
占在巨人的肩膀上,天地孤影任我行
1.2.1 数字化时代Oinone接棒Odoo
在数字化时代,中国在互联网化的应用、技术的领先毋庸置疑,但在软件的工程化、产品化输出方面仍有许多改进的空间。这时,我了解到了Odoo——一个国外非常优秀的开源ERP厂商,全球ERP用户数量排名第一,百级别员工服务全球客户。Odoo的工程化能力和商业模式深深吸引了我,它是软件行业典型的产品制胜和长期主义者的胜利之一。
在2019年,也就是数式刚成立的时候,我们跟很多投资人聊起公司的对标是谁,我不是要成为数字化时代的SAP,而是要成为Odoo。然而,当时大部分国内投资人并不了解Odoo,尽管它已经是全球最大的ERP厂商之一,因为当时Odoo还没有明确的估值。直到2021年7月份获得Summit Partners的2.15亿美元投资后,Odoo才正式成为IT独角兽企业。
Odoo对我们提供了极大的启示,因此我们致敬Odoo,同样选择开源,每年对产品进行升级发布。如今,Odoo15已经发布,而Oinone也已推出第三版,恰好相隔12年,这是一个时代的接棒,从信息化升迁至数字化。
1.2.2Oinone与Odoo的不同之处
- 技术方面的不同
在技术上,Oinone和Odoo有相同之处,也有不同之处。它们都基于元数据驱动的软件系统,但是它们在如何让元数据运作的机制上存在巨大差异。Odoo是企业管理场景的单体应用,而Oinone则致力于企业商业场景的云原生应用。因此,它们在技术栈的选择、前后端协议设计、架构设计等方面存在差异。
- 场景方面的不同
在场景上,Oinone和Odoo呈现许多差异。相对于SAP这些老牌ERP厂商,Odoo算是西方在企业级软件领域的后起之秀,其软件构建方式、开源模式和管理理念在国外取得了非凡的成就。然而,在国内,Odoo并没有那么成功或者并没有那么知名。国内做Odoo的伙伴普遍认为,Odoo与中国用户的交互风格不符,收费模式设计以及外汇管制使商业活动受到限制,本地化服务不到位,国内生态没有形成合力,伙伴们交流合作都非常少。另外,Odoo在场景方面主要围绕内部流程管理,与国内老牌ERP如用友、金蝶重叠,市场竞争激烈。相比之下,Oinone看准了企业视角由内部管理转向业务在线、生态在线(协同)带来的新变化,聚焦新场景,利用云、端等新技术的发展,从企业内外部协同入手,以业务在线驱动企业管理流程升级。它先立足于国内,做好国内生态服务,再着眼未来的国际化。
- 无代码设计器的定位
在无代码设计器的定位上,Odoo的无代码设计器是一个非常轻量的辅助工具,因为ERP场景下,一个企业实施完以后基本几年不会变,流程稳定度非常高。相反,Oinone为适应"企业业务在线化后,所有的业务变化与创新都需要通过系统来触达上下游,从而敏捷响应快速创新"的时代背景,重点打造出五大设计器。(如下图1-2所示)。
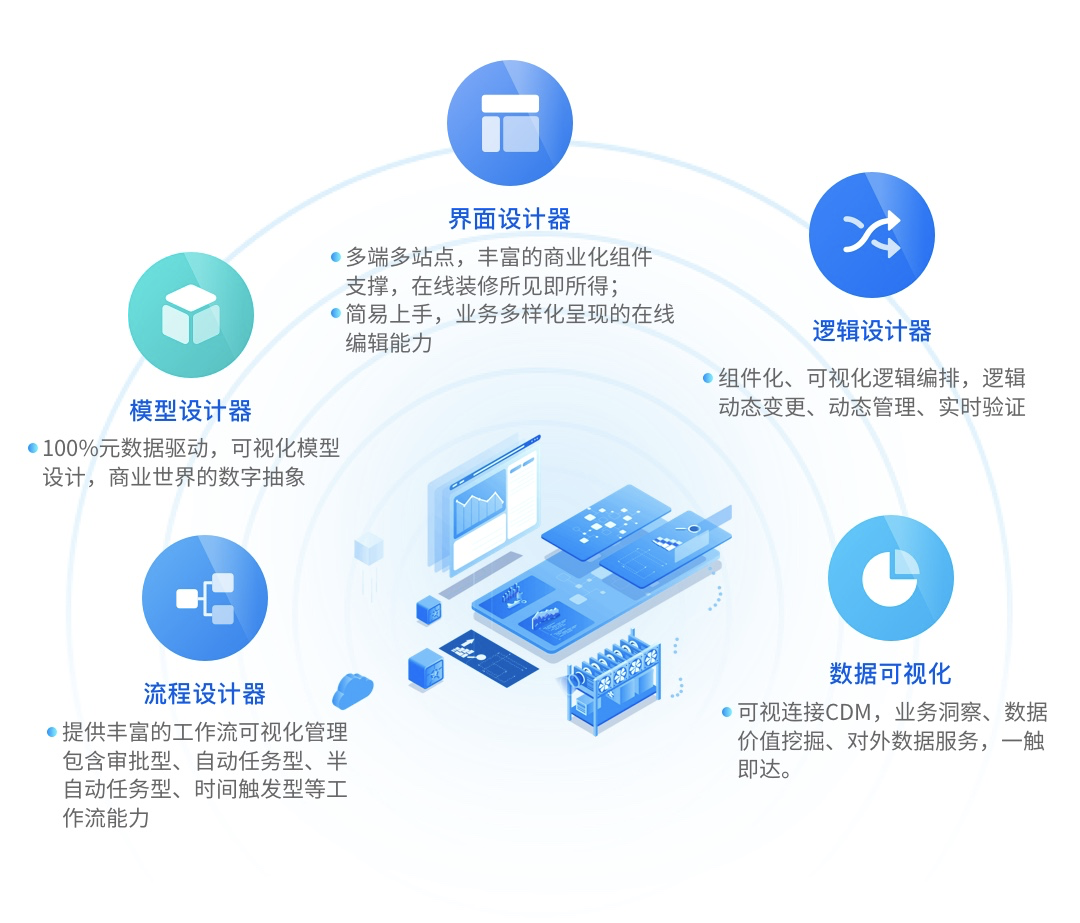

在数字化时代中国软件将接棒世界,而Oinone也要接棒Odoo,把数字化业务与技术的最佳实践赋能给企业,帮助企业数字化转型不走弯路!
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9211.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验