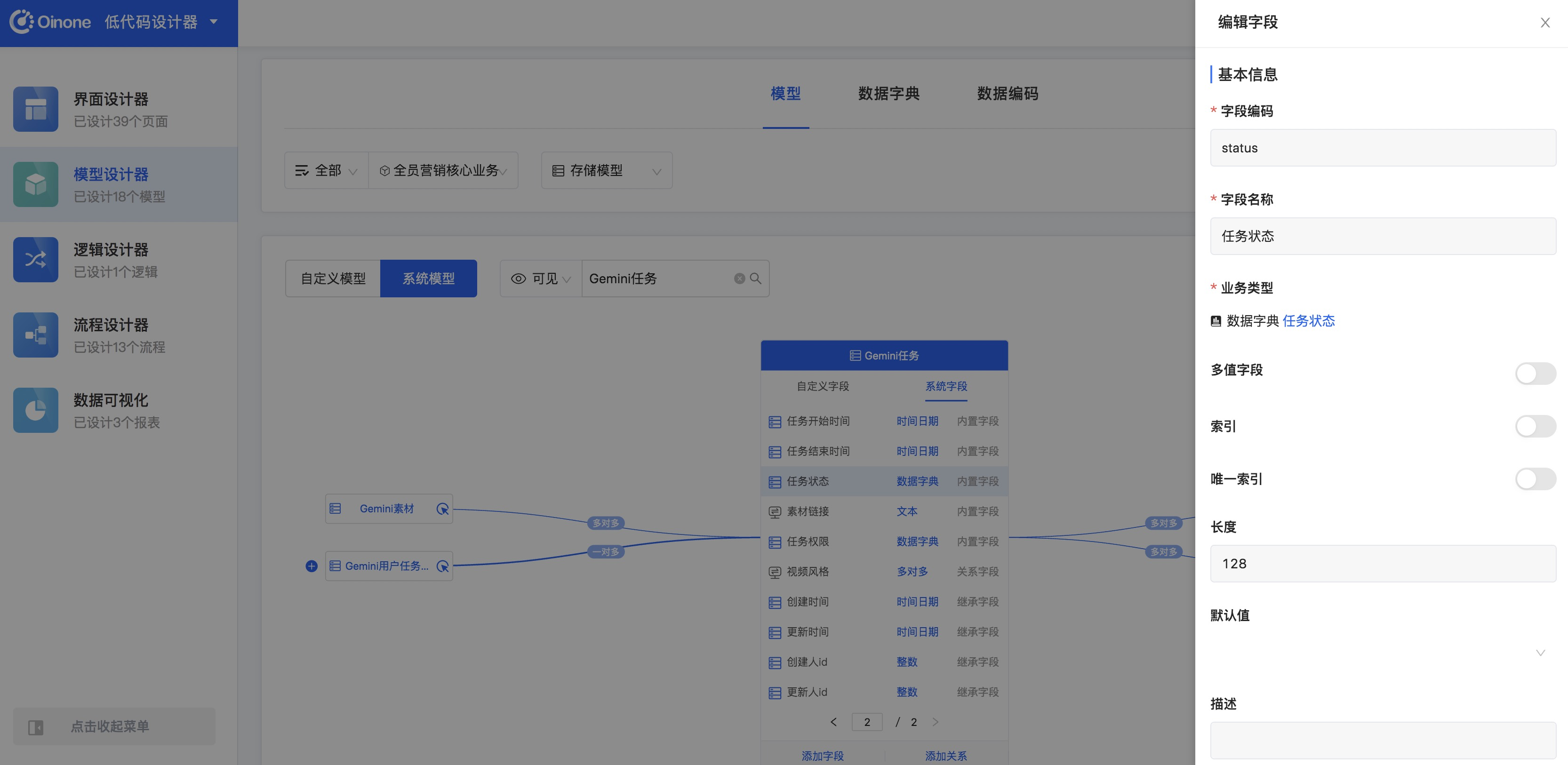
- 在模型设计器的管理页面上方点击【数字字典】选项卡,模块选择为【全员营销核心业务】,选择【系统字典】就可以查看到【任务状态】数字字典

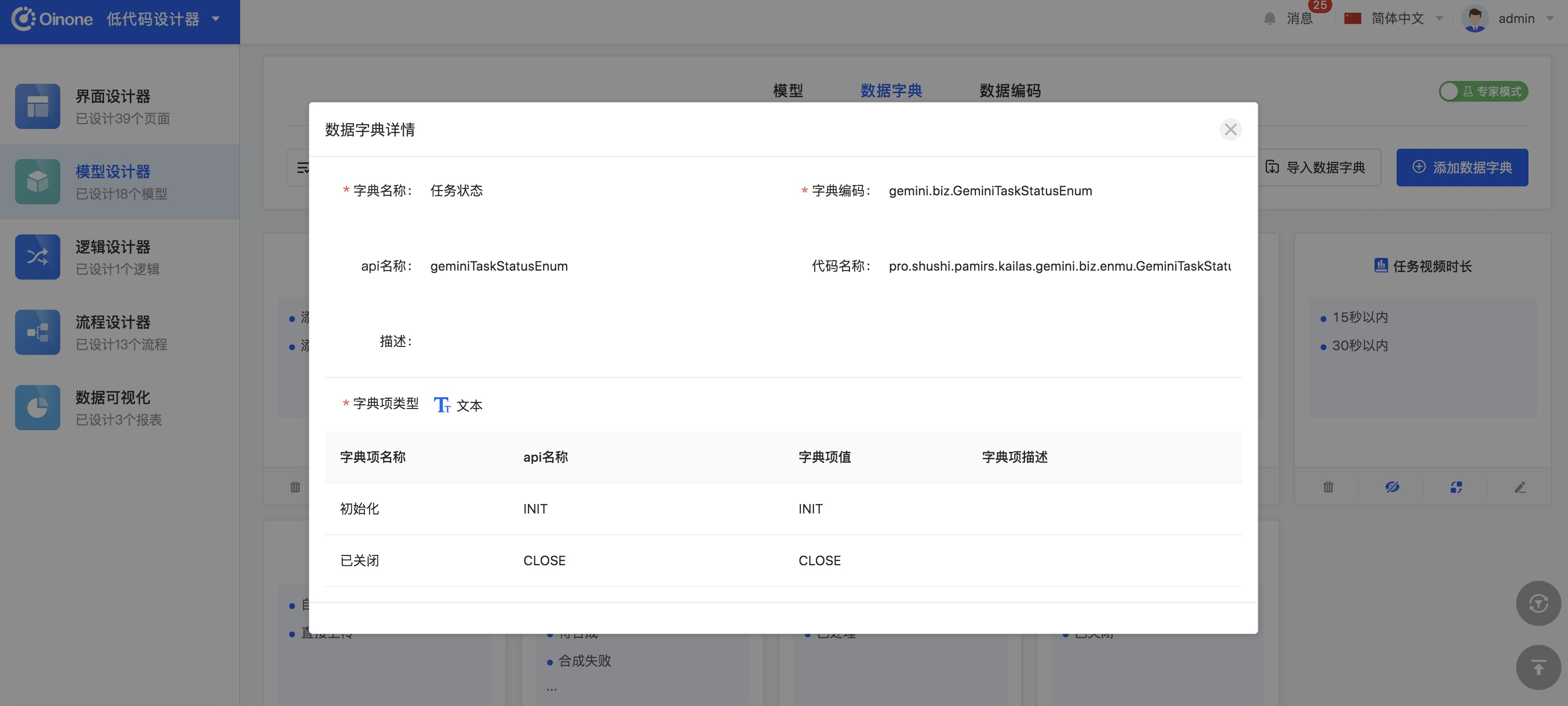
-
总结如下:
-
给【Gemini任务】模型增加一个【任务审批状态】,记录审批状态
-
在任务创建的时候,修改【任务状态】为【关闭】确保任务未审批通过的时,用户无法操作该任务。
-
审批通过后,恢复【任务状态】为【初始化】
-
我们先来整理下核心流程即:任务审批流程。
-
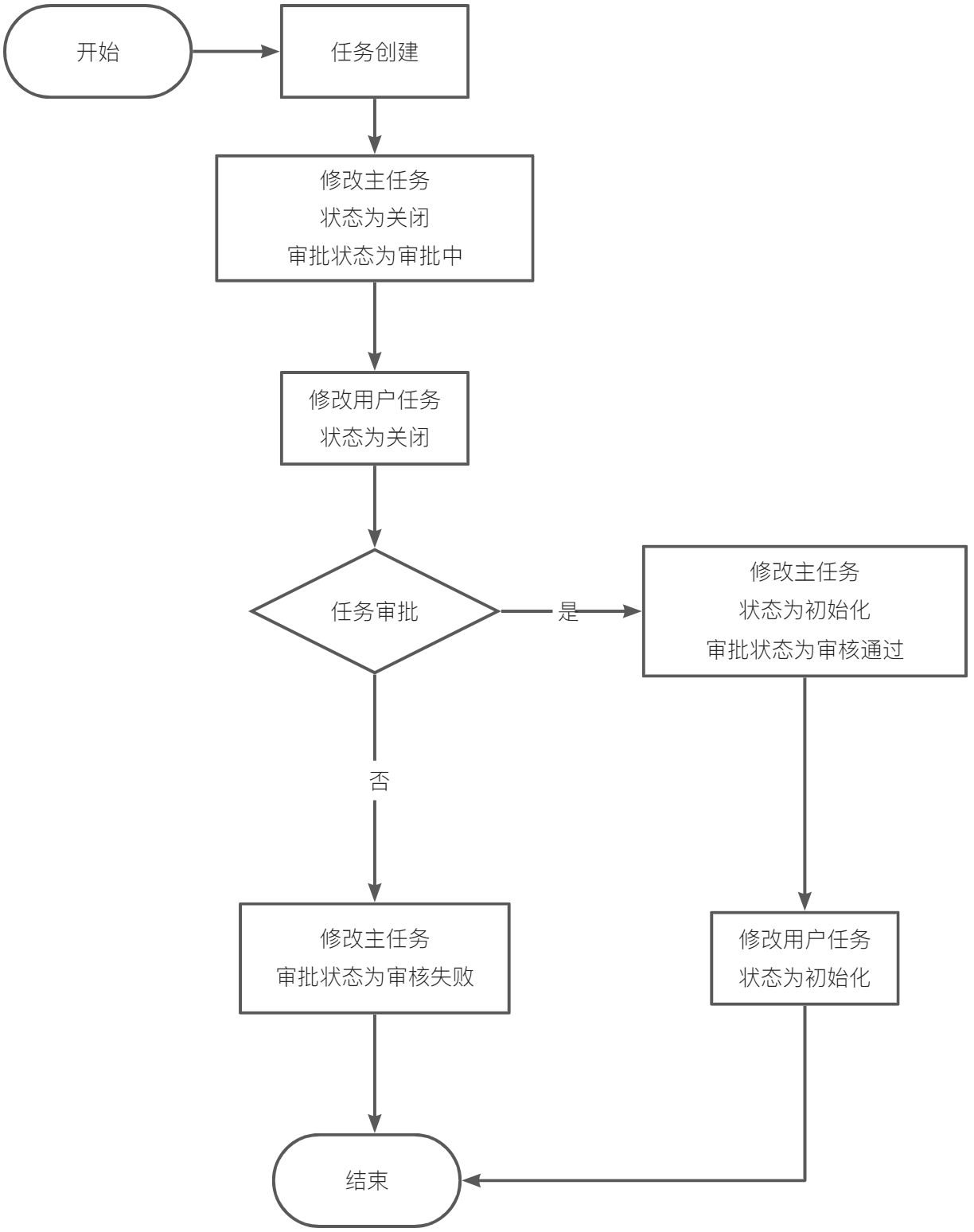
Step2 利用模型设计器设计模型
-
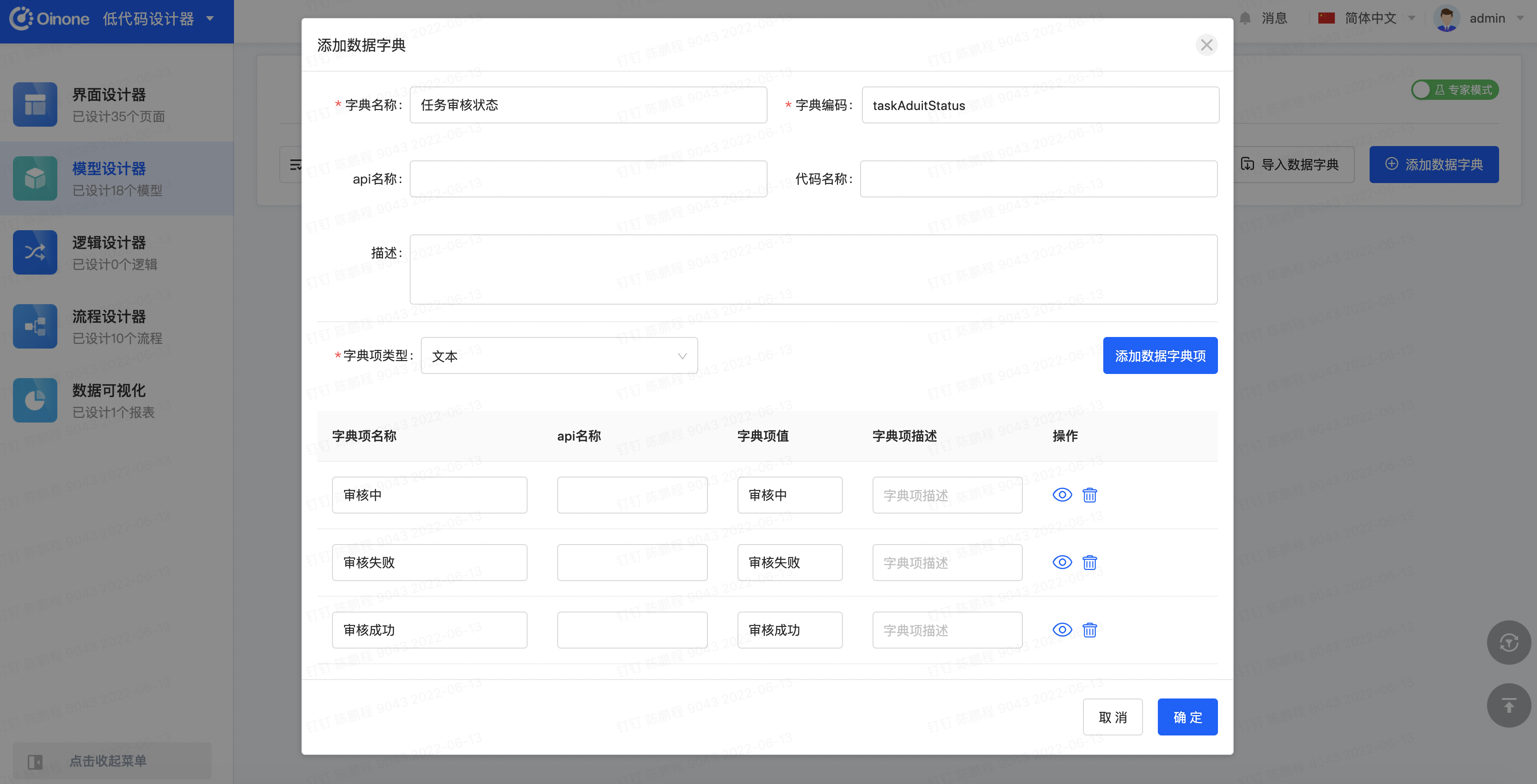
在模型设计器的管理页面上方点击【数字字典】选项卡,模块选择为【全员营销核心业务】,点击添加【数据字典】按钮,设置对应数据项
-
设置【字典名称】为【审批状态】
-
设置【字典项类型】为【文本】
-
通过【添加数据字典项】按钮增加对应数据字典项,如审核中、审核失败、审核成功
-
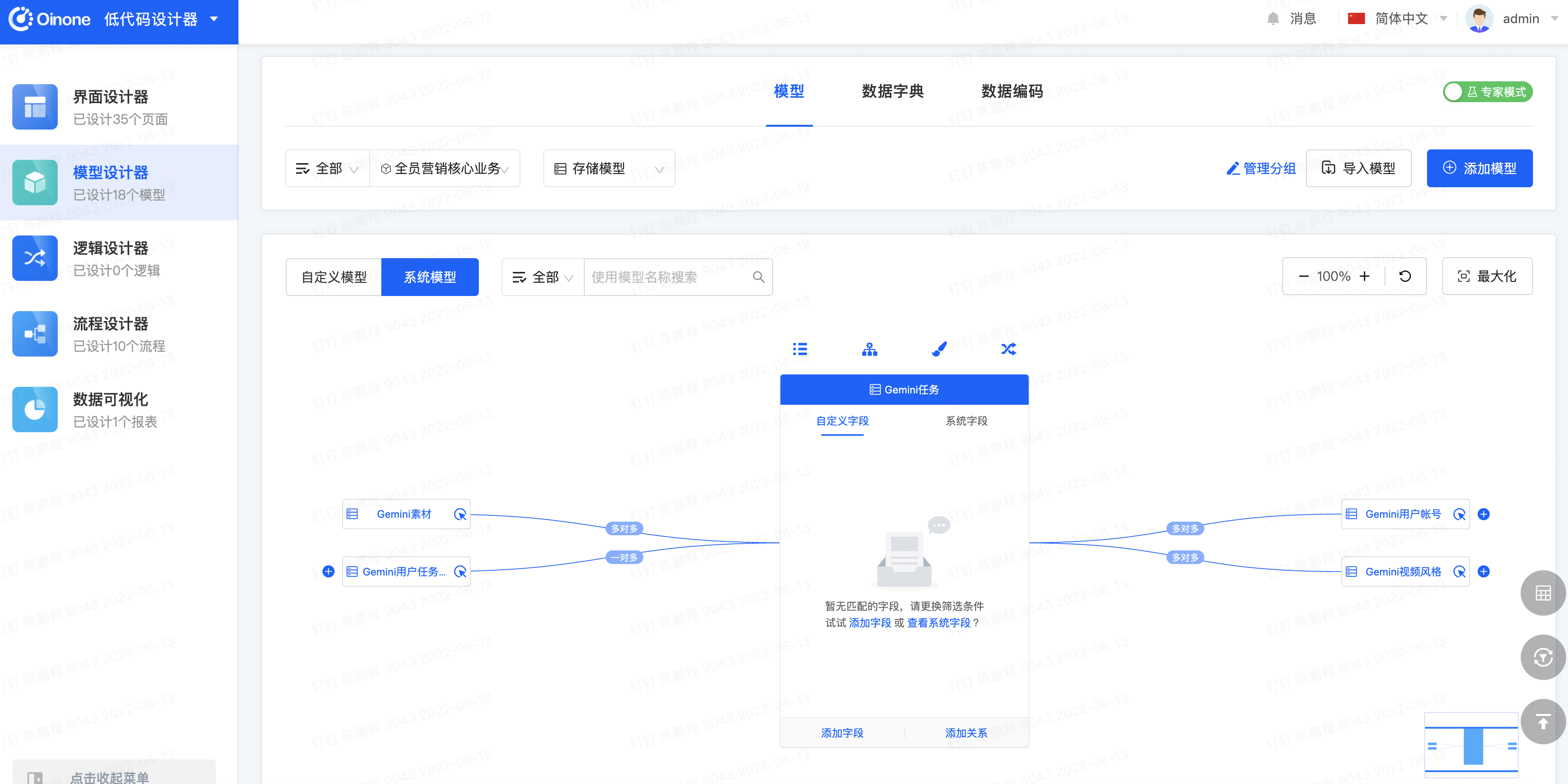
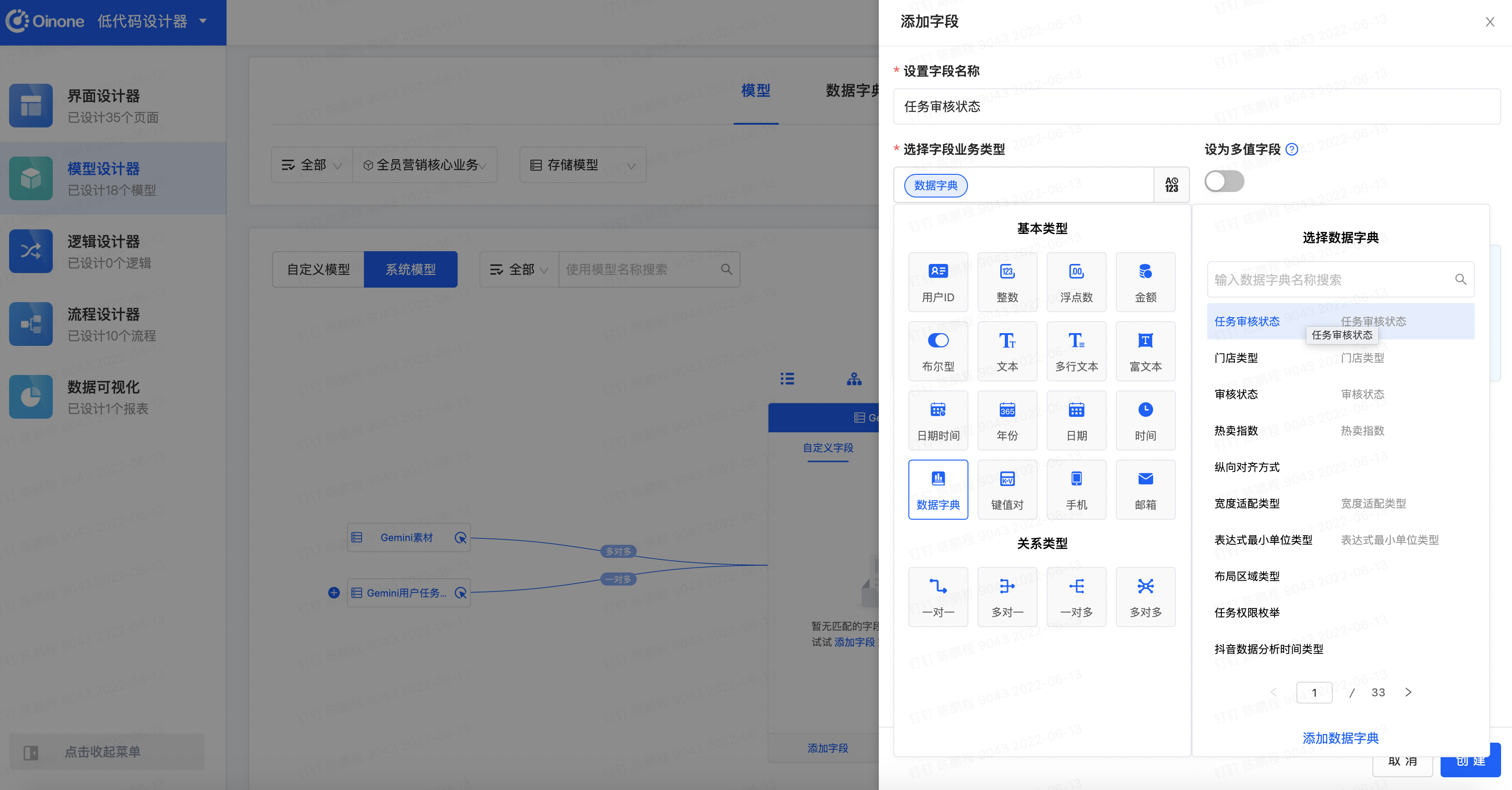
- 在模型设计器的管理页面上方点击【模型】选项卡,模块选择为【全员营销核心业务】,选择【系统模型】、搜索任务选择【Gemini任务】,点击添加字段
-
为模型【Gemini任务】添加字段
-
设置【字段名称】为【任务审批状态】
-
设置【字段业务类型】为数据字典,并选择关联数据字典为【任务审批状态】
-
最后点击【创建】按钮完成操作
-
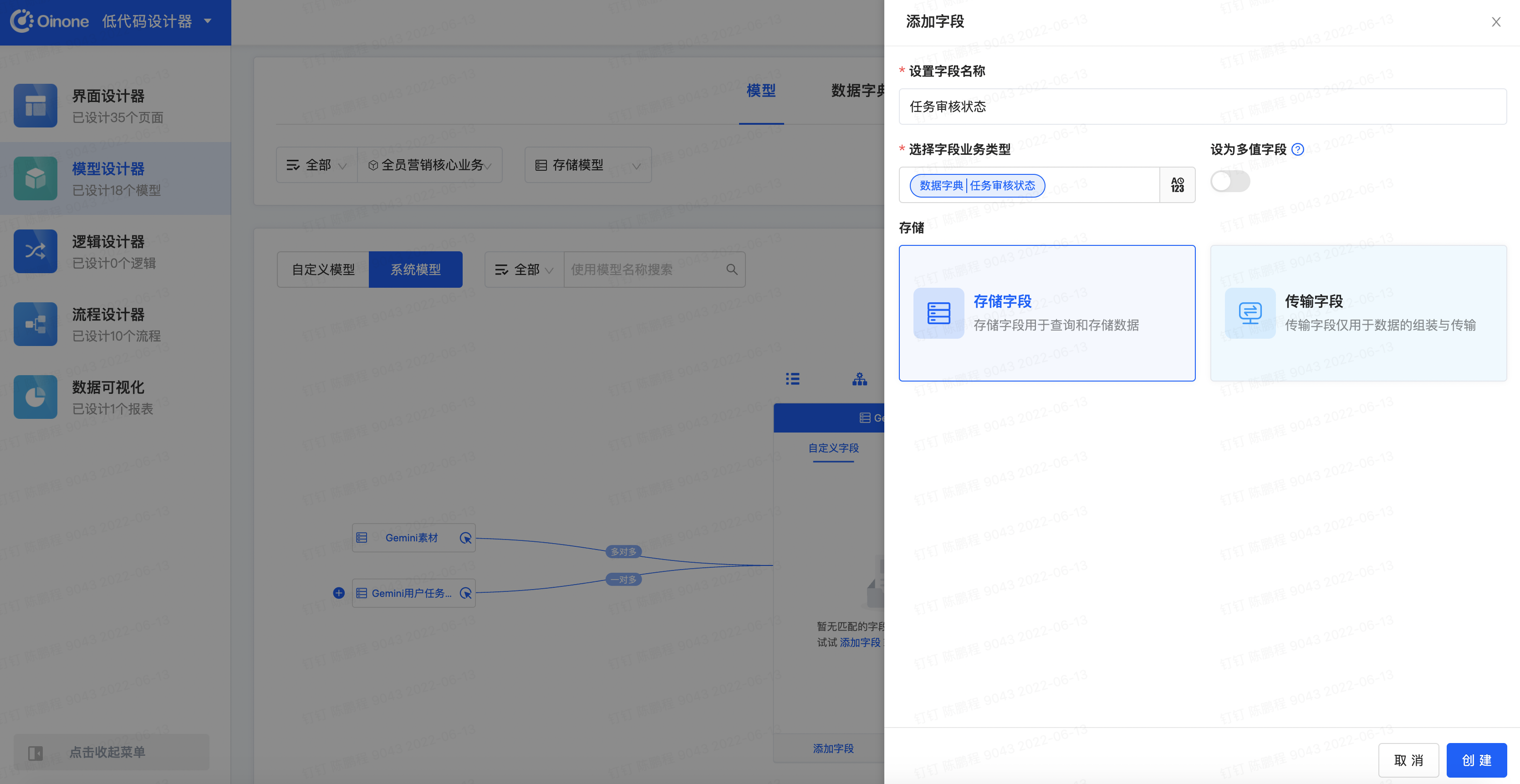
- 回到【Gemini任务】设计区,我们可以看到在模型的【自定义字段】选项卡下方多了一个【任务审批状态】字段

Step3 利用界面设计器,设计出必要的审核页面
-
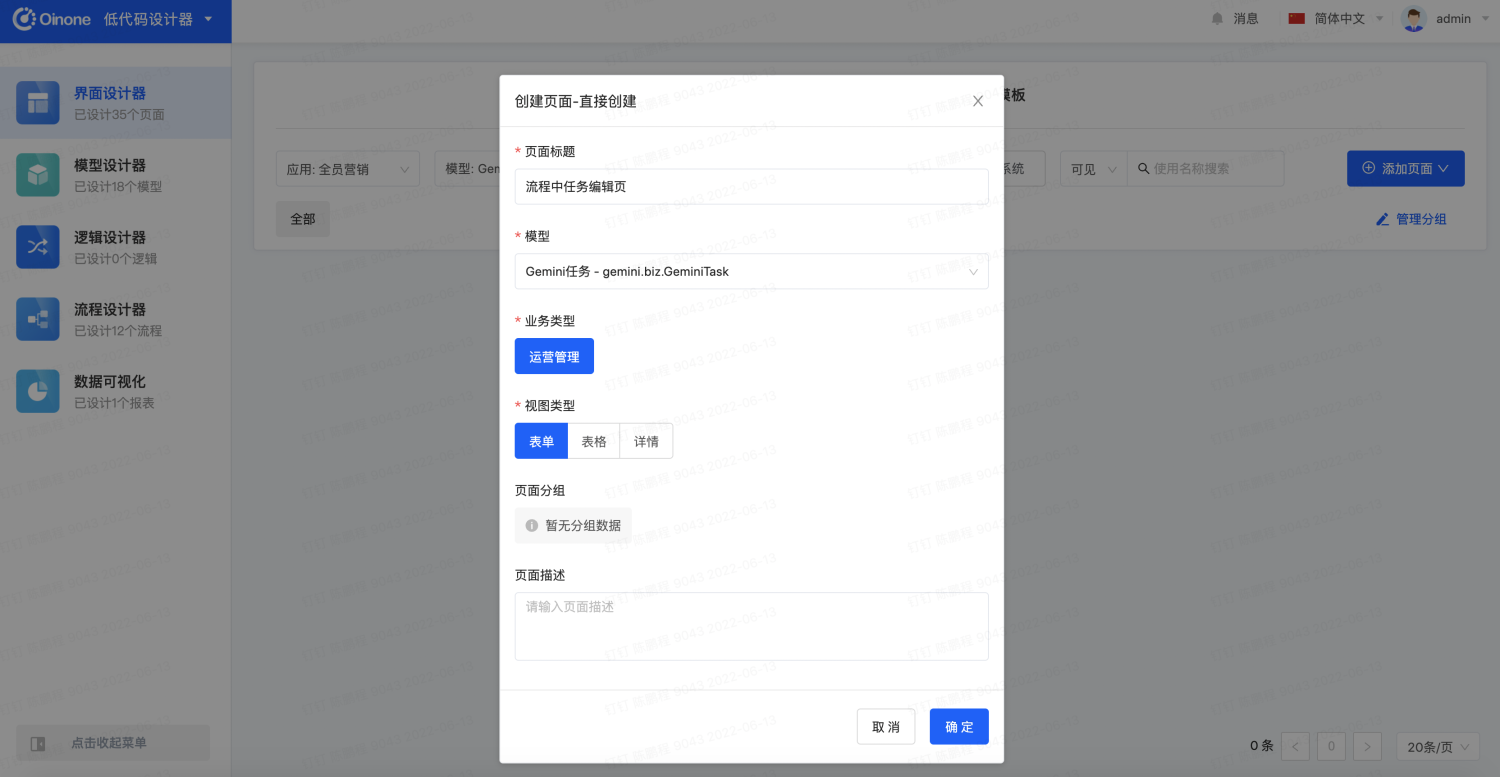
进入界面设计器,应用选择全员营销,模型选择【Gemini任务】,点击添加页面下的直接创建
-
设置页面标题、模型(自动带上可切换)、业务类型(运营管理后续会扩展其他类型)、视图类型(表单)后点击确认按钮进入【Gemini任务】表单设计页面
-
进入页面设计器,对【Gemini任务】表单页面进行设计(更多细节介绍,请参考界面设计产品使用手册)
-
左侧为物料区:分为组件、模型。
-
【组件】选项卡下为通用物料区,我们可以为页面增加对应布局、字段(如同在模型设计器增加字段)、动作、数据、多媒体等等
-
【模型】选项卡下为页面对应模型的自定义字段、系统字段、以及模型已有动作
-
-
中间是设计区域
-
右侧为属性面板,在设计区域选择中组件会显示对应组件的可配置参数
-
-
在左侧【组件】选项卡下,拖入布局组件【分组】,并设置组件【标题属性】为基础信息
-
在左侧【模型】选项卡下,分别系统字段中的【任务标题】、【任务开始时间】、【任务结束时间】、【视频标题】、【视频风格】、【任务描述】拖入【基础信息】分组,并点击【任务描述】,在右侧属性面板的【交互】分组中设置宽度为1。最后别忘了点击【发布】按钮完成页面的发布

Step4 通过流程设计器,设计对应业务流程
- 进入流程设计器,点击【创建】按钮
注意:流程中需要获取【关系字段】的除关联字段(一般为ID)以外的字段需要通过【数据获取】节点单独获取【关系字段】的对象数据。所以在流程设计中经常会用到【数据获取】节点

- 左上角编辑流程名称为【任务审批流程】,点击第一个【触发】节点,触发方式选择模型触发,模型选择【Gemini任务】,触发场景选择【新增或更新数据时】,【筛选条件】设置为【任务审批状态】为空或【任务审批状态】等于【审核中】,点击该节点的【保存】按钮
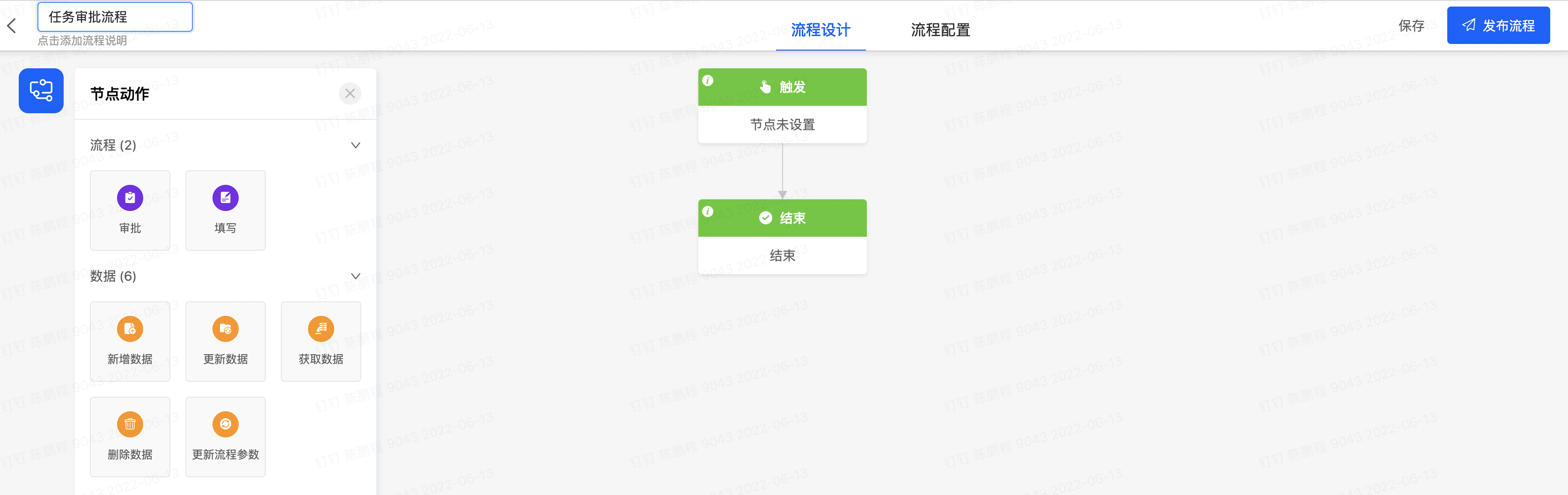

- 点击流程图节点间的【+】图标选择增加【获取数据】节点,或者拖动左侧物料区【获取数据】到特定的【+】图标
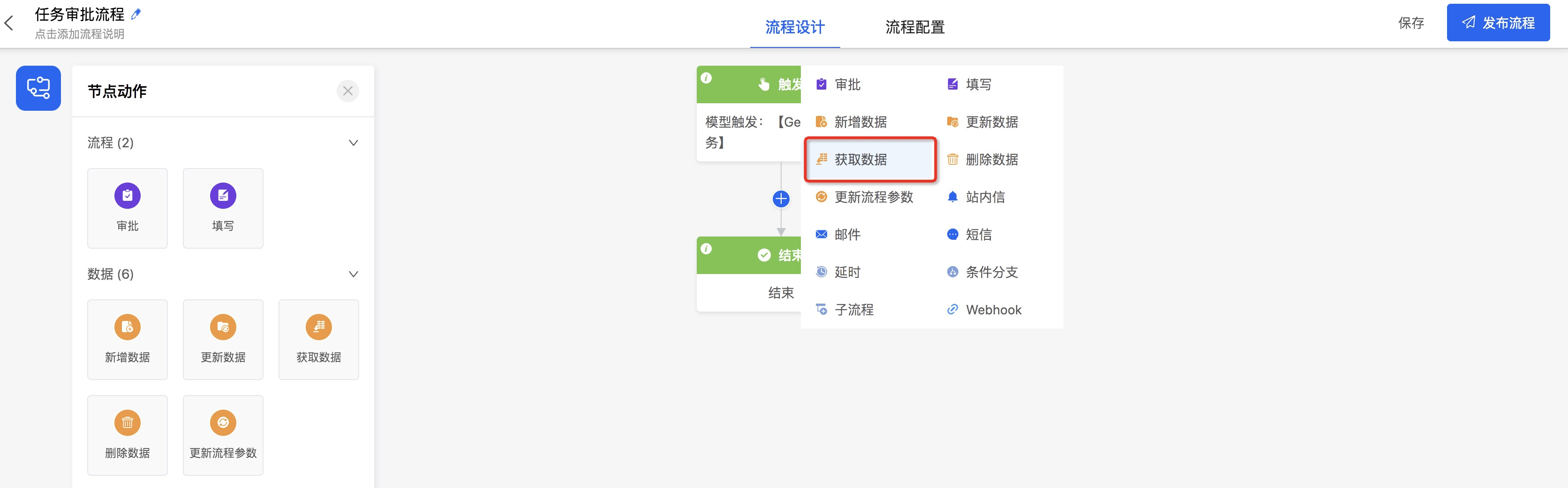
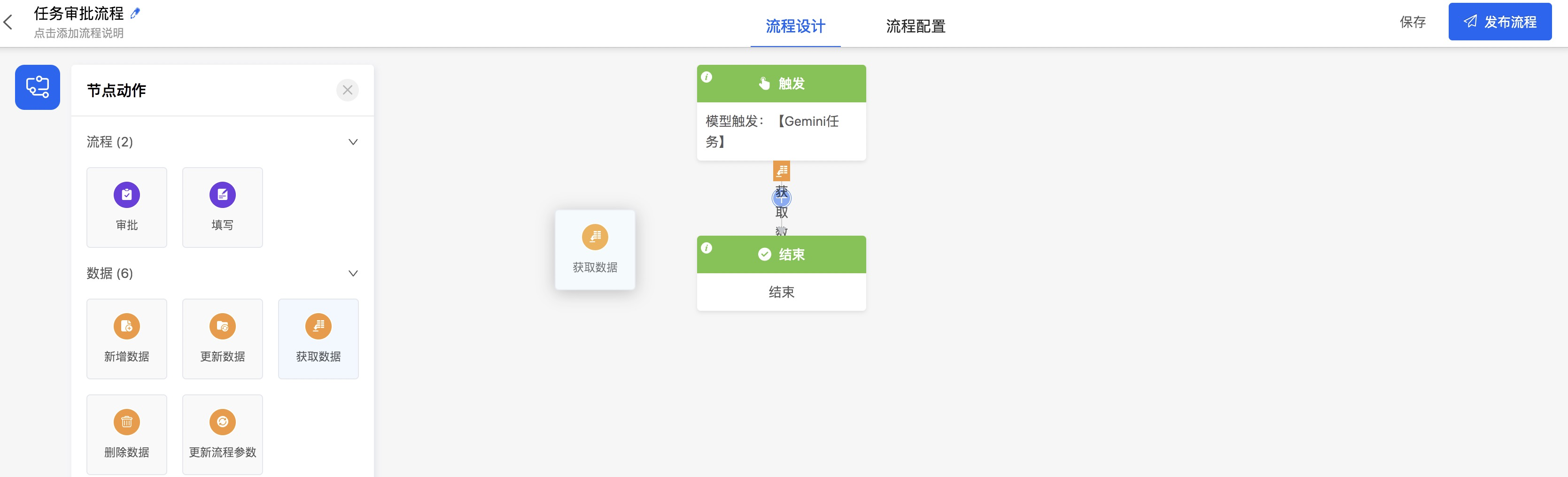
- 点击【获取数据】,在右侧属性面板中设置【获取数据条数】为多条,选择模型为【Gemini用户任务实例】,点击【筛选条件】的【{X}】图标,进行数据获取的条件设置
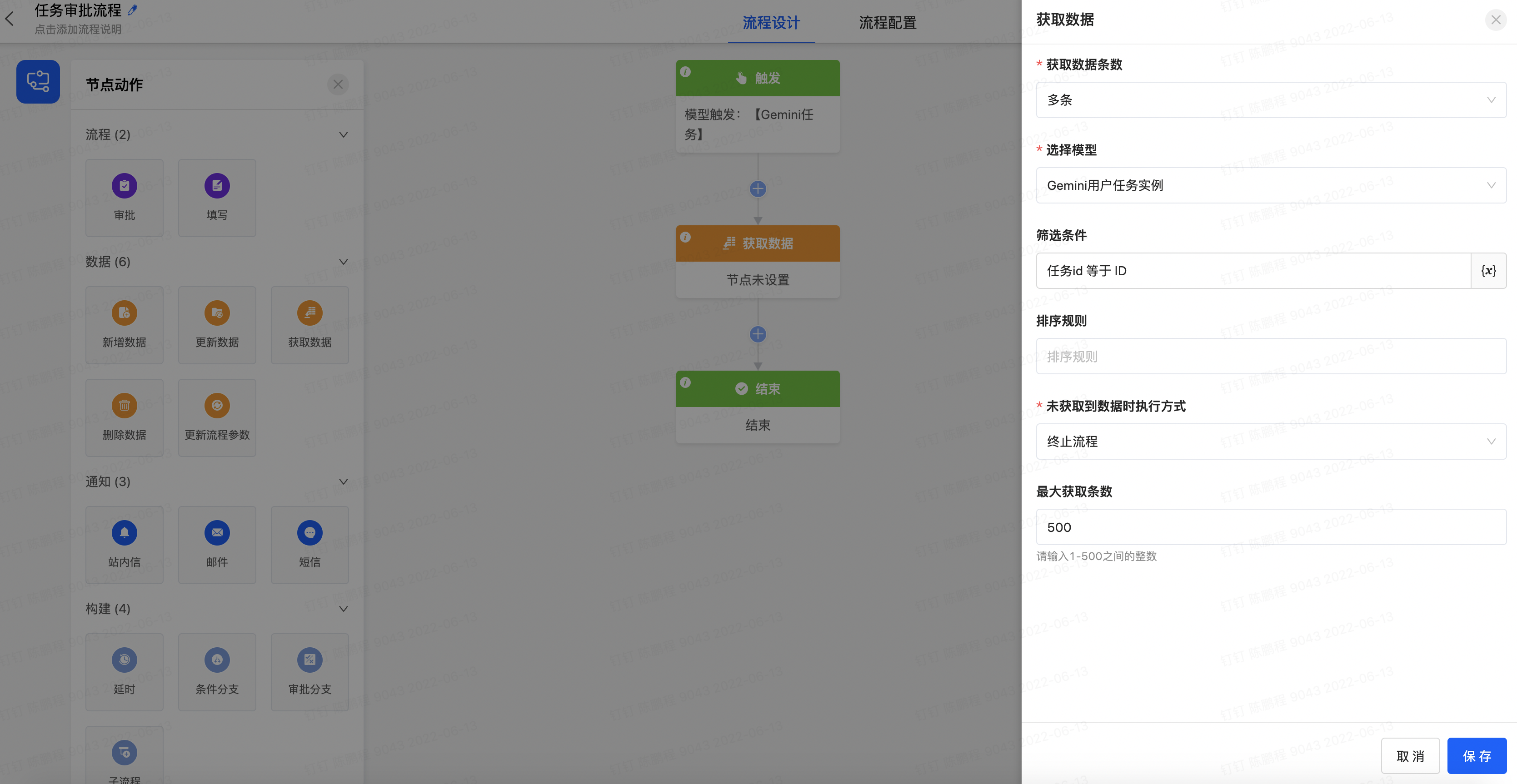
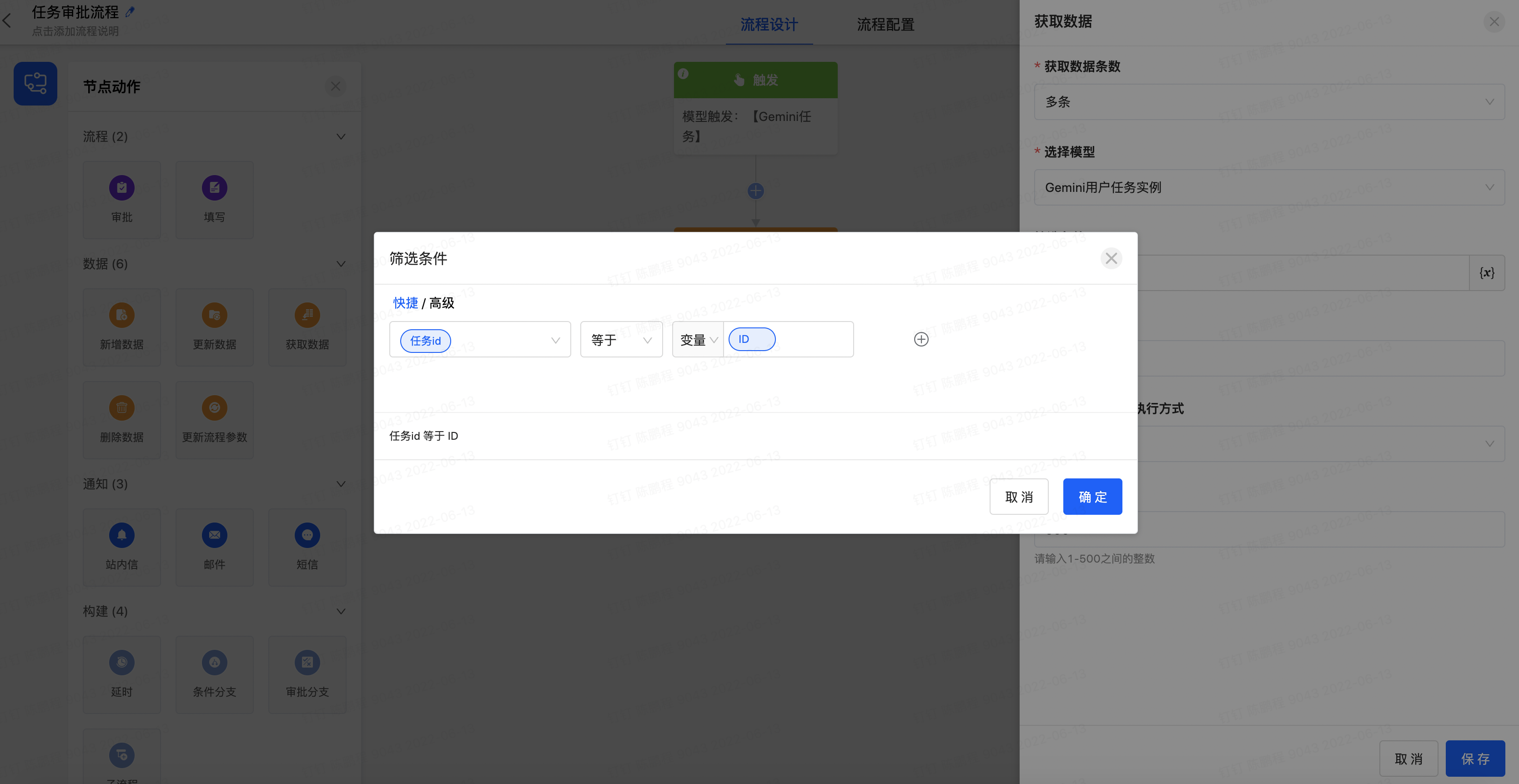
- 选择条件字段为【任务ID】条件操作符为【等于】,条件为变量的导购字段的ID。当上下文只有一个变量时默认不需要选择,这里默认的是【模型触发:[Gemini任务]】,设置好以后点击确认,回到属性面板设置【未获取到数据时执行方式】为【终止流程】,并点击节点【保持】按钮
-
增加【更新数据】节点,在右侧属性面板中
-
【更新模型】选择【模型触发:[Gemini任务]】
-
【字段列表】点击【创建】按钮
-
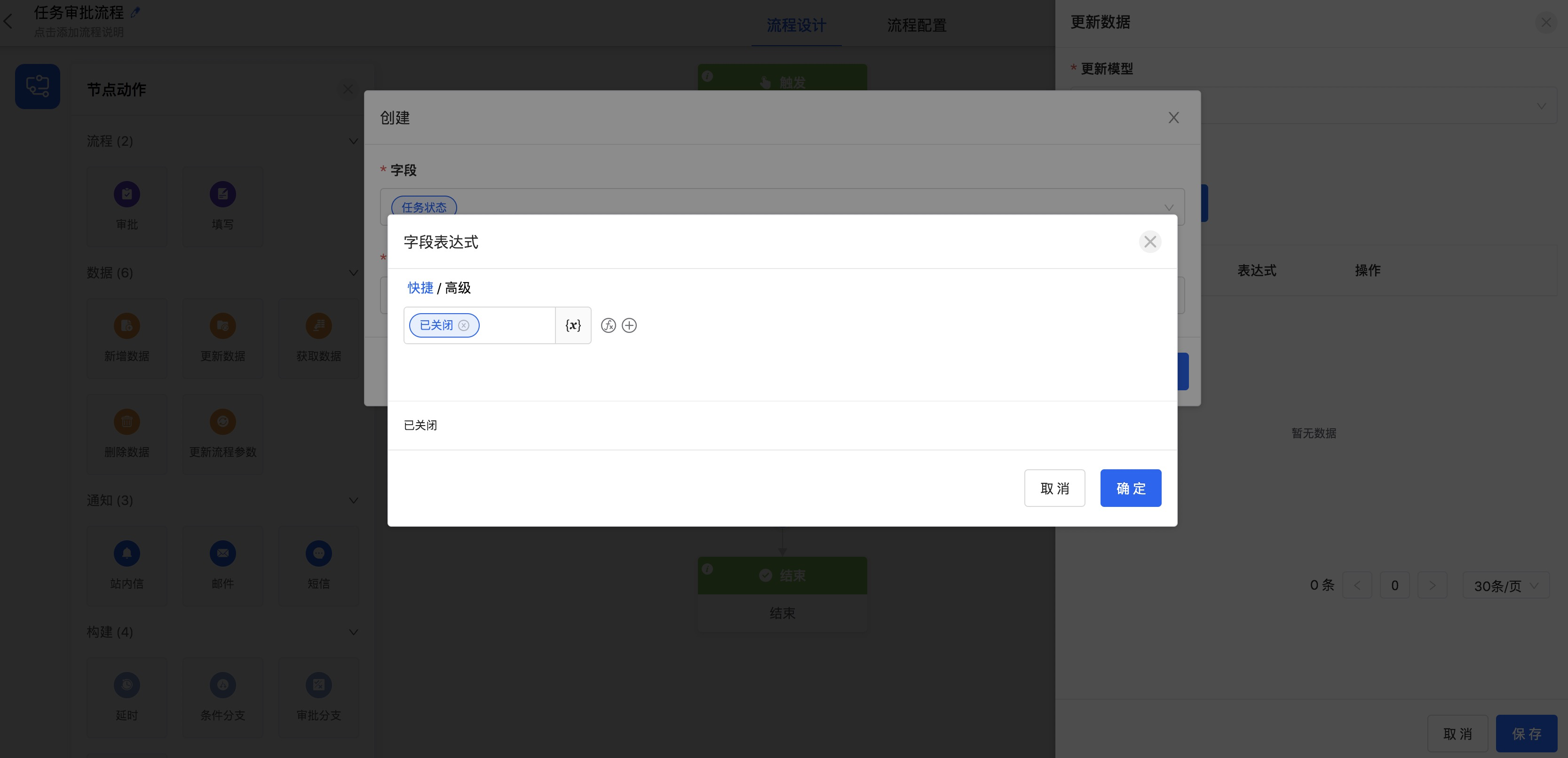
字段选择 更新【任务状态】字段
-
表达式设置为:【已关闭】。
-
-
【字段列表】点击【创建】按钮
-
字段选择 更新【任务审核状态】字段
-
表达式设置为:【审核中】。
-
-
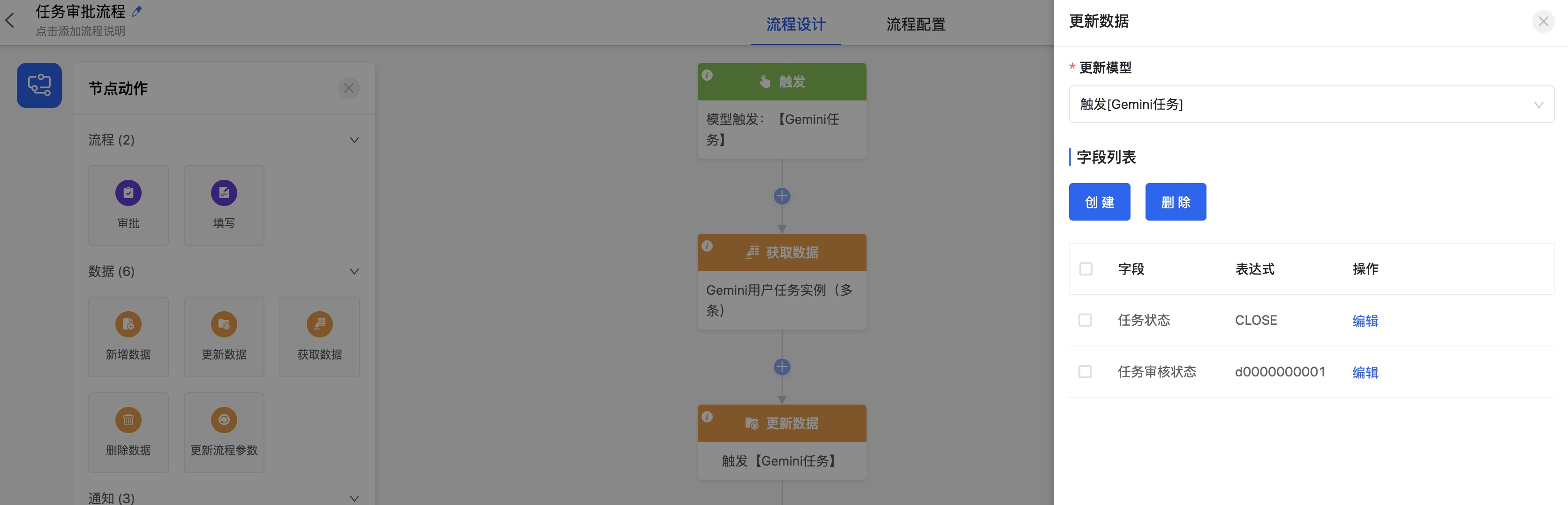
最终完成的【模型触发:[Gemini任务]】更新设置
a. 【模型触发:[Gemini任务]】的【任务状态】字段等于数字字典的【已关闭】,任务审核状态为【审核中】
b. 最后点击节点【保持】按钮。
-
再增加【更新数据】节点,在右侧属性面板中
-
【更新模型】选择【获取数据[Gemini用户任务实例]】
-
【字段列表】点击【创建】按钮
-
字段选择 更新【任务状态】字段
-
表达式设置为:【已关闭】。
-
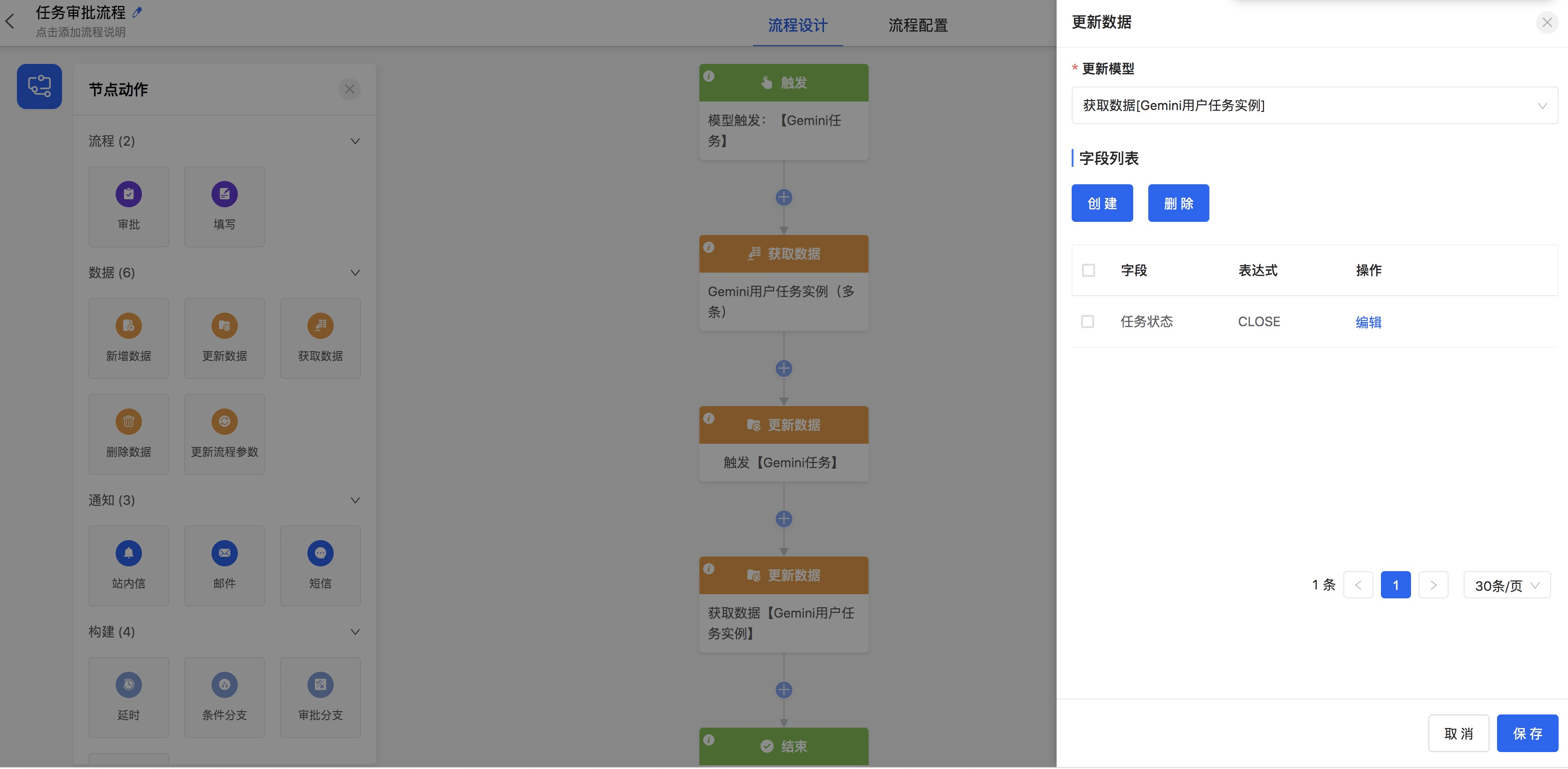
最终完成的【获取数据[Gemini用户任务实例]】更新设置
a. 【获取数据[Gemini用户任务实例]】的【任务状态】字段等于数字字典的【已关闭】
b. 最后点击节点【保持】按钮。
-
-
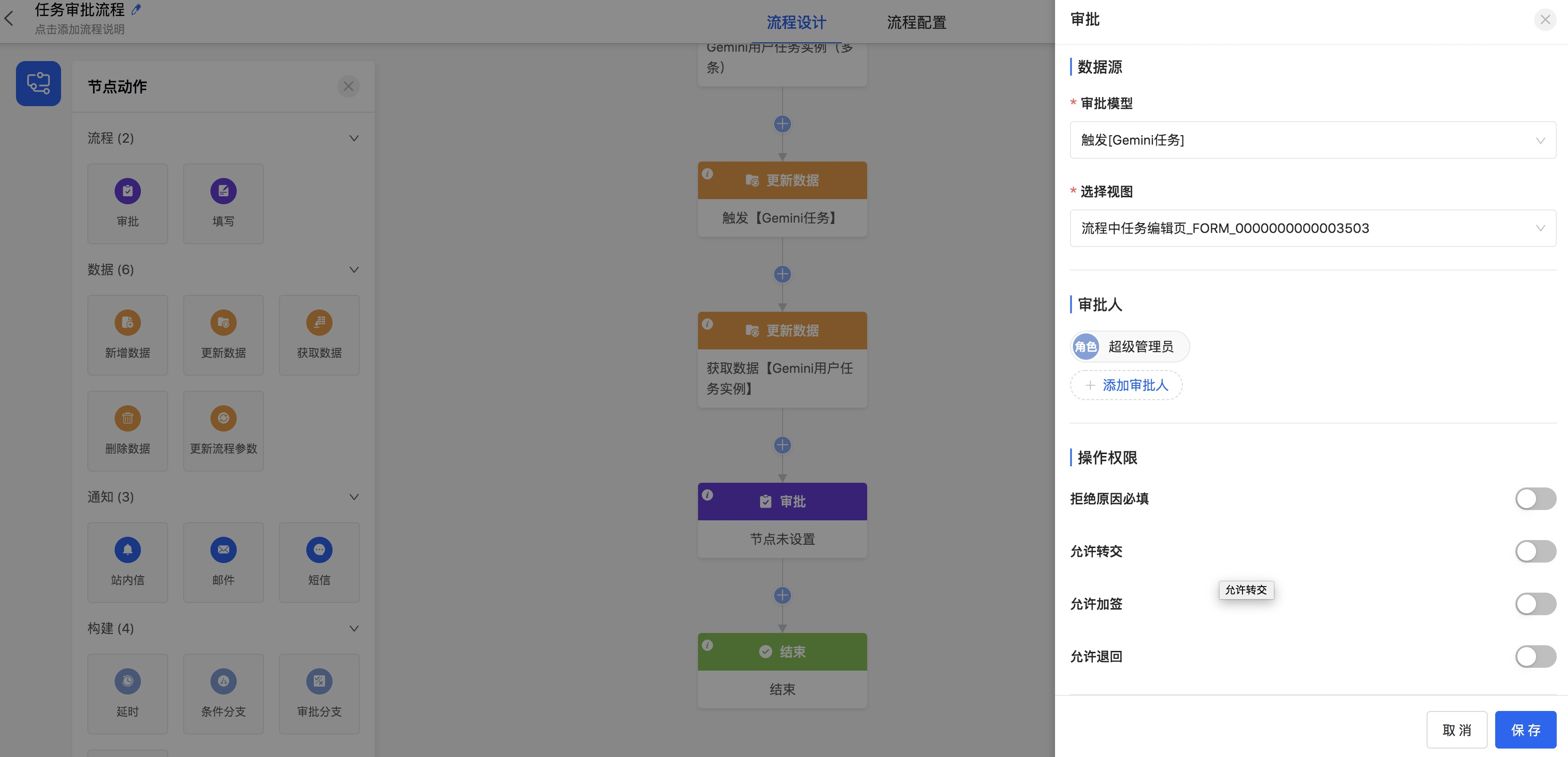
增加【审批】节点,在右侧属性面板中
-
【审批模型】选择模型为【模型触发:[Gemini任务]】
-
【选择视图】选择前面新建的页面【流程中的任务编辑页】
-
【审批人】选择角色为【超级管理员】
-
【数据】权限全部设置为【查看】
-
其他配置项默认,需要了解更多请查看产品使用手册
-
最后点击节点【保持】按钮。
-
-
新增【审核分支】,在【通过】分支中增加两个数据更新节点,跟审核前的两个数据更新节点对应
-
【模型触发:[Gemini任务]】的【任务状态】字段等于数字字典的【初始化】,任务审核状态为【审核通过】
-
【获取数据[Gemini用户任务实例]】的【任务状态】字段等于数字字典的【初始化】
-


- 流程确保保持并发布过,点击右上角【发布流程】完成流程的保存与发布
Step5 检验效果
-
创建任务后,任务状态为【关闭】状态,任务列表中的任务状态为多个状态的计算值
-
审核通过后,任务状态为【进行中】状态,任务列表中的任务状态为多个状态的计算值
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9337.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验