
我们的Oinone平台采用模型驱动的方式,并符合面向对象设计原则,每个需求都可以是一个独立模块,可以独立安装、升级和卸载。这让系统真正像乐高积木一样搭建,具有高度的灵活性和可维护性。
与大部分低代码或无代码平台不同的是,它们的应用市场上的应用往往是模板式的,也就是说,这是一个拷贝,个性化只能在应用上直接修改,而且一旦修改就不能升级。这对于软件公司和客户来说都非常痛苦。客户无法享受到软件公司产品的升级功能,而软件公司在服务大量客户时,也会面临不同版本的维护问题,成本也非常高。而我们的Oinone平台完全避免了这些问题,让客户和软件公司都可以从中受益(如下图2-9、2-10所示)。
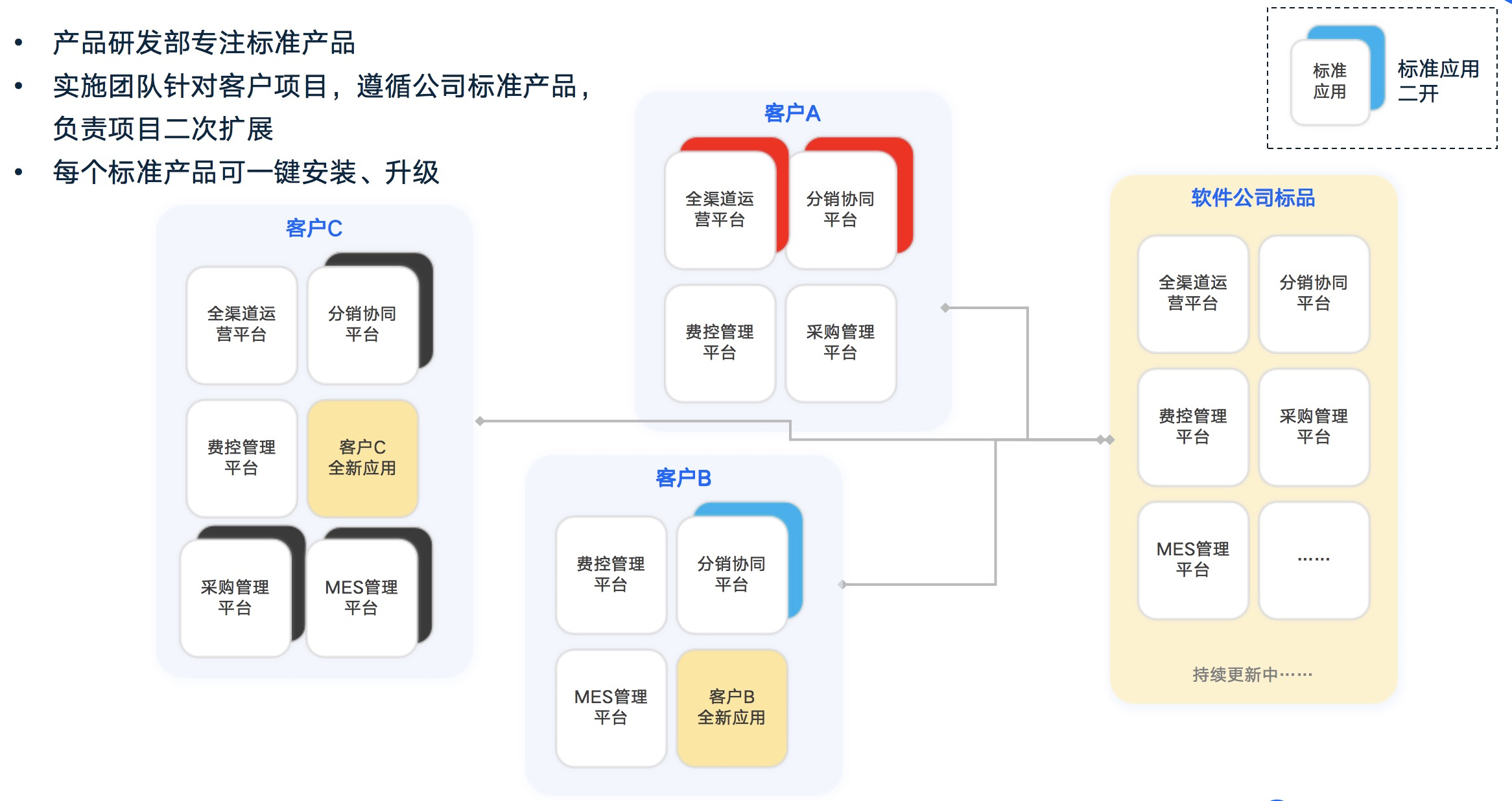

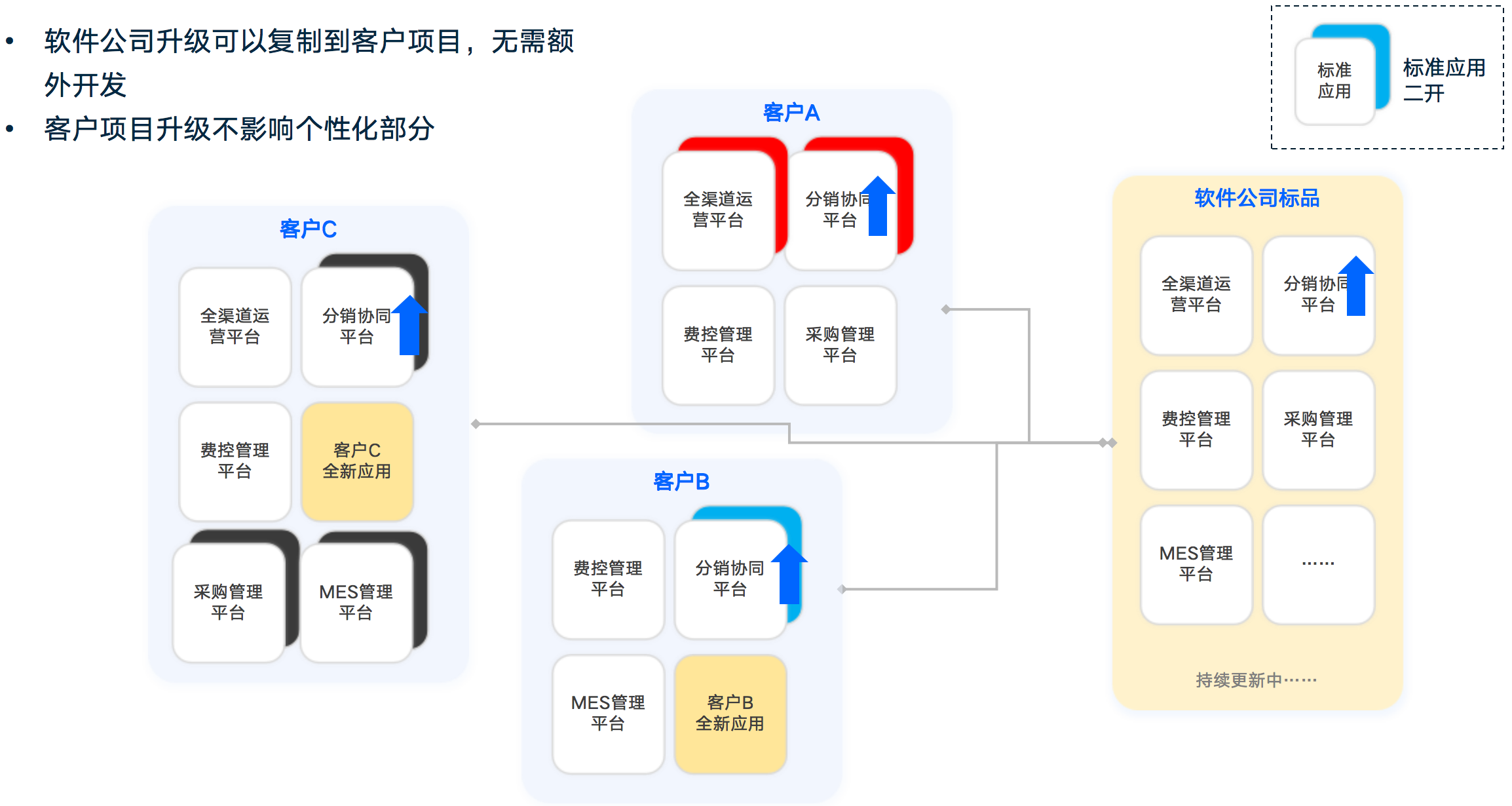
实现原理
在满足客户个性化定制需求时,传统的方法通常是直接修改标准产品源码,但这样做会带来一个问题:标准产品无法持续升级。相反,无论是在OP模式还是SaaS模式下,Oinone都采用全新的模块为客户进行个性化开发,保持标准产品和个性化模块的独立维护和升级。这是因为在元数据设计时,Oinone采用了面向对象的设计原则,实现了元数据设计与面向对象设计思想的完美融合。
面向对象设计的核心特征包括封装、继承、多态,而Oinone的元数据设计完全融入了这些思想。下面是几个例子,说明Oinone的元数据设计如何体现面向对象设计的核心特征,并带来了什么好处:
-
继承:在继承原有模型的字段、逻辑、展示的情况下,增加一段代码来扩展模型的字段、逻辑、展示。
-
多态:在继承原有模型的字段、逻辑、展示的情况下,增加一段代码来覆盖模型的原有字段、逻辑、展示。
-
封装:外部无需关心模型内部如何实现,只需按照不同场景调用模型对应开放级别的字段、逻辑、展示。
这些特征和优势使得Oinone在满足客户个性化需求时更加灵活和可持续,同时使得标准产品的维护和升级变得更加容易和高效。
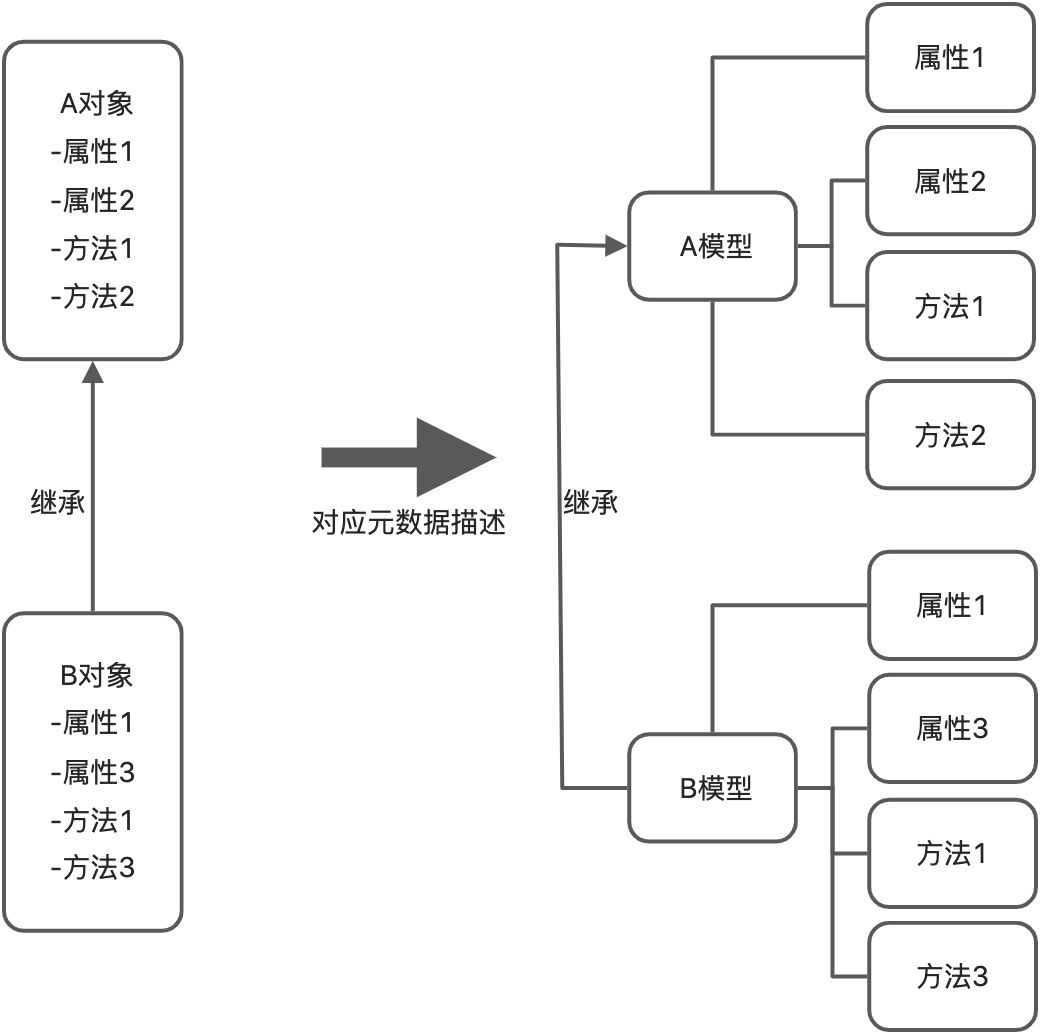
在Java语言设计中,万物皆对象,一切都以对象为基础。而Oinone的元数据设计则是以模型为出发点,作为数据和行为的承载体。如下图2-11清晰地描述了Java面向对象编程中封装、继承、多态在Oinone元数据中的对应关系。Oinone元数据描述了B对象继承A对象并拥有其所有属性和方法,并覆盖了A对象的属性1和方法1,同时新增了属性3和方法3。
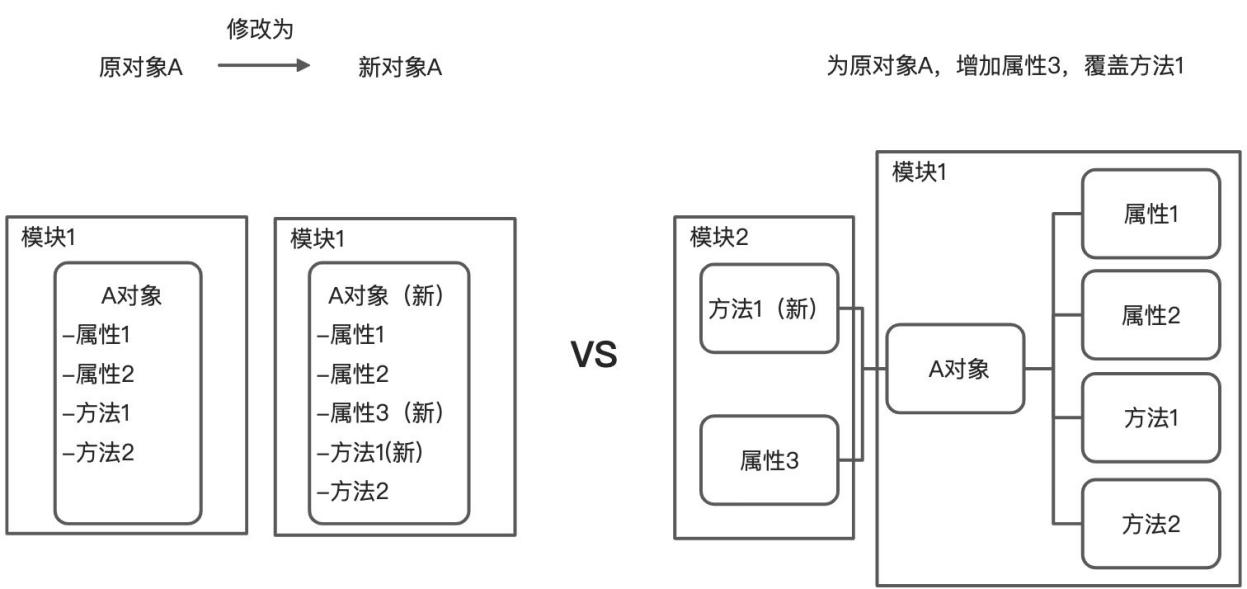
此外,Oinone的面向对象特性是用元数据来描述的。一方面,我们基于Java编码规范收集相关元数据,以保持不改变Java编程习惯。另一方面,方法和对象的挂载是松耦合的,只要按照元数据规范进行挂载,就能轻松地将其附加到模型上。在不改变原有A对象的情况下,我们可以直接增加方法和属性(如下图2-12所示)。
Oinone函数不仅支持面向对象的继承和多态特性,还提供了面向切面的拦截器和SPI机制的扩展点,以应对方法逻辑的覆盖和扩展,以及系统层面的逻辑扩展(如下图2-13所示)。这些扩展功能可以独立地在模块中维护。
其中,拦截器可以在不侵入函数逻辑的情况下,根据优先级为满足条件的函数添加执行前和执行后的逻辑。
扩展点是一种类似于SPI机制的逻辑扩展机制,用于扩展函数的逻辑。通过这一机制,可以对函数逻辑进行灵活的扩展,以满足不同的业务需求。
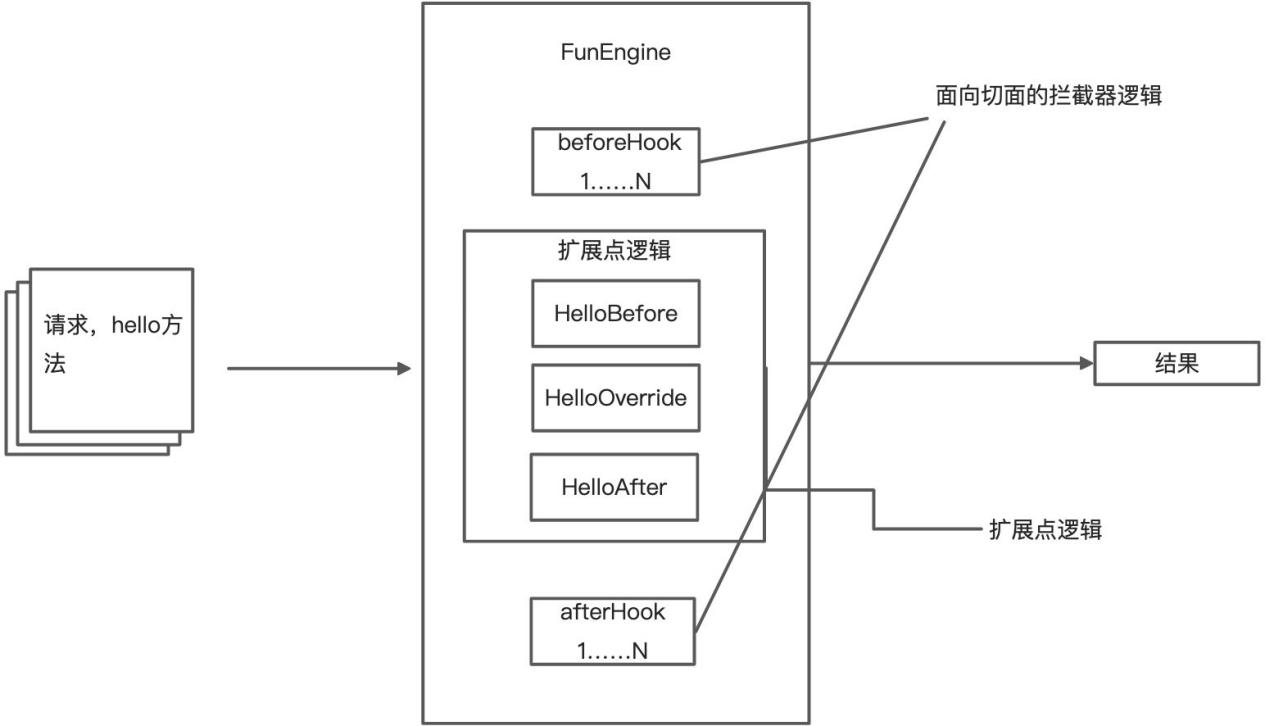
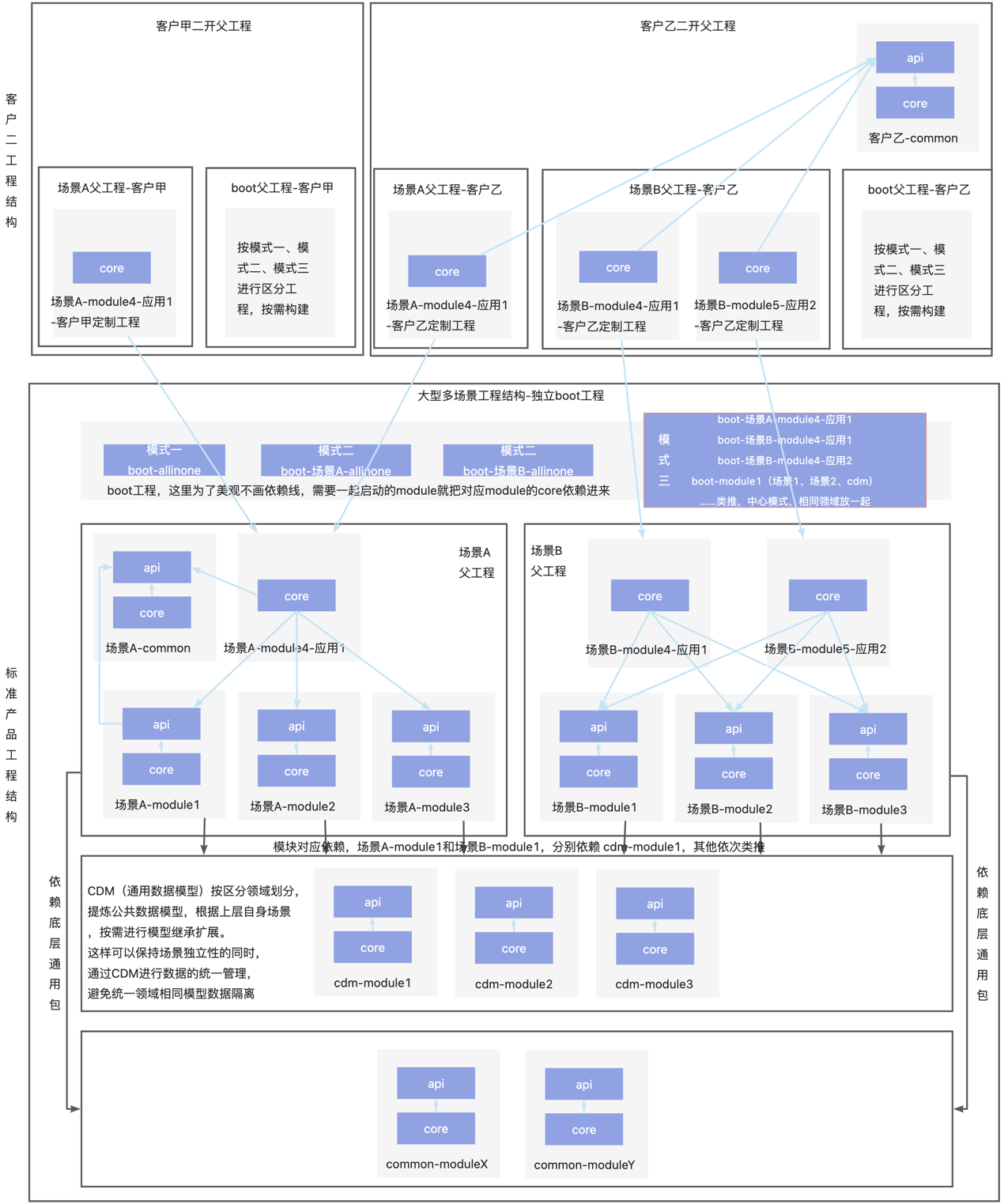
不管是对象、属性还是方法,都可以以独立的模块方式来扩展,这就使得每一个需求都可以成为一个独立的模块,方便我们在研发标准产品时进行模块化的划分,同时也让我们在以低代码模式为客户进行二次开发时,能够更好地支持“标准产品迭代与个性化保持独立”的需求。在2.4.3【oinone独特性之低无一体】一文中,我们也提到了这个特性,但那是在低无一体的情况下,通过元数据融合来实现的。让我们看看基于低代码开发模式下,典型的Oinone二次开发工程结构(如下图2-14所示),就可以更好地理解这个特性啦!
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9221.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验