
1. 流程触发
新增的流程设计页面默认包含两个节点,一个是流程的触发节点:确定流程开始的条件;另一个是流程结束的节点。
流程触发方式有模型触发、定时触发、日期触发三种方式,未设置流程触发方式时无法继续添加后续流程节点,同时无法进行流程发布,如左下图。触发方式设置完成后,可从左侧菜单栏拖入或流程箭头中的加号点击添加节点动作,如右下图。


1.1 模型触发
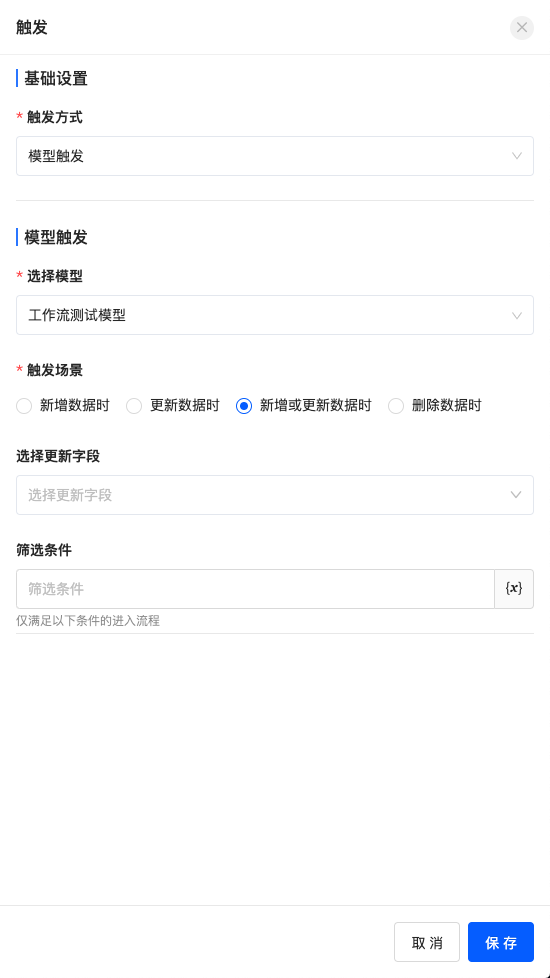
模型触发适用于模型中的数据字段变化开始流程的场景,比如员工请假审批流程。
模型触发的场景有数据的增删改,也可以对模型中的单个或多个字段进行条件筛选,若包含更新数据的场景可以设置选择更新字段,只有设置的字段更新才会触发流程,若不设置选择更新字段或者筛选条件,则模型中任一字段发生设置场景的变化时都会触发流程。
1.2 定时触发
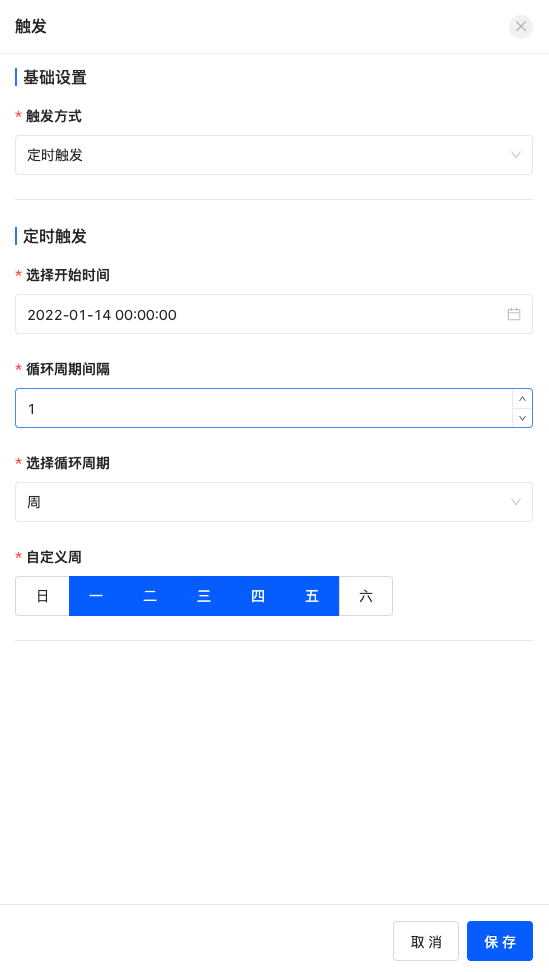
定时触发适用于周期性调用流程的场景,比如仓库周期性盘点的流程。
需要设置一个流程第一次执行的时间,配置好循环的周期间隔。特殊的是选择周为周期时,当前周选中的日期也会执行流程。例:开始时间:2022-01-14(周四) 循环周期间隔:1周 自定义设置为周一到周五,则2022-01-15(本周五)也会执行流程操作。
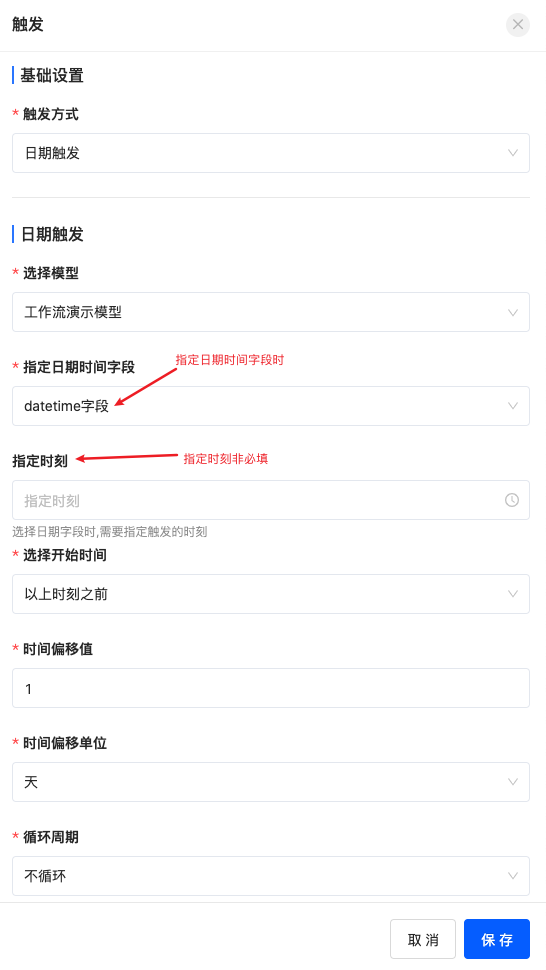
1.3 日期触发
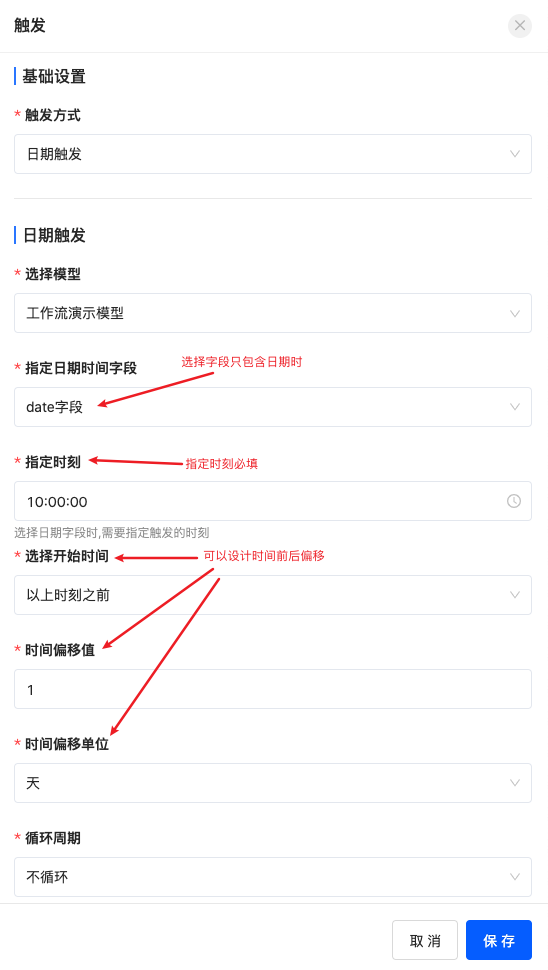
日期触发适用于模型中的日期时间字段引发流程的场景,比如给员工发生日祝福短信的流程。
设置日期触发时,若指定字段只包含日期,则必须要指定时刻,如左下图。例如给员工发生日祝福短信时根据模型中的员工生日数据获取到了执行流程的日期,需要制定开始该流程执行的具体时刻。若指定字段包含日期和时间,则不填写指定时刻时默认按照字段中的时刻开始执行流程,如右下图。例如办理业务后短信回访收集评价时根据模型中的业务完成时间,立即或延时发送短息。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9413.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验