
模版示例: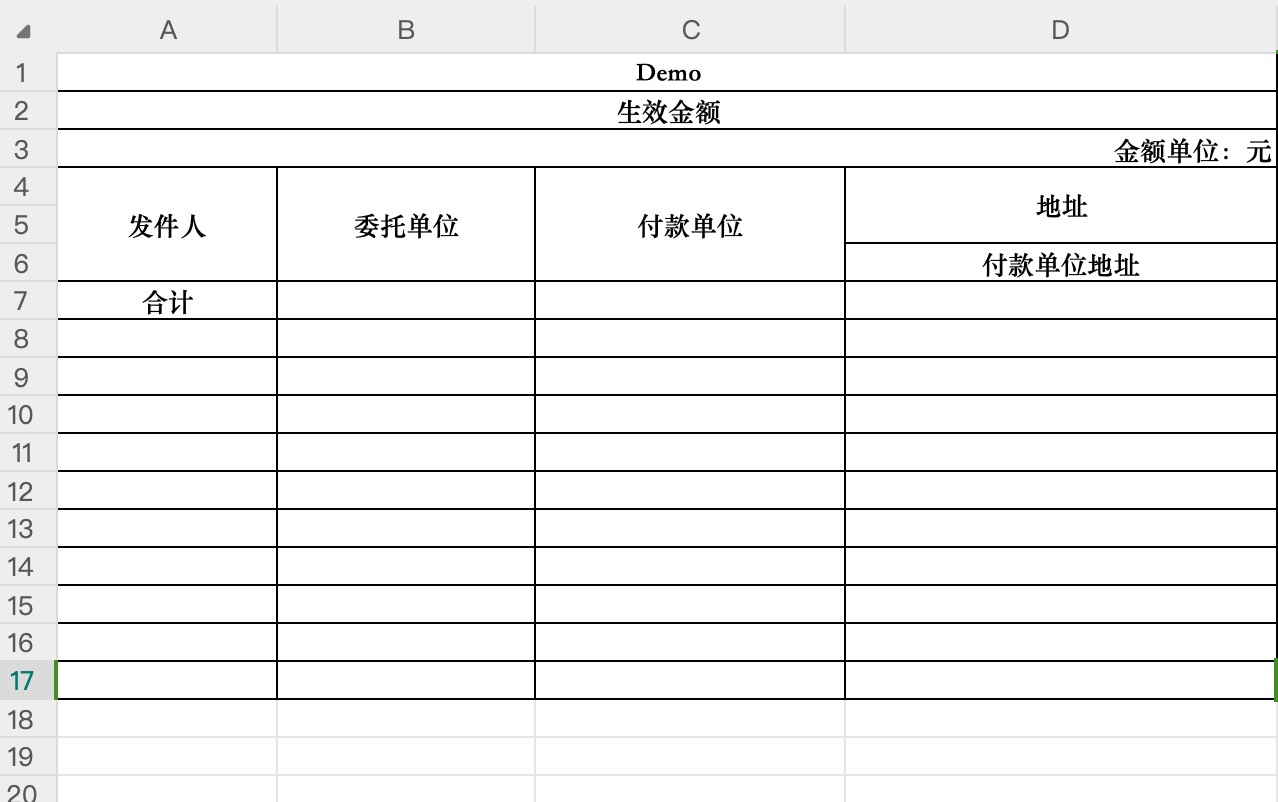

代码示例:
@Model.model(TestApply.MODEL_MODEL)
@Model(displayName = "测试申请")
public class TestApply extends IdModel {
public static final String MODEL_MODEL = "top.TestApply";
@Field.String
@Field(displayName = "发件人")
private String addresser;
@Field.String
@Field(displayName = "委托单位")
private String entrustedUnit;
@Field.String
@Field(displayName = "付款单位")
private String payer;
@Field.String
@Field(displayName = "付款单位地址")
private String paymentUnitAdd;
}模版:
package pro.shushi.pamirs.top.core.temp;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.file.api.builder.SheetDefinitionBuilder;
import pro.shushi.pamirs.file.api.builder.WorkbookDefinitionBuilder;
import pro.shushi.pamirs.file.api.enmu.ExcelAnalysisTypeEnum;
import pro.shushi.pamirs.file.api.enmu.ExcelDirectionEnum;
import pro.shushi.pamirs.file.api.enmu.ExcelHorizontalAlignmentEnum;
import pro.shushi.pamirs.file.api.model.ExcelWorkbookDefinition;
import pro.shushi.pamirs.file.api.util.ExcelHelper;
import pro.shushi.pamirs.file.api.util.ExcelTemplateInit;
import pro.shushi.pamirs.top.api.model.TestApply;
import java.util.Collections;
import java.util.List;
@Component
public class DemoTemplate implements ExcelTemplateInit {
public static final String TEMPLATE_NAME = "DemoTemplate";
@Override
public List<ExcelWorkbookDefinition> generator() {
WorkbookDefinitionBuilder builder = WorkbookDefinitionBuilder.newInstance(TestApply.MODEL_MODEL, TEMPLATE_NAME)
.setDisplayName("测试Demo");
DemoTemplate.createSheet(builder);
return Collections.singletonList(builder.build());
}
private static void createSheet(WorkbookDefinitionBuilder builder) {
SheetDefinitionBuilder sheetBuilder = builder.createSheet().setName("测试Demo");
buildBasicInfo(sheetBuilder);
}
private static void buildBasicInfo(SheetDefinitionBuilder builder) {
//A1:D8:表示表头占的单元格数,范围必须大于实际表头行
BlockDefinitionBuilder mergeRange = builder.createBlock(TestApply.MODEL_MODEL, ExcelAnalysisTypeEnum.FIXED_HEADER, ExcelDirectionEnum.HORIZONTAL, "A1:D8")
//预设行
.setPresetNumber(10)
//合并哪几个单元格
.createMergeRange("A1:D1")
.createMergeRange("A2:D2")
.createMergeRange("A3:D3")
.createMergeRange("A4:A6")
.createMergeRange("B4:B6")
.createMergeRange("C4:C6")
.createMergeRange("D4:D5");
//createHeader创建行,createCell创建单元格,setField指定解析字段,setIsConfig指定为true标记该行是需要解析的值
mergeRange.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle()).setIsConfig(Boolean.TRUE)
.createCell().setField("addresser").setStyleBuilder(ExcelHelper.createDefaultStyle().setWidth(6000)).and()
.createCell().setField("entrustedUnit").and()
.createCell().setField("payer").and()
.createCell().setField("paymentUnitAdd").and()
.and()
.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(typeface -> typeface.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.CENTER))
.createCell().setValue("Demo").and()
.createCell().and()
.createCell().and()
.createCell().and()
.and()
//由于该行合并为一个单元格,所以其他可以不设置value
.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(typeface -> typeface.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.CENTER))
.createCell().setValue("生效金额").and()
.createCell().and()
.createCell().and()
.createCell().and()
.and()
.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(typeface -> typeface.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.RIGHT))
.createCell().setValue("金额单位:元").and()
.createCell().and()
.createCell().and()
.createCell().and()
.and()
//easyExcel解析不了空行,所以这里写上值。由于上面使用createMergeRange把单元格合并了,并且D列有分割,这里填上每个单元格的值,把合并的单元格填为一样的。
.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(typeface -> typeface.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.CENTER))
.createCell().setValue("发件人").and()
.createCell().setValue("委托单位").and()
.createCell().setValue("付款单位").and()
.createCell().setValue("地址").and()
.and()
.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(typeface -> typeface.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.CENTER))
.createCell().setValue("发件人").and()
.createCell().setValue("委托单位").and()
.createCell().setValue("付款单位").and()
.createCell().setValue("地址").and()
.and()
.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(typeface -> typeface.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.CENTER))
.createCell().setValue("发件人").and()
.createCell().setValue("委托单位").and()
.createCell().setValue("付款单位").and()
.createCell().setValue("付款单位地址").and()
.and()
.createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(typeface -> typeface.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.CENTER))
.createCell().setValue("合计").and()
.createCell().and()
.createCell().and()
.createCell();
}
}
注意:链式调用不可以太长,如果太长可以使用参数接一下,否则在编译时可能会导致栈溢出。
Oinone社区 作者:yexiu原创文章,如若转载,请注明出处:https://doc.oinone.top/dai-ma-shi-jian/19462.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验