
在分布式开发中,每个人基本只负责自己相关的模块开发。所以每个研发就都需要一个环境,比如一般公司会有(N个)项目环境、1个日常环境、1个预发环境、1个线上环境。在整项目环境的时候就特别麻烦,oinone的好处是在于每个研发可以通过boot工程把需要涉及的模块都启动在一个jvm中进行开发,并不依赖任何环境,在项目开发中,特别方便。但当公司系统膨胀到一定规模,大到很多人都不知道有哪些模块,或者公司出于安全策略考虑,或者因为启动速度的原因(毕竟模块多了启动的速度也会降下来)。本文就给大家介绍oinone与经典分布式组织模式的兼容性
一、模块启动的最小集
我们来改造SecondModule模块,让该模块的用户权限相关都远程走DemoModule
Step1 修改SecondModule的启动工程application-dev.yml文件
除了base、second_core两个模块保留,其他模块都去除了。
pamirs:
boot:
init: true
sync: true
modules:
- base
- second_coreStep2 去除boot工程的依赖
去除SecondModule启动工程的pom依赖
<!-- <dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-resource-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-user-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-auth-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-message-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-international</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-business-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-apps-core</artifactId>
</dependency> -->Step3 重启SecondModule
这【远程模型】和【远程代理】均能访问正常
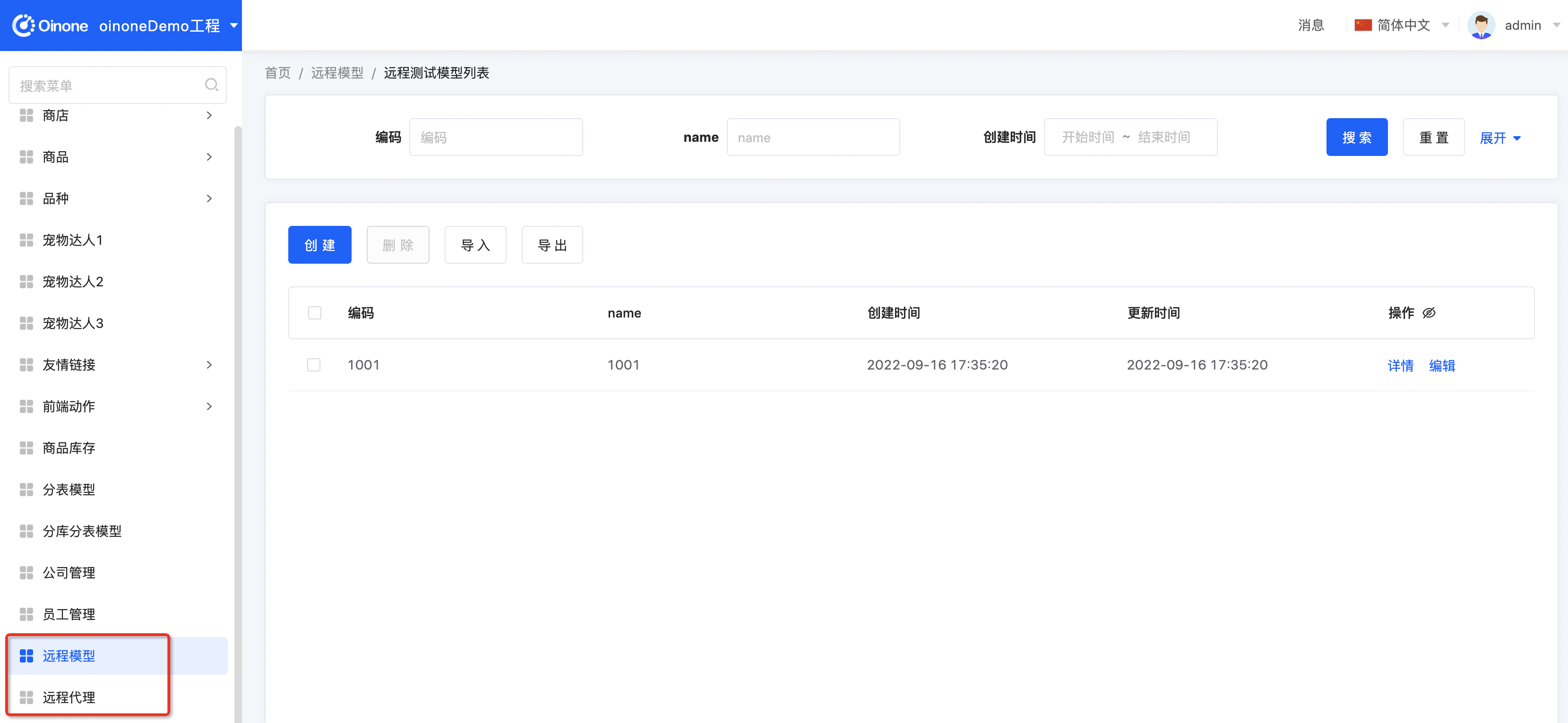

Step4 SecondModule增加对模块依赖
我们让SecondModule增加用户和权限模块的依赖,期待效果是:SecondModule会对用户和权限的访问都会走Dome应用,因为Demo模块的启动工程中包含了user、auth模块。
- 修改pamirs-second-api的pom文件增加对user和auth的api包依赖
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-user-api</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-auth-api</artifactId>
</dependency>- 修改SecondModule类,增加依赖定义
@Module(
dependencies = {ModuleConstants.MODULE_BASE, AuthModule.MODULE_MODULE, UserModule.MODULE_MODULE}
)Step5 修改RemoteTestModel模型
为RemoteTestModel模型增加user字段
@Field.many2one
@Field(displayName = "用户")
private PamirsUser user;Step6 重启系统看效果
-
mvn install pamirs-second工程,因为需要让pamirs-demo工程能依赖到最新的pamirs-second-api包
-
重启pamirs-second和pamirs-demo
-
两个页面都正常
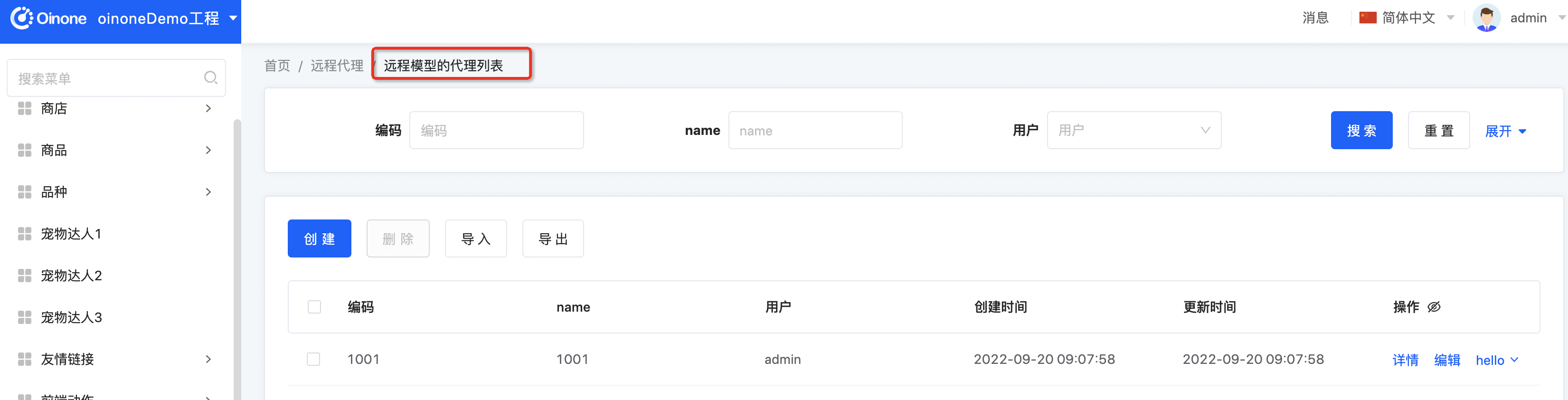
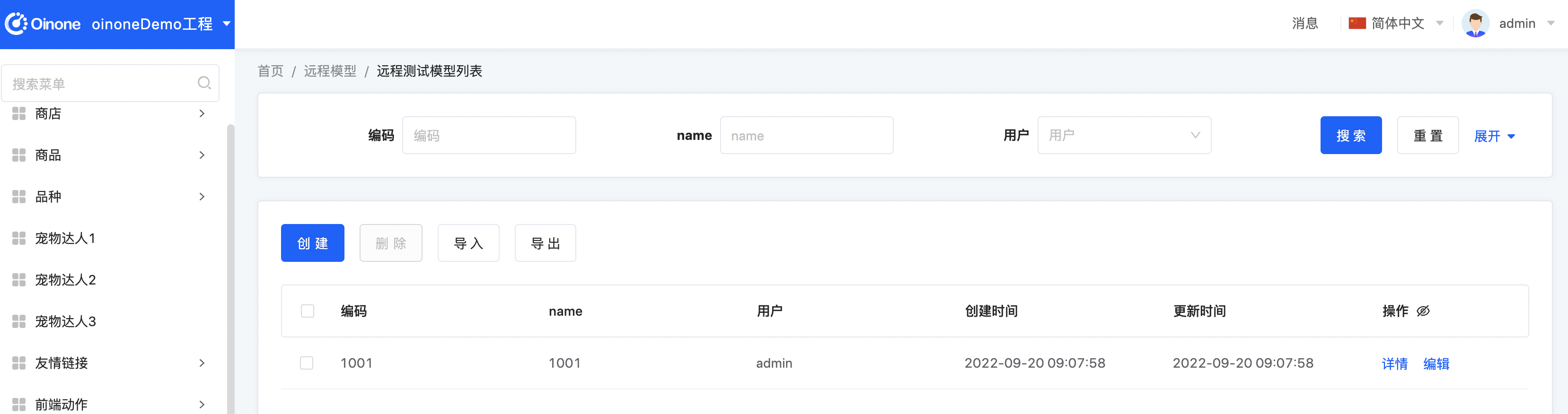
二、PmetaOnline的NEVER指令(开发时环境共享)
我们在4.1.2【模块之启动指令】一文中介绍过 “-PmetaOnline指令”,该参数用于设置元数据在线的方式,如果不使用该参数,则profile属性的默认值请参考服务启动可选项。-PmetaOnline参数可选项为:
- NEVER - 不持久化元数据,会将pamirs.boot.options中的updateModule、reloadMeta和updateMeta属性设置为false
- MODULE - 只注册模块信息,会将pamirs.boot.options中的updateModule属性设置为true,reloadMeta和updateMeta属性设置为false
- ALL - 注册持久化所有元数据,会将pamirs.boot.options中的updateModule、reloadMeta和updateMeta属性设置为true
oinone的默认模式下元数据都是注册持久化到DB的,但当我们在分布式场景下新开发模块或者对已有模块进行本地化开发时,做为开发阶段我们肯定是希望复用原有环境,但不对原有环境照成影响。那么-PmetaOnline就很有意义。让我们还没有经过开发自测的代码产生的元数据仅限于开发本地环境,而不是直接影响整个大的项目环境
PmetaOnline指令设置为NEVER(举例)
Step1 为DemoCore新增一个DevModel模型
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
@Model.model(DevModel.MODEL_MODEL)
@Model(displayName = "开发阶段模型",summary="开发阶段模型,当PmetaOnline指令设置为NEVER时,本地正常启动但元数据不落库",labelFields={"name"})
public class DevModel extends AbstractDemoCodeModel{
public static final String MODEL_MODEL="demo.DevModel";
@Field(displayName = "名称")
private String name;
}Step2 为DevModel模型配置菜单
@UxMenu("开发模型")@UxRoute(DevModel.MODEL_MODEL) class DevModelProxyMenu{}Step3 启动Demo应用时指定-PmetaOnline
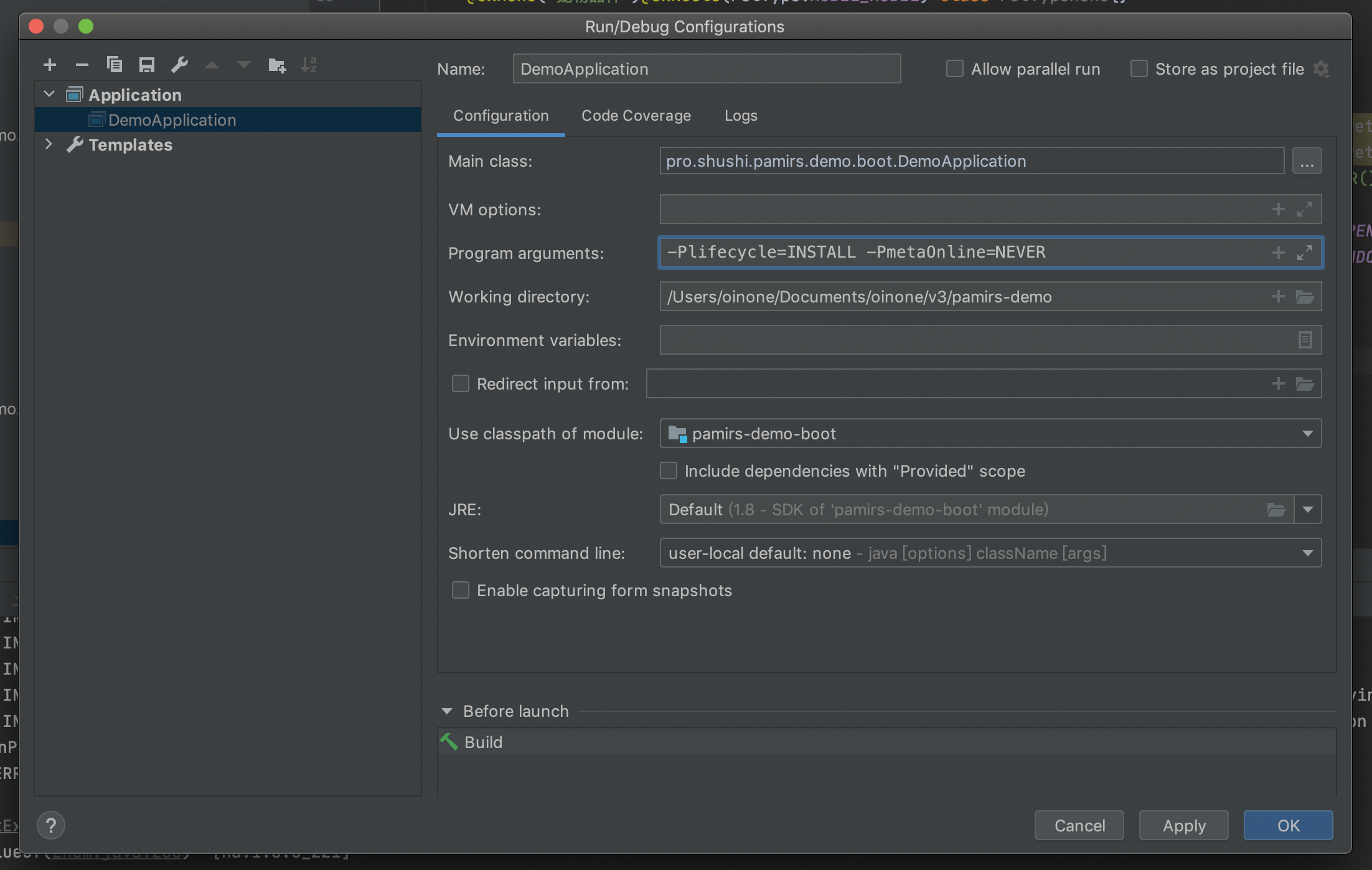
Step4 重启系统看效果
- 查看元数据
 图4-4-12 DB查看元数据变化
图4-4-12 DB查看元数据变化
- 菜单与页面能正常操作
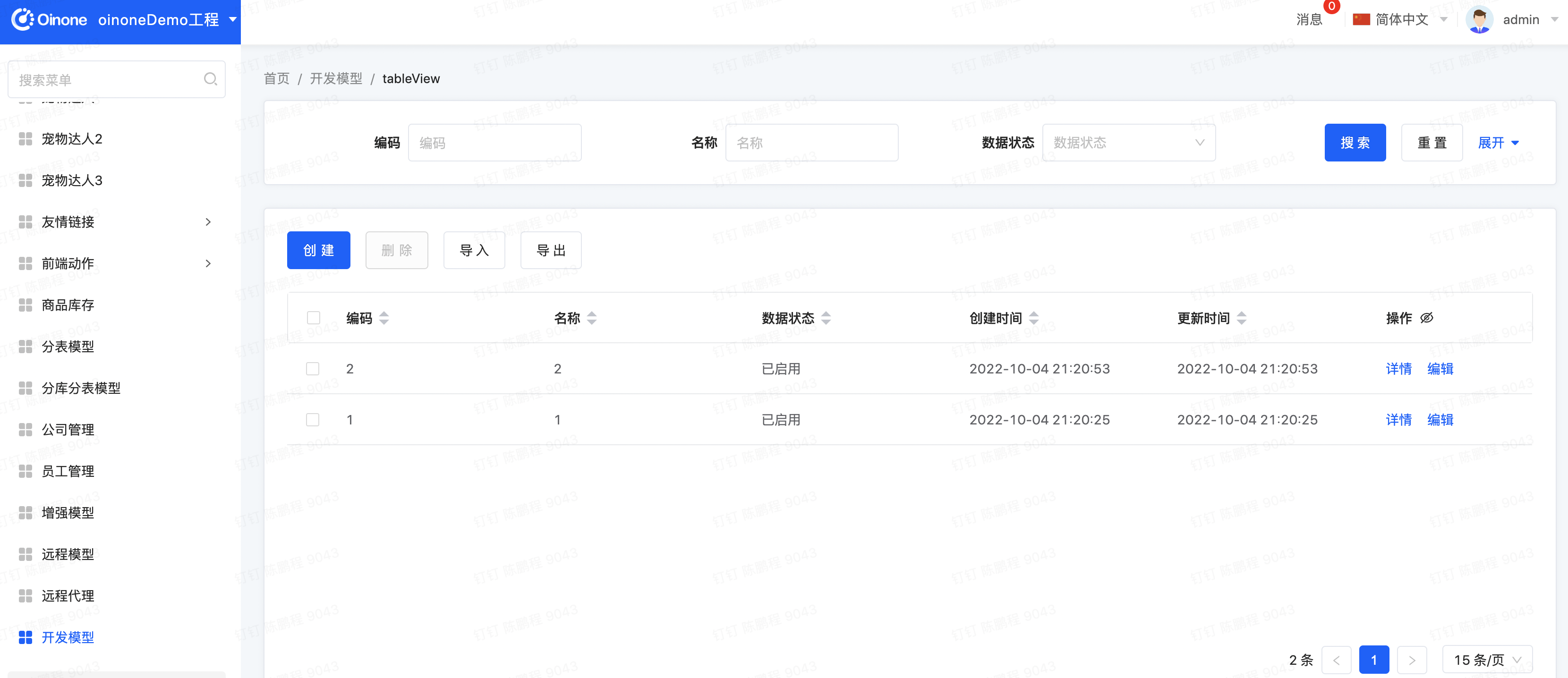
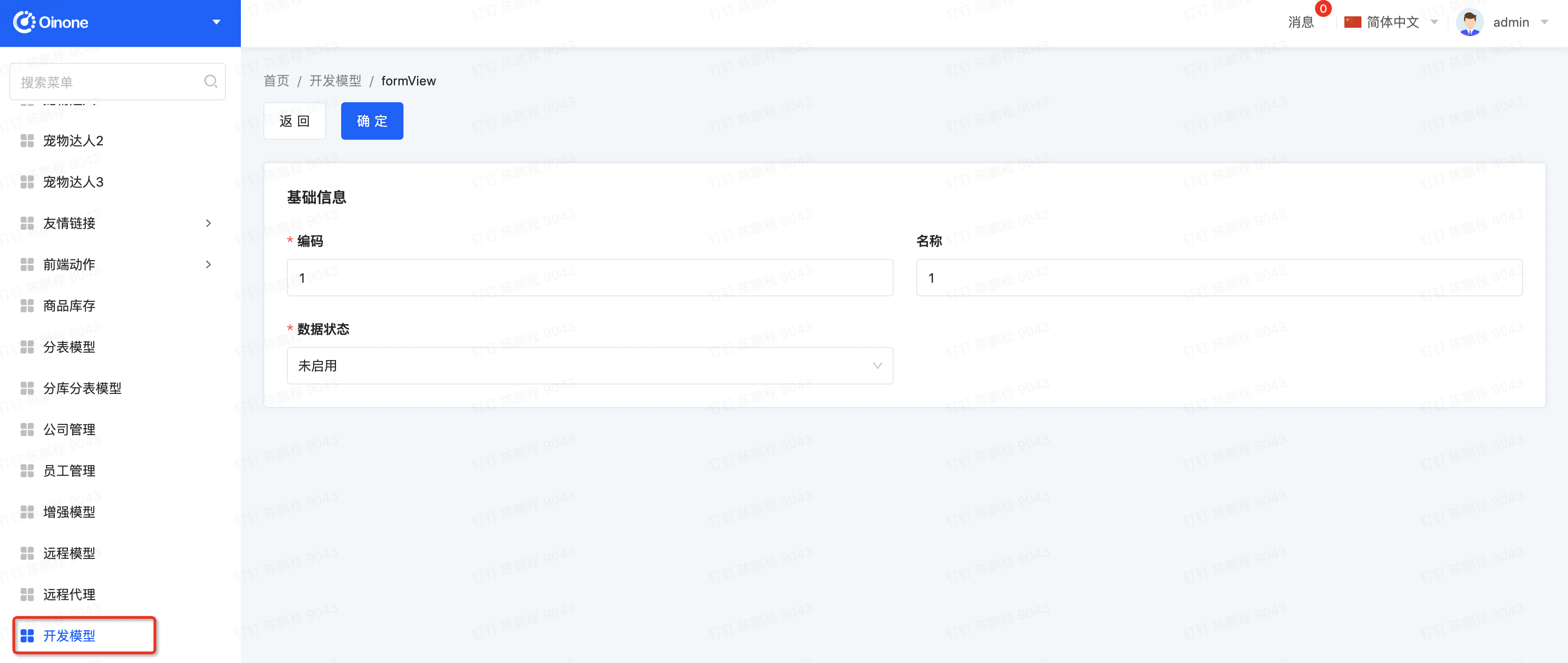
Step5 Never模式需注意的事项
-
业务库需设定为本地开发库,这样才不会影响公共环境,因为对库表结构的修改还是会正常进行的
-
如果不小心影响了公共环境,需要对公共环境进行重启恢复
-
系统新产生的元数据(如:例子中的【开发模式】菜单)不受权限管控
三、分布式开发约定
设计约定
-
跨模块的存储模型间继承,在部署时需要跟依赖模块配置相同数据源。这个涉及模块规划问题,比如业务上的user扩展模块,需要跟user模块一起部署。
-
跨模块的多对多关系,配置中间表模型,在3.3.9【字段类型之关系与引用】一文中的“M2M字段”部分有详细介绍。
-
基础依赖:base。
-
canal相关参考:4.1.10【函数之触发与定时】中提到的修改topic方案。
编码约定
-
跨模块间用service来调用,避免直接调用模型的数据管理器(如new 非本模块Model().queryPage等)。结构性代码可以用oinone提供研发辅助工具进行提效率
-
在3.4.1【构建第一个Function】一文中有提到,需要在API包中声明注解了@Fun注解的函数接口,并在接口的方法上加上@Function注解。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9311.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验