
流程概览依赖说明
使用 流程概览 功能前,需要在项目中引入 pamirs-workflow-datavi-core、 pamirs-data-visualization-core依赖,并启动datavi模块:
<dependency>
<groupId>pro.shushi.pamirs.workflow</groupId>
<artifactId>pamirs-workflow-datavi-core</artifactId>
</dependency><dependency>
<groupId>pro.shushi.pamirs.data.visualization</groupId>
<artifactId>pamirs-data-visualization-core</artifactId>
</dependency>
警告: 在 oinone 平台启用「流程概览」能力时,应用启动模块一旦引入
pamirs-workflow-api/core,必须同时引入 pamirs-workflow-datavi-api/core。在多启动模块架构下,严禁出现仅部分启动模块引入 pamirs-workflow-core 而未引入 pamirs-workflow-datavi-core 的情况,否则将导致流程概览相关元数据计算异常,出现删表等情况。流程概览配置项
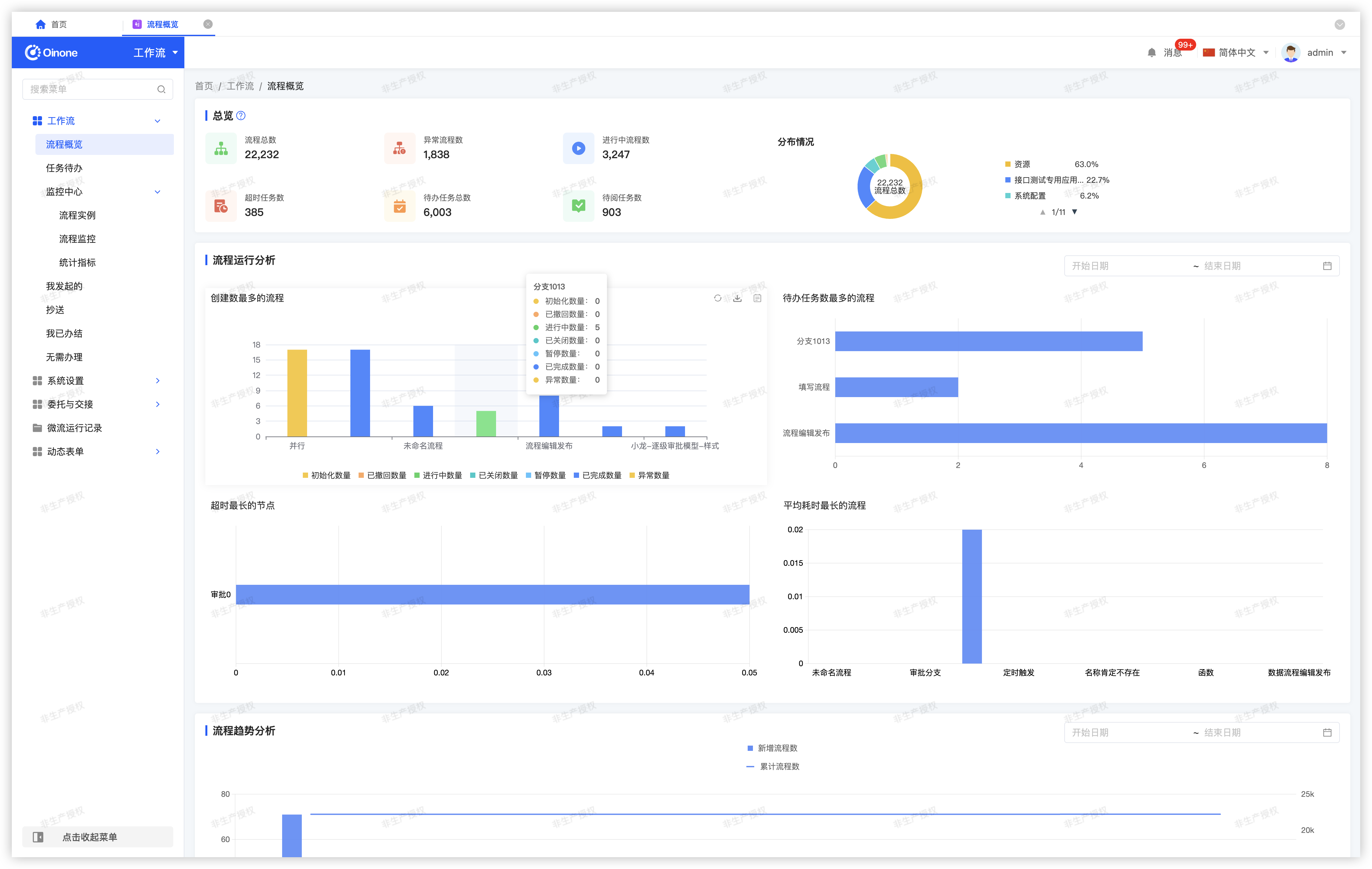

流程概览页面内置缓存机制,可通过配置项调整缓存刷新周期及图表展示的数据条数:
pamirs:
workflow:
dashboard:
cache-time: 10 # 流程概览缓存刷新时间(单位:分钟),默认 10 分钟
page-size: 10 # 流程运行分析中 4 个图表的展示数量,默认查询前 10 条数据统计指标说明
引入 pamirs-workflow-datavi-core 依赖后,系统会按照以下规则进行数据同步:
- 当日数据同步:每小时同步一次当日数据;
- 昨日数据同步:次日凌晨同步前一日数据。
由于在引入依赖后才会开始执行数据同步,统计指标页提供了「同步」按钮,可用于对历史数据进行补采。即使不执行历史同步,也不会影响核心业务流程,仅会影响统计数据和图表的展示效果。
统计指标数据主要用于
- 支撑 流程概览 和 流程监控 中的统计图表展示;
- 为数据分析与可视化提供基础数据。
上述统计数据对工作流的审批、流转等核心业务无任何影响。如有需要,也可以基于流程监控的数据,配合数据可视化设计器,自定义构建符合业务需求的展示页面。
Oinone社区 作者:夜神月原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/25098.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验