
1. 流程介绍
日常工作和生活中到处都存在各种各样的流程,例如业务开展中的产品研发流程、产品制作流程、订单发货流程等,也有管控分险的费用报销流程、员工请假审批流程、项目立项流程等。流程设计器可以帮助公司实现流程的数字化,规范流程操作,减少人工操作并留存痕迹,提高工作效率和安全性。
2. 流程的组成
流程设计器主要包含基本操作和流程设计两个部分。前者包含了流程的新增、删除、复制、停用/启用、编辑、搜索。后者包含单一流程的基础信息修改、流程设计、参数配置、保存、发布。
2.1 流程的基本操作
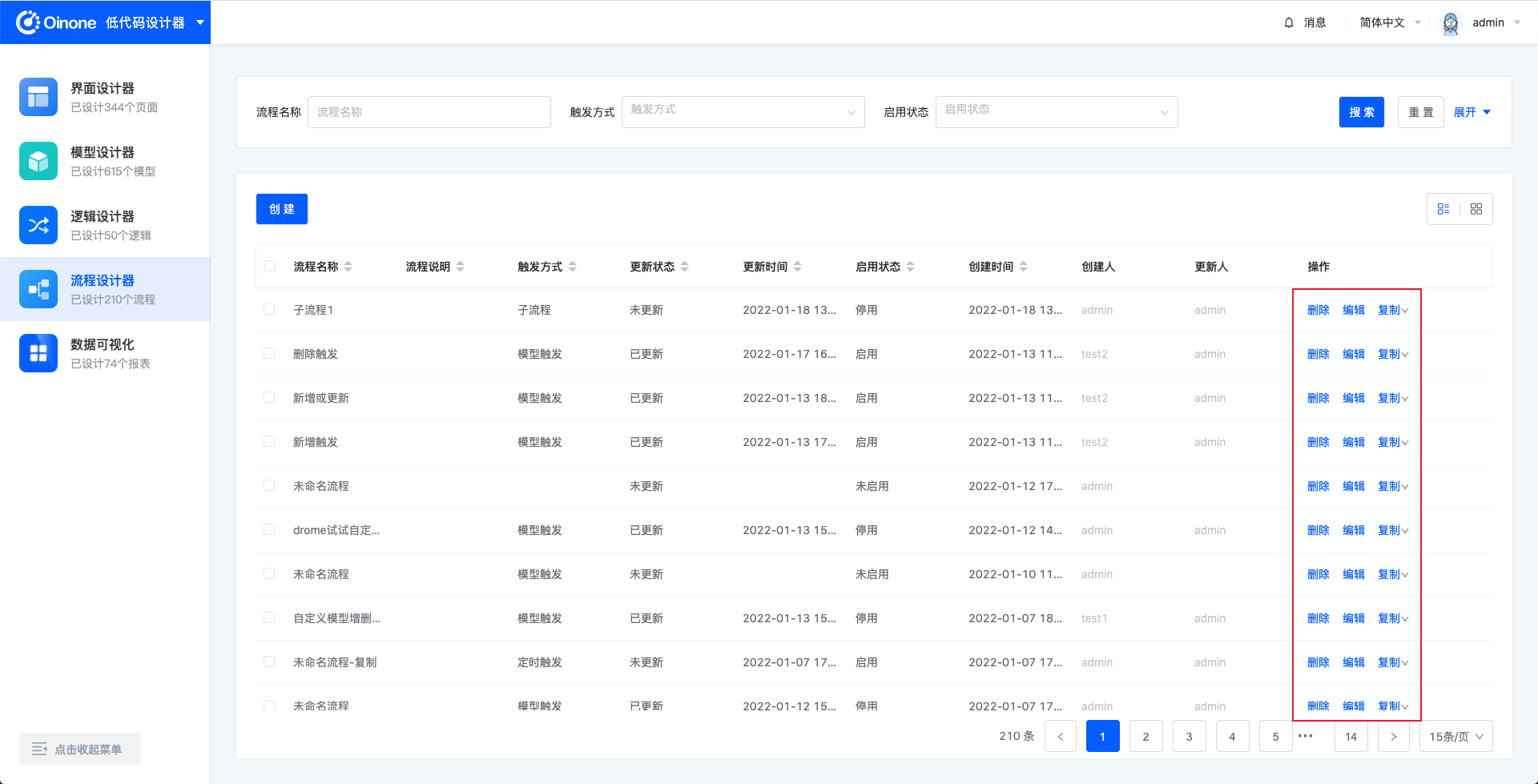
流程页面有两种显示方式,默认为平铺显示的模式,可以点击切换为列表详情显示的模式。
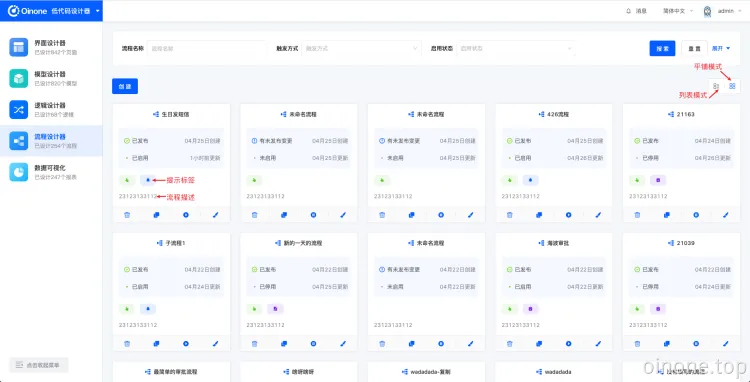

2.1.1 新增
平铺显示和列表详情模式下点击左上角的创建按钮即可新增一个流程,点击后进入流程设计页面,流程名默认为“未命名流程”,可自行修改。
2.1.2 删除
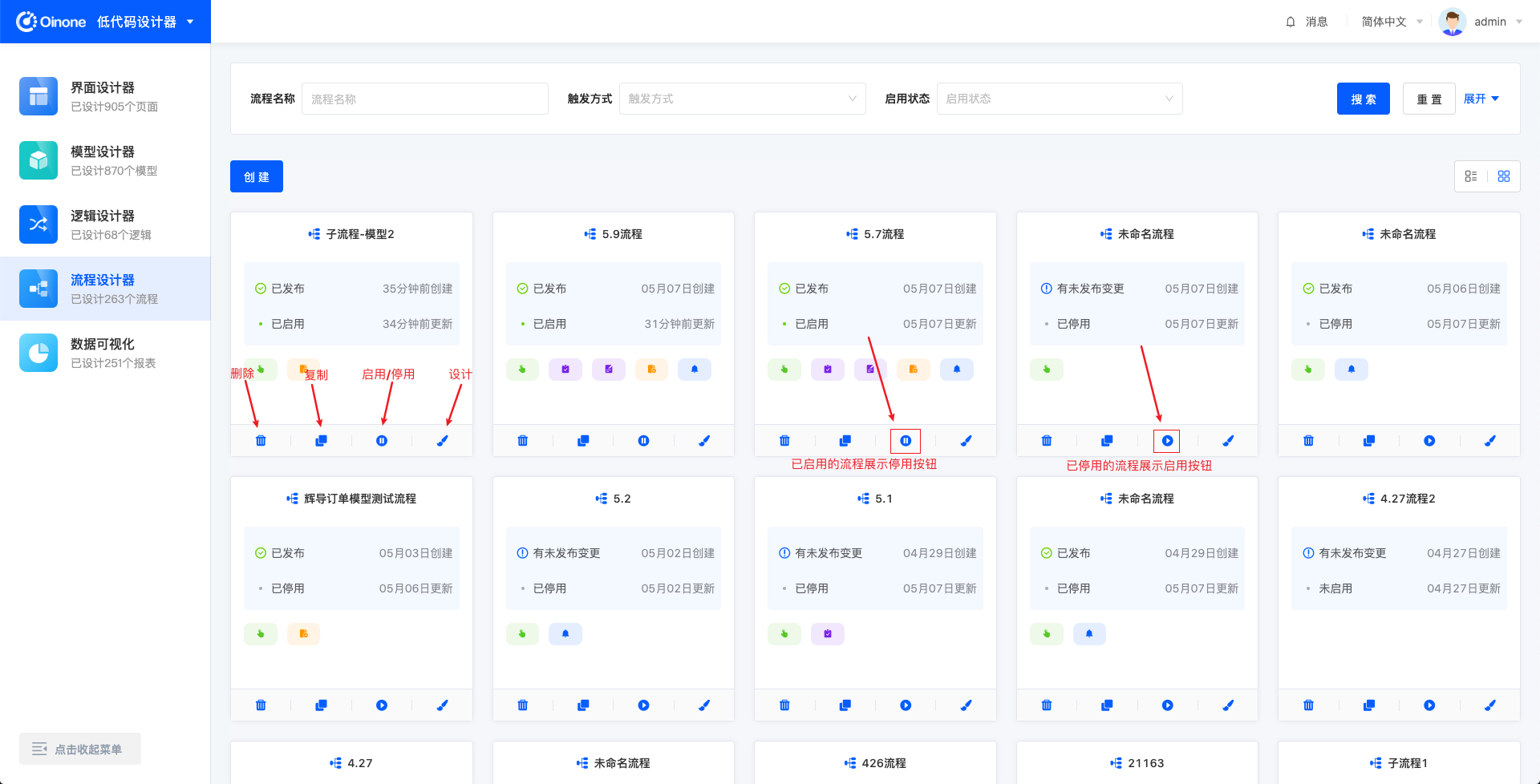
遇到流程创建有误,没有使用过且将来也不会使用该流程,可以删除流程。需要注意的是,删除流程的前提是该流程已停用,并且该流程从未执行过。
2.1.3 复制
遇到流程节点动作相似度较高的情况可以使用复制流程的功能,点击按钮后生成一个“原流程名-复制”的流程,并且进入新流程的流程设计界面。
2.1.4 停用/启用
流程需要更新或暂时不用时可以使用停用功能。流程停用后将不会执行流程中的动作,正在执行中的流程不受停用影响,会正常执行直到流程结束。
点击启用按钮,流程恢复启用状态,可正常触发。
2.1.5 编辑
点击编辑进入该流程的设计页面。
2.1.6 搜索
页面最上方的是搜索区,可以按照流程名称、触发方式、启用状态、更新状态进行筛选搜素,点击重置按钮修改搜索条件。


Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9411.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验