
如果把互联网架构比作社会主义,Oinone就是也要做有中国特色的社会主义,才能符合国情。
随着业务和生态的发展,企业对效率、性能、体验和智能化等方面的要求越来越高,但很多企业的系统面临着严重的系统架构落后和系统间割裂等问题,这些问题导致原有系统在业务发展下面临着效率和性能的双重挑战。与此同时,互联网平台的技术水平远远领先于传统企业系统,但是是否可以直接将互联网架构照搬到企业数字化转型中呢?显然,这是不合适的,因为互联网架构在企业数字化转型中面临着许多水土不服的问题。本章节将结合互联网中台架构的发展,分析这些问题的原因。
借鉴互联网中台理念
我们要先看互联网架构的发展,是如何一步步到今天提的中台架构概念的,每一步又解决了什么具体问题,我们以阿里架构变迁史为例来看下(如下图2-2所示):
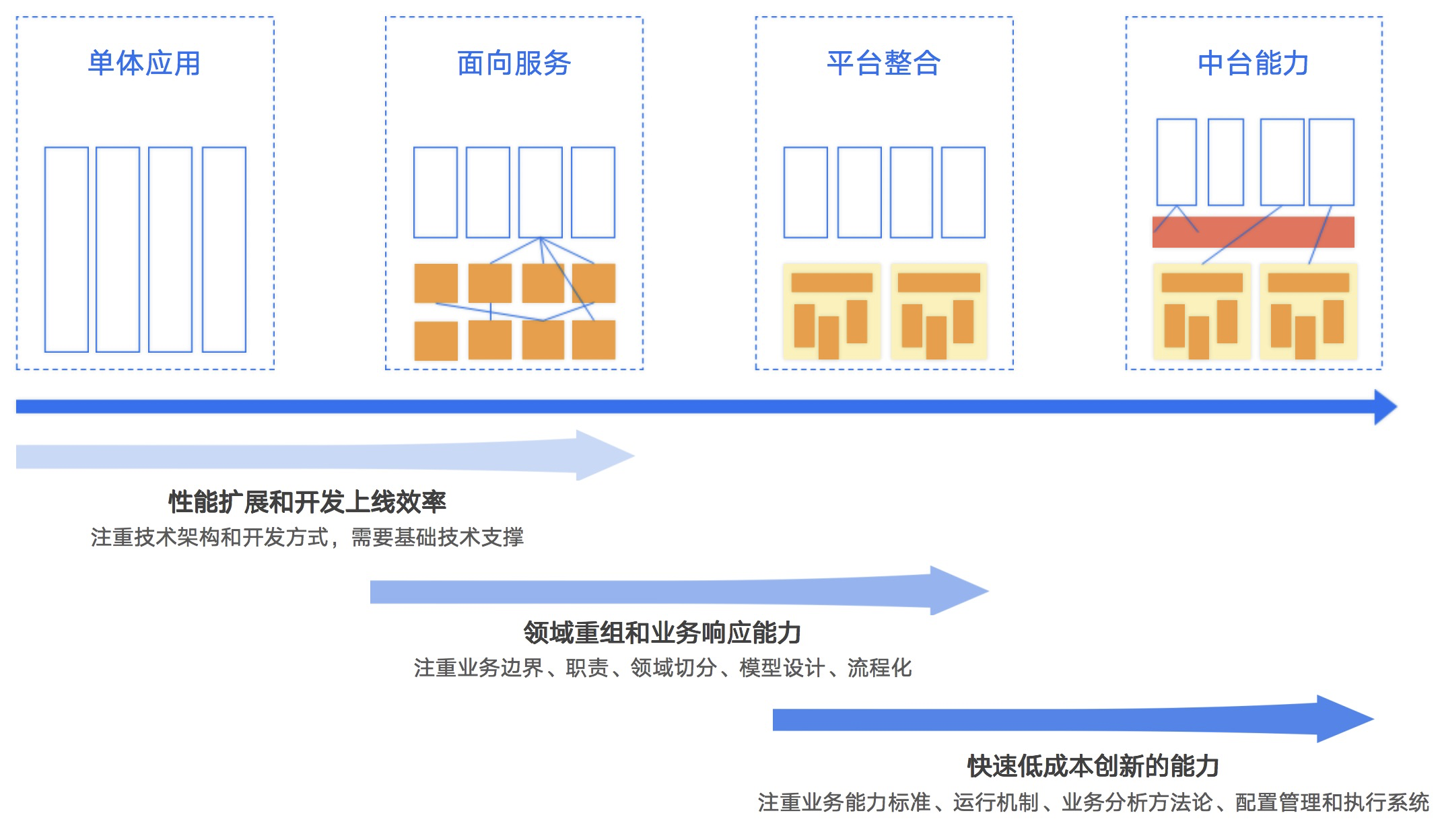

在2009年,淘宝上线了五彩石项目,这标志着淘宝从单体应用向服务化应用的时代迈出了一步。那么,淘宝为什么要开发五彩石项目呢?因为当时淘宝面临两个非常严峻的问题,一个是性能问题,数据库连接不足,数据库成为了瓶颈;另一个是效率问题,当时淘宝有百余个研发人员,但核心系统只有一套测试、预发、线上环境,导致研发需求排队等待。在开始五彩石项目之前,淘宝还做了千岛湖项目,用来验证服务化架构的可行性,将用户中心独立出来。随后,淘宝开启了五彩石项目,目标是通过增加人力来提升效率,通过增加机器来提升性能。
随着淘宝的业务发展,他们又面临了一个问题:各个服务之间有很多重复的建设,效率低下。为了解决这个问题,淘宝开始从服务化转向平台化,并创立了“共享业务事业部”,将重复建设的公共业务分配给这个事业部,以避免成本浪费。这些公共业务包括商品平台、交易平台和结算平台等。平台化的目标是规避服务化没有规划导致的重复建设问题。
但是随着业务的快速发展,淘宝变成了一个拥有几十个事业部的巨型企业,而这带来了新的问题:效率问题。例如,如果需要在一个业务线上做出改动,需要与十几个平台进行沟通,这是非常低效的。同时,对于一个平台来说,需要面对来自不同事业部的需求,这需要平台研发人员具备理解和抽象所有业务线需求的能力,这让平台研发人员感觉回到了单体应用时代,所有的需求都要排队,即使增加人力也无法提高效率。这个问题主要表现在交易平台上。
为了解决这个问题,淘宝提出了中台的概念,中台是在一套规范下建立的,让具有专业技能的团队自主决策业务系统发展的平台。中台的目标是弱化平台的业务特性,提供通用能力。简而言之,就是将“共享业务”中的“业务”两个字去掉,只提供通用能力的平台
我们将每个阶段的核心目标总结为一句话:
-
从单体到服务:通过增加人员和机器来提高效率和性能;
-
从服务化到平台化:解决服务化阶段因缺乏规划而导致的重复建设问题;
-
平台化到中台化:在一套规范下,让各业务团队自行决定业务系统发展,适用于多个业务线或多个场景应用的独立发展。
类似地,在企业数字化转型过程中,也面临着类似的问题:
-
随着企业业务在线化,对系统性能和稳定性提出了更高的要求,但由于内部系统之间的割裂,导致很多重复建设。因此,我们需要进行服务化和平台化;
-
没有一个供应商能够解决企业所有的商业场景问题,所以需要多个供应商共同参与。我们可以将供应商类比为各业务线,在一套规范下让供应商或业务线自行决定业务系统的发展。
然而,阿里的中台架构方案并不能直接照搬到企业中。因为阿里的中台架构采用了平台共建模式,即让业务线基于平台设计的规范共同开发。这本质上还是平台主导模式,对企业来说历史包袱较大。在企业中,让不同背景的研发一起共建交易或商品平台是非常复杂的事情。平台化已经足够复杂,再加上共建会导致企业架构的负载过重,这对企业来说就不再是赋能,而是“内耗”。
互联网中台架构在企业实践中遇到的问题
在1.3《Oinone的生态思考》一文中,《与中台的渊源》部分提到,在阿里云为企业提供数字化项目时,客户经常会对以下三个问题提出质疑,这些问题非常突出:
1我们听说你们具备敏捷响应能力,但为什么改动需求如此缓慢?不仅所需时间更长,而且成本更高?
2我们听说你们有能力中心,但为什么当我们引入新供应商或开发新场景时,前期建立的能力中心无法支持我们?
3我们听说你们的性能很好,但为什么我们需要投入更多的物理资源来支持项目?
在探讨互联网架构的适用性时,我想提出以下两个问题:
1企业应用程序的性能问题是否与互联网平台公司遇到的性能问题相同?
2企业应用程序的开发效率问题是否与互联网平台公司遇到的效率问题相同?
通过比较企业和互联网之间的差异,我们可以了解水土不服的核心原因。
| 企业 | 互联网 |
|---|---|
| 企业IT组织能力无法与数字化转型的速度匹配,缺乏足够的人才支持。为了提高开发效率,企业需要寻找工具和技术来降低开发难度,同时提高个人开发效率 | 互联网企业拥有众多优秀的人才,需要解决团队协作和知识共享的问题,即协同开发的效率。 |
| 企业无法制定并主导技术规范,这导致了能力复用的不足。为了提高效率和减少开发成本,企业需要建立统一的技术规范和标准,以便能力复用和组织协同。 | 互联网企业可以自定义技术规范,因此能力复用更易于保障。 |
| 企业往往当前业务量相对小,期望数字化建设能打动业务发展,对业务发展的预期比较高,所以企业的诉求是即满足当下成本效应又能兼顾未来对发展预期 | 互联网企业起步时的系统目标负载就高,通常会忽略资源起步门槛的问题,当然也可以通过自动扩容、云计算等方式来解决初期的负载问题。 |
我们可以看到企业和互联网架构在很多方面存在着不同的需求和问题。因此,在提供数字化服务时,Oinone需要注意与企业的组织能力进行匹配,并根据企业自身的特性来提供在线化的服务能力。这就像在社会主义制度下需要有中国特色一样,Oinone也需要有适合中国企业的特色。
Oinone社区 作者:史, 昂原创文章,如若转载,请注明出处:https://doc.oinone.top/oio4/9217.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验