
在日常开发中,我们经常需要把一些通用的信息放入程序执行的上下文中,以便业务开发人员快速获取。那么oinone的PamirsSession就是来解决此类问题的。
一、PamirsSession介绍
在oinone的体系中PamirsSession是执行上下文的承载,您能从中获取业务基础信息、指令信息、元数据信息、环境信息、请求参数,以及前后端MessageHub等。在前面的学习过程中我们已经多次接触到了如何使用PamirsSession:
-
在4.1.19【框架之网关协议-后端占位符】一文中,使用PamirsSession.getUserId()来获取当前登入用户Id,诸如此类的业务基础信息;
-
在4.1.18【框架之网关协议-variables变量】一文中,使用PamirsSession.getRequestVariables()得到PamirsRequestVariables对象,进而获取前端请求的相关信息;
-
在4.1.5【模型之持久层配置】一文中,使用PamirsSession.directive(),来操作元位指令系统,进而影响执行策略;
-
在4.1.13【Action之校验】、3.4.1【构建第一个Function】等文章中,都用到PamirsSession.getMessageHub()来设置返回消息。
二、构建模块自身Session(举例)
不同的应用场景对PamirsSession的诉求是不一样的,这个时候我们就可以去扩展PamirsSession来达到我们的目的
构建模块自身Session的步骤
-
构建自身特有的数据结构XSessionData
-
对XSessionData进行线程级缓存封装
-
利用Hook机制初始化XSessionData并放到ThreadLocal中
-
定义自身XSessionApi
-
实现XSessionApi接口、SessionClearApi。在请求结束时会调用SessionClearApi的clear方法
-
定义XSession继承PamirsSession
扩展PamirsSession的经典案例设计图
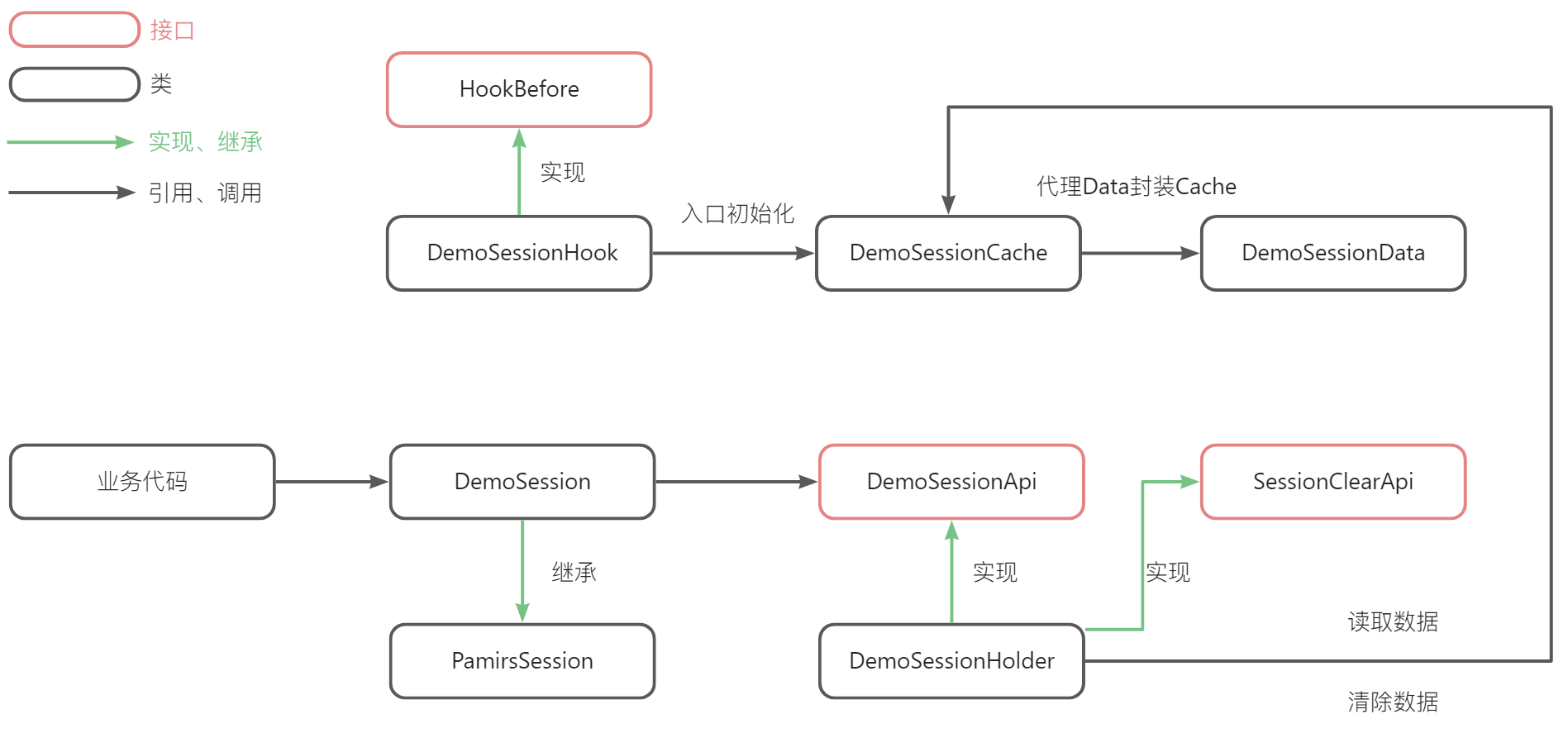

构建Demo应用自身Session
下面的例子为给Session放入当前登陆用户
Step1 新建DemoSessionData类
构建自身特有的数据结构DemoSessionData,增加一个模型为PamirsUser的字段user,DemoSessionData用Data注解,注意要用Oinone平台提供的@Data
package pro.shushi.pamirs.demo.core.session;
import pro.shushi.pamirs.meta.annotation.fun.Data;
import pro.shushi.pamirs.user.api.model.PamirsUser;
@Data
public class DemoSessionData {
private PamirsUser user;
}Step2 新建DemoSessionCache
对DemoSessionData进行线程级缓存封装
package pro.shushi.pamirs.demo.core.session;
import pro.shushi.pamirs.meta.api.CommonApiFactory;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.user.api.model.PamirsUser;
import pro.shushi.pamirs.user.api.service.UserService;
public class DemoSessionCache {
private static final ThreadLocal<DemoSessionData> BIZ_DATA_THREAD_LOCAL = new ThreadLocal<>();
public static PamirsUser getUser(){
return BIZ_DATA_THREAD_LOCAL.get()==null?null:BIZ_DATA_THREAD_LOCAL.get().getUser();
}
public static void init(){
if(getUser()!=null){
return ;
}
Long uid = PamirsSession.getUserId();
if(uid == null){
return;
}
PamirsUser user = CommonApiFactory.getApi(UserService.class).queryById(uid);
if(user!=null){
DemoSessionData demoSessionData = new DemoSessionData();
demoSessionData.setUser(user);
BIZ_DATA_THREAD_LOCAL.set(demoSessionData);
}
}
public static void clear(){
BIZ_DATA_THREAD_LOCAL.remove();
}
}Step3 新建DemoSessionHook
利用Hook机制,调用DemoSessionCache的init方法初始化DemoSessionData并放到ThreadLocal中。
@Hook(module= DemoModule.MODULE_MODULE), 规定只有增对DemoModule模块访问的请求该拦截器才会生效,不然其他模块的请求都会被DemoSessionHook拦截。
package pro.shushi.pamirs.demo.core.hook;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.DemoModule;
import pro.shushi.pamirs.demo.core.session.DemoSessionCache;
import pro.shushi.pamirs.meta.annotation.Hook;
import pro.shushi.pamirs.meta.api.core.faas.HookBefore;
import pro.shushi.pamirs.meta.api.dto.fun.Function;
@Component
public class DemoSessionHook implements HookBefore {
@Override
@Hook(priority = 1,module = DemoModule.MODULE_MODULE)
public Object run(Function function, Object... args) {
DemoSessionCache.init();
return function;
}
}
Step4 新建DemoSessionApi
package pro.shushi.pamirs.demo.core.session;
import pro.shushi.pamirs.meta.api.CommonApi;
import pro.shushi.pamirs.user.api.model.PamirsUser;
public interface DemoSessionApi extends CommonApi {
PamirsUser getUser();
}
Step5 新建DemoSessionHolder
-
实现DemoSessionApi接口
-
实现SessionClearApi接口,在请求结束时会调用SessionClearApi的clear方法
package pro.shushi.pamirs.demo.core.session;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.meta.api.core.session.SessionClearApi;
import pro.shushi.pamirs.user.api.model.PamirsUser;
@Component
public class DemoSessionHolder implements DemoSessionApi, SessionClearApi {
@Override
public PamirsUser getUser() {
return DemoSessionCache.getUser();
}
@Override
public void clear() {
DemoSessionCache.clear();
}
}Step6 新建DemoSession
package pro.shushi.pamirs.demo.core.session;
import pro.shushi.pamirs.meta.api.CommonApiFactory;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.user.api.model.PamirsUser;
public class DemoSession extends PamirsSession {
public static PamirsUser getUser(){
return CommonApiFactory.getApi(DemoSessionApi.class).getUser();
}
}Step7 修改UserPlaceHolder
使用DemoSession.getUser().getId()替代PamirsSession.getUserId()
package pro.shushi.pamirs.demo.core.placeholder;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.core.session.DemoSession;
import pro.shushi.pamirs.user.api.AbstractPlaceHolderParser;
@Component
public class UserPlaceHolder extends AbstractPlaceHolderParser {
@Override
protected String value() {
return DemoSession.getUser().getId().toString();
}
@Override
public Integer priority() {
return 10;
}
@Override
public Boolean active() {
return Boolean.TRUE;
}
@Override
public String namespace() {
return "currentUserId";
}
}Step8 重启看效果
效果跟4.1.19【框架之网关协议-后端占位符】一文中的例子一样
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9295.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验