
组件生命周期的意义所在:比如动态创建了「视图、字段」,等它们初始化完成或者发生了修改后要执行业务逻辑,这个时候只能去自定义当前字段或者视图,体验极差,平台应该提供一些列的生命周期,允许其他人调用生命周期的api去执行对应的逻辑。
一、实现原理


当用户通过内部API去监听某个生命周期的时候,内部会动态的去创建该生命周期,每个生命周期都有「唯一标识」,内部会根据「唯一标识」去创建对应的「Effect」,Effect会根据生命周期的「唯一标识」实例化一个「lifeCycle」,「lifeCycle」创建完成后,会被存放到「Heart」中,「Heart」是整个生命周期的心脏,当心脏每次跳动的时候(生命周期被监听触发)都会触发对应的生命周期
二、生命周期API
| API | 描述 | 返回值 |
|---|---|---|
| View LifeCycle | ||
| onViewBeforeCreated | 视图创建前 | ViewWidget |
| onViewCreated | 视图创建后 | ViewWidget |
| onViewBeforeMount | 视图挂载前 | ViewWidget |
| onViewMounted | 视图挂载后 | ViewWidget |
| onViewBeforeUpdate | 视图数据发生修改前 | ViewWidget |
| onViewUpdated | 视图数据修改后 | ViewWidget |
| onViewBeforeUnmount | 视图销毁前 | ViewWidget |
| onViewUnmounted | 视图销毁 | ViewWidget |
| onViewSubmit | 提交数据 | ViewWidget |
| onViewSubmitStart | 数据开始提交 | ViewWidget |
| onViewSubmitSuccess | 数据提交成功 | ViewWidget |
| onViewSubmitFailed | 数据提交失败 | ViewWidget |
| onViewSubmitEnd | 数据提交结束 | ViewWidget |
| onViewValidateStart | 视图字段校验 | ViewWidget |
| onViewValidateSuccess | 校验成功 | ViewWidget |
| onViewValidateFailed | 校验失败 | ViewWidget |
| onViewValidateEnd | 校验结束 | ViewWidget |
| Field LifeCycle | ||
| onFieldBeforeCreated | 字段创建前 | FieldWidget |
| onFieldCreated | 字段创建后 | FieldWidget |
| onFieldBeforeMount | 字段挂载前 | FieldWidget |
| onFieldMounted | 字段挂载后 | FieldWidget |
| onFieldBeforeUpdate | 字段数据发生修改前 | FieldWidget |
| onFieldUpdated | 字段数据修改后 | FieldWidget |
| onFieldBeforeUnmount | 字段销毁前 | FieldWidget |
| onFieldUnmounted | 字段销毁 | FieldWidget |
| onFieldFocus | 字段聚焦 | FieldWidget |
| onFieldChange | 字段的值发生了变化 | FieldWidget |
| onFieldBlur | 字段失焦 | FieldWidget |
| onFieldValidateStart | 字段开始校验 | FieldWidget |
| onFieldValidateSuccess | 校验成功 | FieldWidget |
| onFieldValidateFailed | 校验失败 | FieldWidget |
| onFieldValidateEnd | 校验结束 | FieldWidget |
上面列出的分别是「视图、字段」的生命周期,目前Action的生命周期还没有,后续再补充。
三、第一个View组件生命周期的监听(举例)
Step1 新建registryLifeCycle.ts
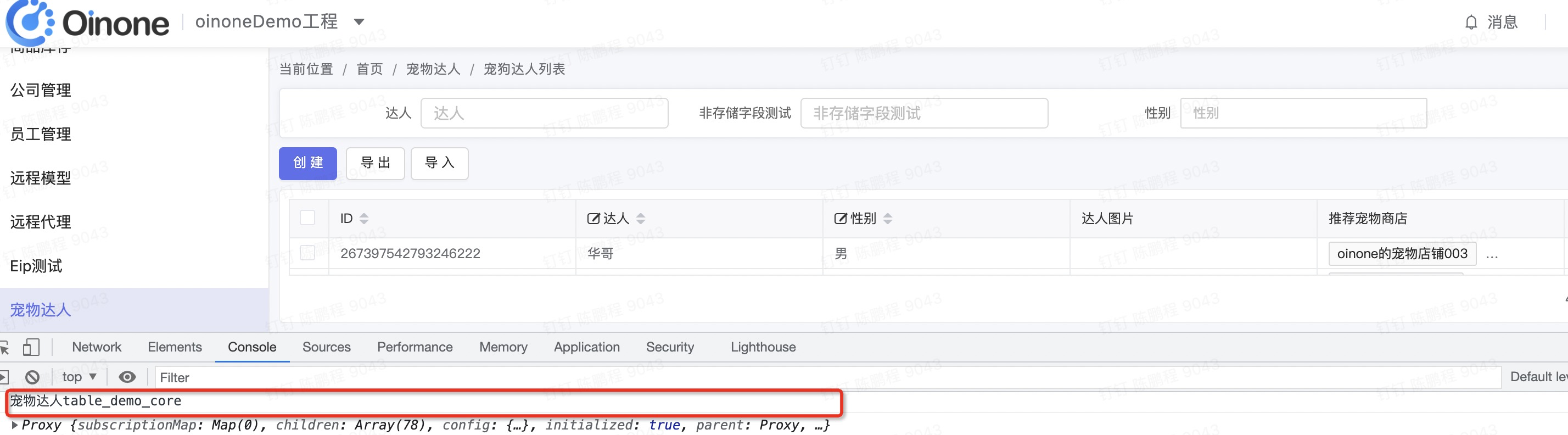
新建registryLifeCycle.ts,监听宠物达人的列表页。'宠物达人table_demo_core'为视图名,您需要找后端配合
import { onViewCreated } from '@kunlun/dependencies'
function registryLifeCycle(){
onViewCreated('宠物达人table_demo_core', (viewWidget) => {
console.log('宠物达人table_demo_core');
console.log(viewWidget);
});
}
export {registryLifeCycle}图4-2-1-2 新建registryLifeCycle.ts
Step2 修改main.ts
全局注册lifeCycle
import { registryLifeCycle } from './registryLifeCycle';
registryLifeCycle();Step3 看效果
四、第一个Filed组件生命周期的监听(举例)
Step1 修改registryLifeCycle.ts
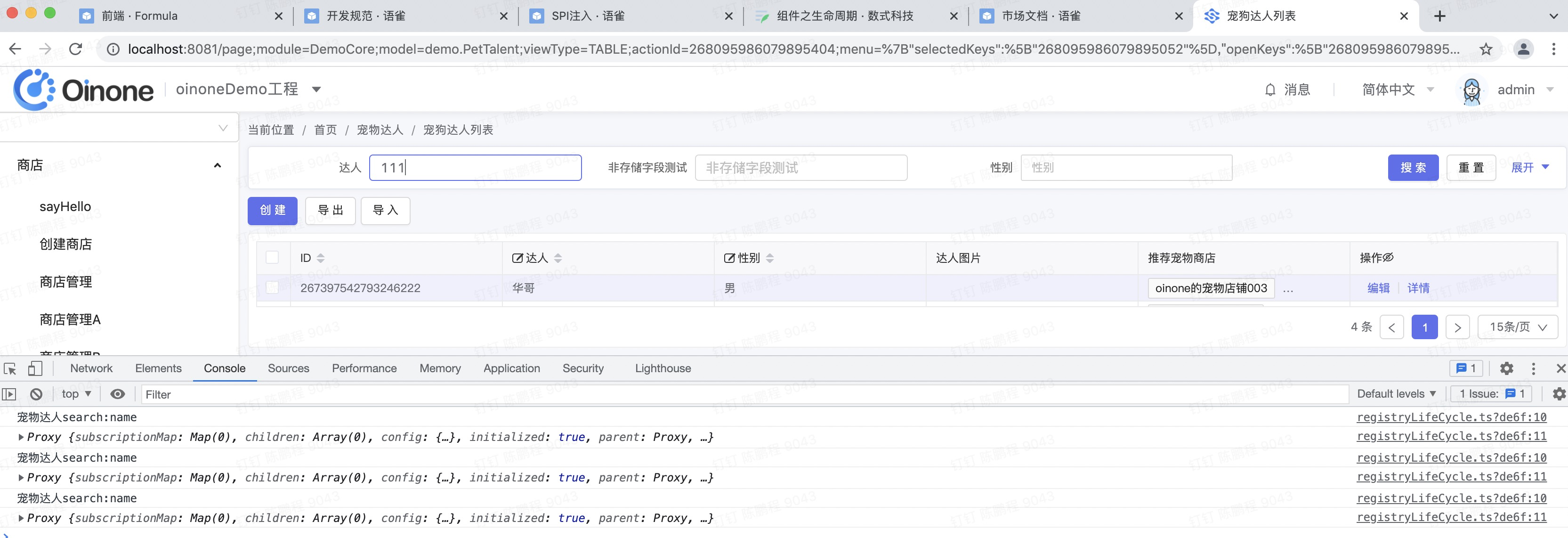
通过onFieldValueChange增加宠物达人搜索视图的name(达人)字段的值变化进行监听。
宠物达人search:name 代表 视图名:字段名
import { onViewCreated , onFieldValueChange} from '@kunlun/dependencies'
function registryLifeCycle(){
onViewCreated('宠物达人table_demo_core', (viewWidget) => {
console.log('宠物达人table_demo_core');
console.log(viewWidget);
});
onFieldValueChange('宠物达人search:name', (filedWidget) => {
console.log('宠物达人search:name');
console.log(filedWidget);
});
}
export {registryLifeCycle}Step2 看效果
输入三个1,执行三次
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9302.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验