
-
在模型里面建一个非存储字段,用来传输工作流用户任务待办ID。
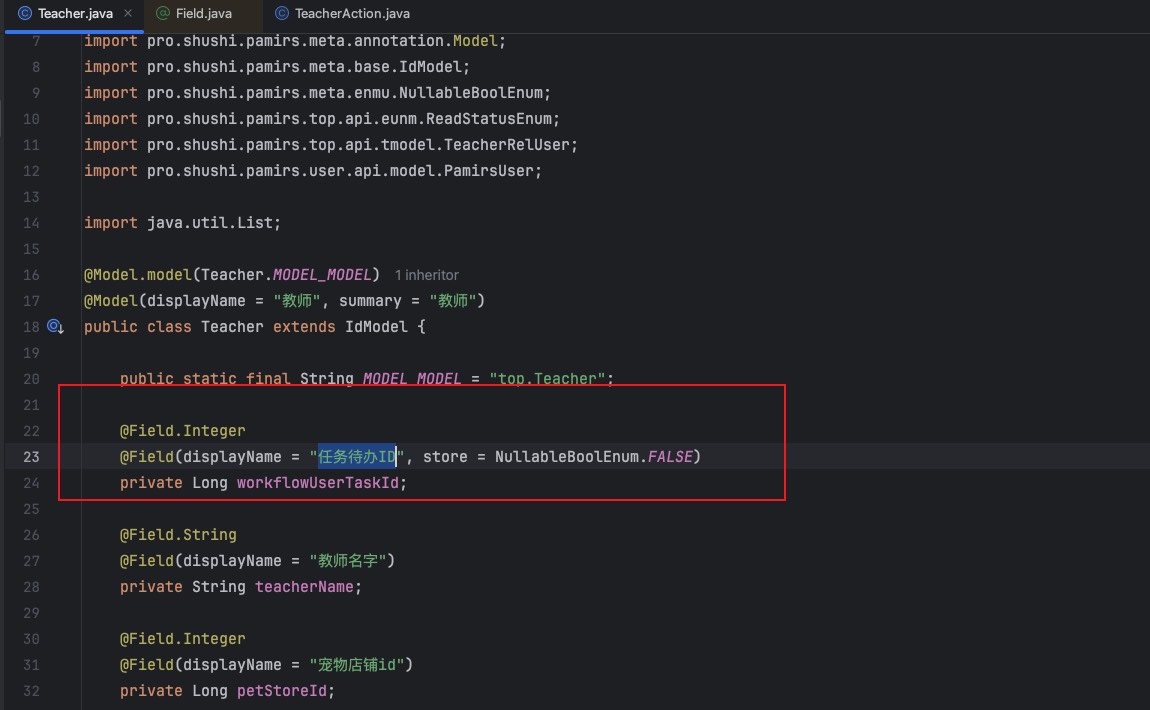
 。
。 -
界面设计器把这个字段拖到列表页里,并在跳转动作上配置上下文参数,把任务待办id传到表单页里。
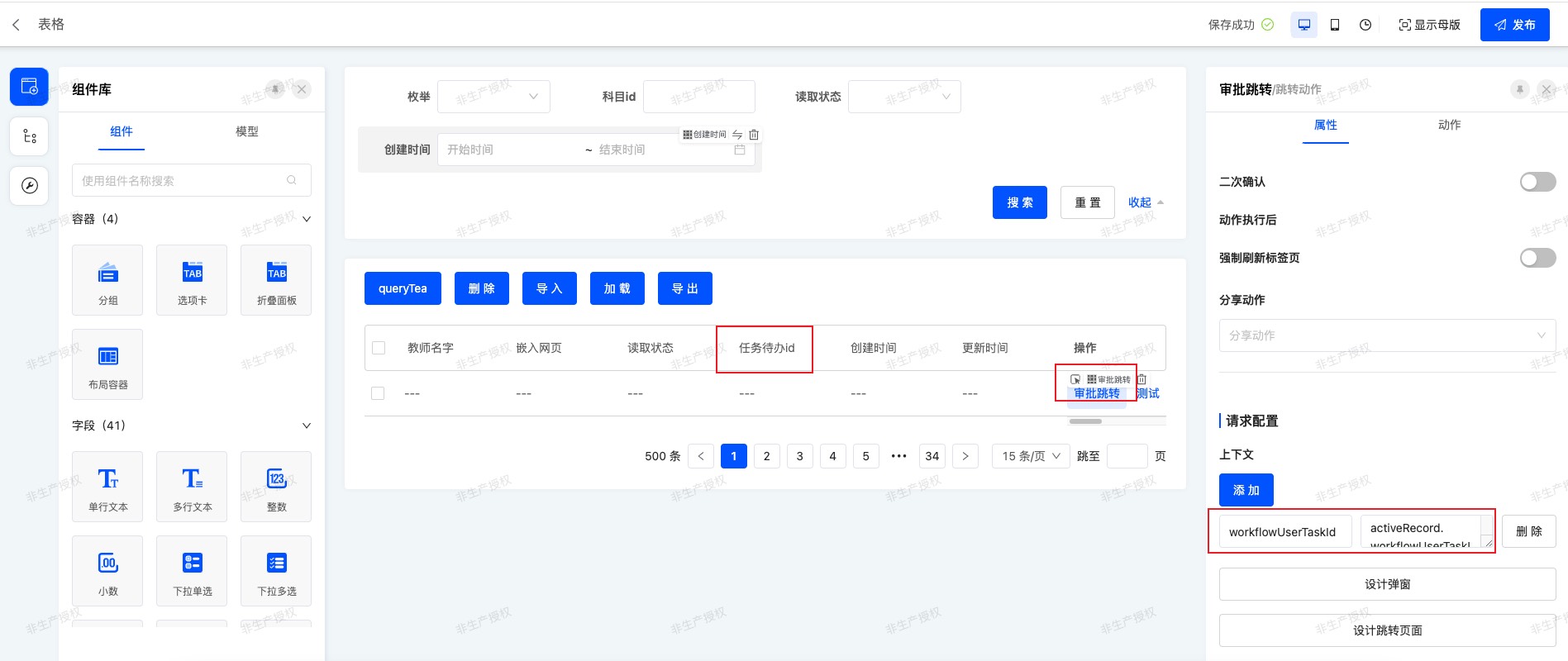
-
重写教师模型的queryPage,通过业务数据id查询出每条业务数据的工作流用户任务待办id返回给前端。
@Function.Advanced(displayName = "查询教师列表", type = FunctionTypeEnum.QUERY, category = FunctionCategoryEnum.QUERY_PAGE, managed = true) @Function(openLevel = {FunctionOpenEnum.LOCAL, FunctionOpenEnum.REMOTE, FunctionOpenEnum.API}) public Pagination<Teacher> queryPage(Pagination<Teacher> page, IWrapper<Teacher> queryWrapper) { Pagination<Teacher> teacherPagination = new Teacher().queryPage(page, queryWrapper); List<Teacher> content = teacherPagination.getContent(); if (CollectionUtils.isEmpty(content)) { return teacherPagination; } List<Long> teacherIds = content.stream().map(Teacher::getId).collect(Collectors.toList()); List<WorkflowUserTask> workflowUserTasks = Models.data().queryListByWrapper(Pops.<WorkflowUserTask>lambdaQuery() .from(WorkflowUserTask.MODEL_MODEL) .in(WorkflowUserTask::getNodeDataBizId, teacherIds) .orderByDesc(WorkflowUserTask::getCreateDate) ); if (CollectionUtils.isEmpty(workflowUserTasks)) { return teacherPagination; } Map<Long/*业务id*/, WorkflowUserTask> userTaskMap = workflowUserTasks.stream().collect(Collectors.toMap( WorkflowUserTask::getNodeDataBizId, a -> a, (old, n) -> old) ); for (Teacher teacher : content) { if (userTaskMap.containsKey(teacher.getId())) { teacher.setWorkflowUserTaskId(userTaskMap.get(teacher.getId()).getId()); } } return teacherPagination; } -
查看效果,任务待办id成功传到表单里面。
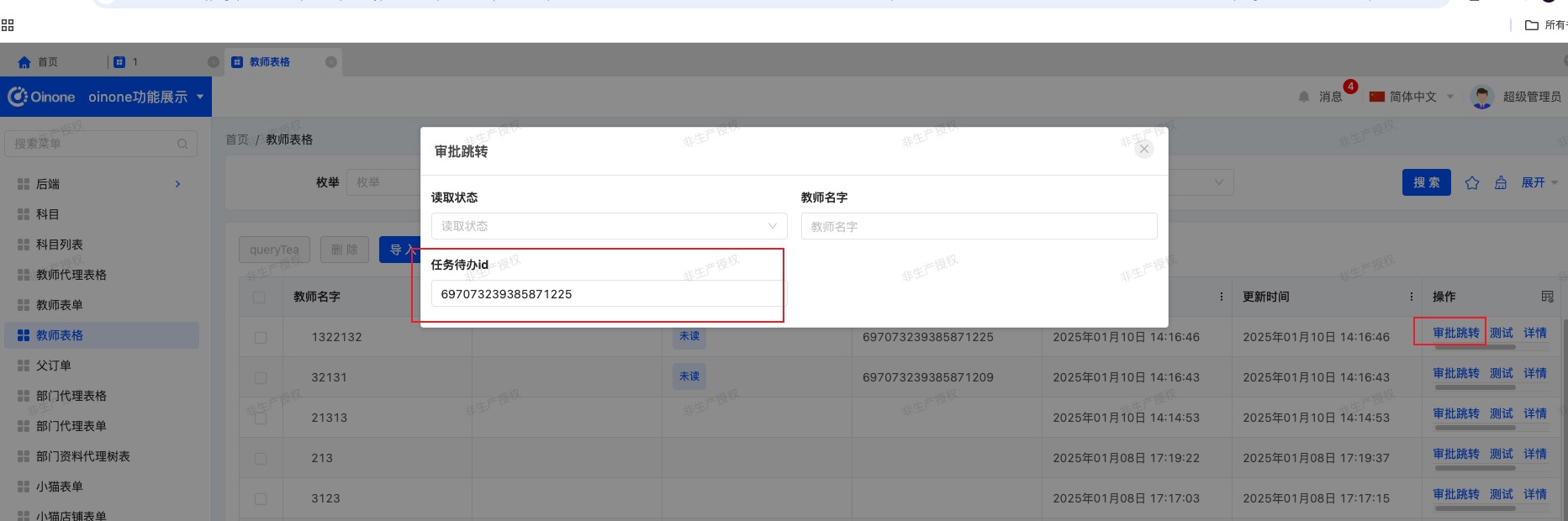
Oinone社区 作者:yexiu原创文章,如若转载,请注明出处:https://doc.oinone.top/other/20288.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验