
概述
Oinone平台为合作伙伴提供了环境保护功能,以确保在一套环境可以在较为安全前提下修改配置文件,启动多个JVM等部署操作。
本章内容主要介绍与环境保护功能相关的启动参数。
名词解释
- 本地开发环境:开发人员在本地启动业务工程的环境
- 公共环境:包含设计器镜像和业务工程的环境
环境保护参数介绍
【注意】参数是加在程序实参 (Program arguments)上,通常可能错误的加在Active Profiles上了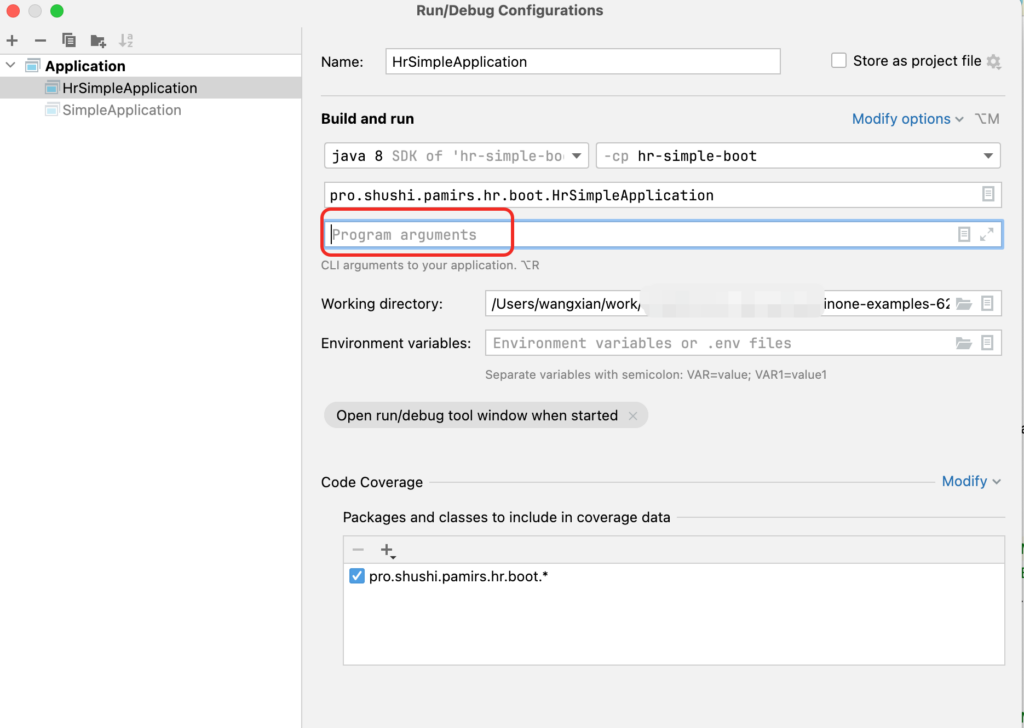

-PenvProtected=${value}
是否启用环境保护,默认为true。
环境保护是通过与最近一次保存在数据库的base_platform_environment表中数据进行比对,并根据每个参数的配置特性进行判断,在启动时将有错误的内容打印在启动日志中,以便于开发者进行问题排查。
除此之外,环境保护功能还提供了一些生产配置的优化建议,开发者可以在启动时关注这些日志,从而对生产环境的配置进行调优。
-PsaveEnvironments=${value}
是否将此次启动的环境参数保存到数据库,默认为true。
在某些特殊情况下,为了避免公共环境中的保护参数发生不必要的变化,我们可以选择不保存此次启动时的配置参数到数据库中,这样就不会影响其他JVM启动时发生校验失败而无法启动的问题。
-PstrictProtected=${value}
是否使用严格校验模式,默认为false
通常我们建议在公共环境启用严格校验模式,这样可以最大程度的保护公共环境的元数据不受其他环境干扰。
PS:在启用严格校验模式时,需避免内外网使用不同连接地址的场景。如无法避免,则无法启用严格校验模式。
常见问题
需要迁移数据库,并更换了数据库连接地址该如何操作?
- 将原有数据库迁移到新数据库。
- 修改配置文件中数据库的连接地址。
- 在启动脚本中增加
-PenvProtected=false关闭环境保护。 - 启动JVM服务可以看到有错误的日志提示,但不会中断本次启动。
- 移除启动脚本中的
-PenvProtected=false或将值改为true,下次启动时将继续进行环境保护检查。 - 可查看数据库中
base_platform_environment表中对应数据库连接配置已发生修改,此时若其他JVM在启动前未正确修改,则无法启动。
本地开发时需要修改Redis连接地址到本地,但希望不影响公共环境的使用该如何操作?
PS:由于Redis中的元数据缓存是根据数据库差量进行同步的,此操作会导致公共环境在启动时无法正确刷新Redis中的元数据缓存,需要配合pamirs.distribution.session.allMetaRefresh参数进行操作。如无特殊必要,我们不建议使用该形式进行协同开发,多次修改配置会导致出错的概率增加。
- 本地环境首次启动时,除了修改Redis相关配置外,还需要配置
pamirs.distribution.session.allMetaRefresh=true,将本地新连接的Redis进行初始化。 - 在本地启动时,增加
-PenvProtected=false -PsaveEnvironments=false启动参数,以确保本地启动不会修改公共环境的配置,并且可以正常通过环境保护检测。 - 本地环境成功启动并正常开发功能后,需要发布到公共环境进行测试时,需要先修改公共环境中业务工程配置
pamirs.distribution.session.allMetaRefresh=true后,再启动业务工程。 - 启动一次业务工程后,将配置还原为
pamirs.distribution.session.allMetaRefresh=false。
Oinone社区 作者:张博昊原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/18451.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验