
模型字段是描述实体的特征属性,本文介绍重点介绍字段的基础类型与复合类型
使用@Field注解来描述模型的字段。如果未配置字段类型,系统会根据Java代码的字段声明类型来自动获取业务类型。建议配置displayName属性来描述字段在前端的显示名称。可以使用defaultValue配置字段的默认值。
一、安装与更新
使用@Field.field来配置字段的不可变更编码。字段一旦安装,无法在对该字段编码值进行修改,之后的字段配置更新会依据该编码进行查找并更新;如果仍然修改该注解的配置值,则系统会将该字段识别为新字段,存储模型会创建新的数据库表字段,而原字段将会rename为废弃字段。
二、字段类型
类型系统由基本类型、复合(组件)类型、引用类型和关系类型四种类型系统构成。通过类型系统描述应用程序、数据库和前端视觉视图如何进行交互,数据及数据间关系如何处理的协议。其中引用类型和关系类型介绍详见3.3.9【字段类型之关系与引用】一文,字段命名规范参见3.3.1【构建第一个Model】一文,这里不再赘述。
基本类型
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| BINARY | ByteByte[] | TINYINTBLOB | 二进制类型,不推荐使用 |
| INTEGER | ShortIntegerLongBigInteger | smallintintbigintdecimal(size,0) | 整数, 包括整数(10-11位有效数字)、长整数(19-20位有效数字)和大整数(超过19位)。【数据库规则】:默认使用int;如果size小于6则使用smallint;如果size超过6则使用int;如果size超过10位数字,即大于11(包含符号位),则使用长整数bigint;如果size超过19位数字,即大于20(包含符号位),则使用大数decimal。若未配置size,则按Java类型推测。【前端交互规则】:整数使用Number类型,长整数和大整数前后端协议使用字符串类型。 |
| FLOAT | FloatDoubleBigDecimal | float(M,D)double(M,D)decimal(M,D) | 浮点数,?包括单精度浮点数(7-8位有效数字)、双精度浮点数(15-16位有效数字)和大数(超过15位)。【数据库规则】:默认使用单精度浮点数float;如果size超过7位数字,即大于等于8,则使用双精度浮点数double;如果size超过15位数字,即大于等于16,则使用大数decimal。若未配置size,则按Java类型推测。【前端交互规则】:单精度浮点数float和双精度浮点数double使用Number类型(因为都使用IEEE754协议64位进行存储),大数前后端协议使用字符串类型。 |
| BOOLEAN | Boolean | tinyint(1) | 布尔类型,值为1,true(真)或0,false(假) |
| ENUM | Enum | 与数据字典指定基本类型一致 | 【前端交互规则】:可选项从ModelField的options字段获取,options字段值为字段指定数据字典子集的JSON序列化字符串。前后端传递的是可选项的name,数据库存储使用可选项的value。multi属性为true,则使用多选控件;multi属性为false,则使用单元控件 |
| STRING | String | varchar(size) | 字符串,size为长度限制默认值参考,前端可以view中覆盖该配置 |
| TEXT | String | text | 多行文本,编辑态组件为多行文本框,长度限制为配置项size值 |
| HTML | String | text | 富文本编辑器 |
| DATETIME | java.util.Datejava.sql.Timestamp | datetime(fraction)timestamp(fraction) | 日期时间类型【数据库规则】:日期和时间的组合,时间格式为?YYYY-MM-DD HH:MM:SS[.fraction],默认精确到秒,在默认的秒精确度上,可以带小数,最多带6位小数,即可以精确到?microseconds (6 digits) precision。可以通过设置fraction来设置精确小数位数,最终存储在字段的decimal属性上。【前端交互规则】:前端默认使用日期时间控件,根据日期时间类型格式化格式format格式化日期时间 |
| YEAR | java.util.Date | year | 年份类型日期类型【数据库规则】:默认“YYYY”格式表示的日期值【前端交互规则】:前端默认使用年份控件,根据日期类型格式化格式format格式化日期 |
| DATE | java.util.Datejava.sql.Date | datedate | 日期类型【数据库规则】:默认“YYYY-MM-DD”格式表示的日期值【前端交互规则】:前端默认使用日期控件,根据日期类型格式化格式format格式化日期 |
| TIME | java.util.Datejava.sql.Time | time(fraction)time(fraction) | 时间类型【数据库规则】:默认“HH:MM:SS”格式表示的时间值【前端交互规则】:前端默认使用时间控件,根据日期类型格式化格式format格式化日期 |
复合类型
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| MONEY | BigDecimal | decimal(M,D) | 金额,前端使用金额控件,可以使用currency设置币种字段 |
不可变更字段
使用immutable属性来描述该字段前后端都无法进行更新操作,系统会忽略不可变更字段的更新操作。
自动生成编码的字段
详见3.3.5【模型编码生成器】一文。
字段的序列化与反序列化
使用@Field注解的serialize属性来配置非字符串类型属性的序列化与反序列化方式,最终会以序列化后的字符串持久化到存储中。
详见3.3.7【字段之序列化方式】一文
前端默认配置
可以使用@Field注解中的以下属性来配置前端的默认视觉与交互规则,也可以在前端设置覆盖以下配置。
-
@Field(required),是否必填
-
@Field(invisible),是否不可见
-
@Field(priority),字段优先级,列表的列使用该属性进行排序
-
更多前端默认视图配置详见:3.5.4【Ux注解详解】一文,如:readonly是否只读等。
举例
回顾我们前面学习例子
现有PetShop代码如下
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.core.common.enmu.DataStatusEnum;
import pro.shushi.pamirs.demo.api.enumeration.PetShopOptionEnum;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import java.sql.Time;
import java.util.List;
@Model.model(PetShop.MODEL_MODEL)
@Model(displayName = 宠物店铺,summary=宠物店铺,labelFields ={shopName} )
@Model.Code(sequence = DATE_ORDERLY_SEQ,prefix = P,size=6,step=1,initial = 10000,format = yyyyMMdd)
public class PetShop extends AbstractDemoIdModel {
public static final String MODEL_MODEL=demo.PetShop;
@Field(displayName = 店铺编码)
private String code;
@Field(displayName = 店铺编码2)
@Field.Sequence(sequence = DATE_ORDERLY_SEQ,prefix = C,size=6,step=1,initial = 10000,format = yyyyMMdd)
private String codeTwo;
@Field(displayName = 店铺名称,required = true)
private String shopName;
@Field(displayName = 开店时间,required = true)
private Time openTime;
@Field(displayName = 闭店时间,required = true)
private Time closeTime;
@Field(displayName = 店铺标志)
private List options;
}
字段默认推断
我们从PetShop代码中会发现
-
很多字段类型是由oinone根据模型中的java类型自动推断,详见4.1.6中的【类型默认推断】。
-
大部分字段我只是简单加了@Field(displayName)注解,详见4.1.6中的【字段元数据详解】。
新增未涉及基础字段以及其他注解配置
-
为PetShop新增FLOAT、BOOLEAN、TEXT、HTML、YEAR、DATE、MONEY等字段
-
设置shopName字段为immutable=true
-
给MONEY类型字段,income配置@Field(priority = 1)
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.core.common.enmu.DataStatusEnum;
import pro.shushi.pamirs.demo.api.enumeration.PetShopOptionEnum;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.DateFormatEnum;
import pro.shushi.pamirs.meta.enmu.DateTypeEnum;
import java.math.BigDecimal;
import java.sql.Time;
import java.util.Date;
import java.util.List;
@Model.model(PetShop.MODEL_MODEL)
@Model(displayName = "宠物店铺",summary="宠物店铺",labelFields ={"shopName"} )
@Model.Code(sequence = "DATE_ORDERLY_SEQ",prefix = "P",size=6,step=1,initial = 10000,format = "yyyyMMdd")
public class PetShop extends AbstractDemoIdModel {
public static final String MODEL_MODEL="demo.PetShop";
@Field(displayName = "店铺编码")
private String code;
@Field(displayName = "店铺编码2")
@Field.Sequence(sequence = "DATE_ORDERLY_SEQ",prefix = "C",size=6,step=1,initial = 10000,format = "yyyyMMdd")
private String codeTwo;
@Field(displayName = "店铺名称",required = true,immutable=true)
private String shopName;
@Field(displayName = "开店时间",required = true)
private Time openTime;
@Field(displayName = "闭店时间",required = true)
private Time closeTime;
@Field.Enum
@Field(displayName = "数据状态",defaultValue = "DRAFT",required = true,summary = "枚举可选项举例")
private DataStatusEnum dataStatus;
@Field(displayName = "店铺标志")
private List<PetShopOptionEnum> options;
@Field(displayName = "一年内新店")
private Boolean oneYear;
@Field.Float
@Field(displayName = "店内员工平均年龄")
private BigDecimal averageAge;
@Field.Text
@Field(displayName = "描述")
private String description;
@Field.Html
@Field(displayName = "html描述")
private String descHtml;
@Field.Date(type = DateTypeEnum.DATE,format = DateFormatEnum.DATE)
@Field(displayName = "店庆")
private Date anniversary;
@Field.Date(type = DateTypeEnum.YEAR,format = DateFormatEnum.YEAR)
@Field(displayName = "开店年份")
private Date publishYear;
@Field.Money
@Field(displayName = "收入",priority = 1)
private BigDecimal income;
}- 重启应用看效果
a. 在商店管理A菜单下,点击数据记录的【修改】操作进入编辑页面,发现以下几点
ⅰ. 【收入】字段排序靠前
ⅱ. 其他新增基础类型字段,前端提供默认组件展示
ⅲ. html描述控件的图片上传会报错,需要引入File模块,请详见6.1【文件与导入导出】一文
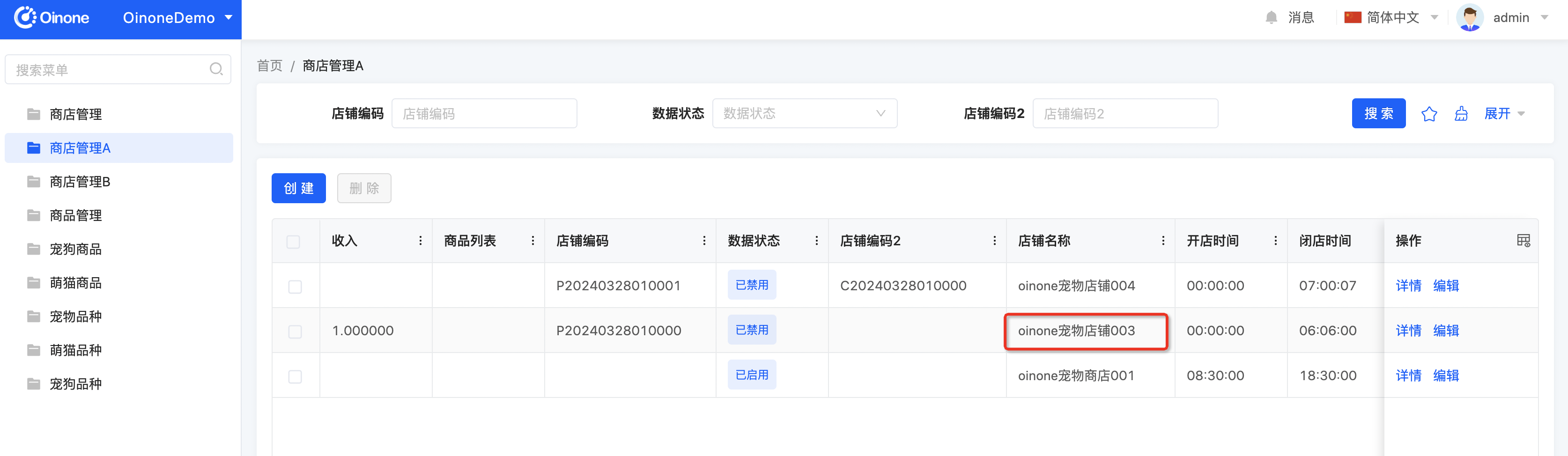
b.返回列表页查看数据,发现只有店铺名称的修改被忽略了,其他字段都赋值成功
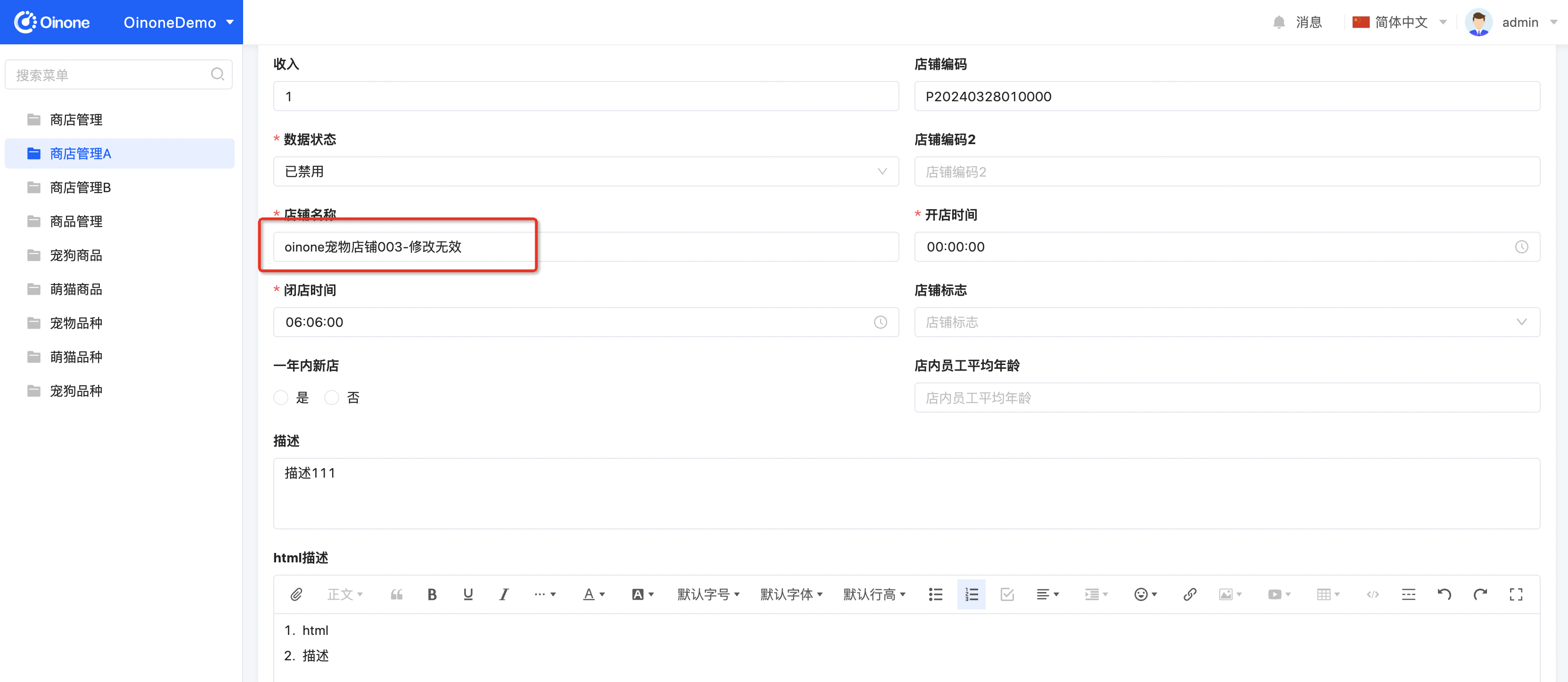
 图3-3-8-3 商店管理-编辑页
图3-3-8-3 商店管理-编辑页
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9239.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验