
介绍
用户登录成功后或者访问网页不带任何路由参数的时候前端会请求全局的首页的视图动作viewAction配置,然后跳转到该视图动作viewAction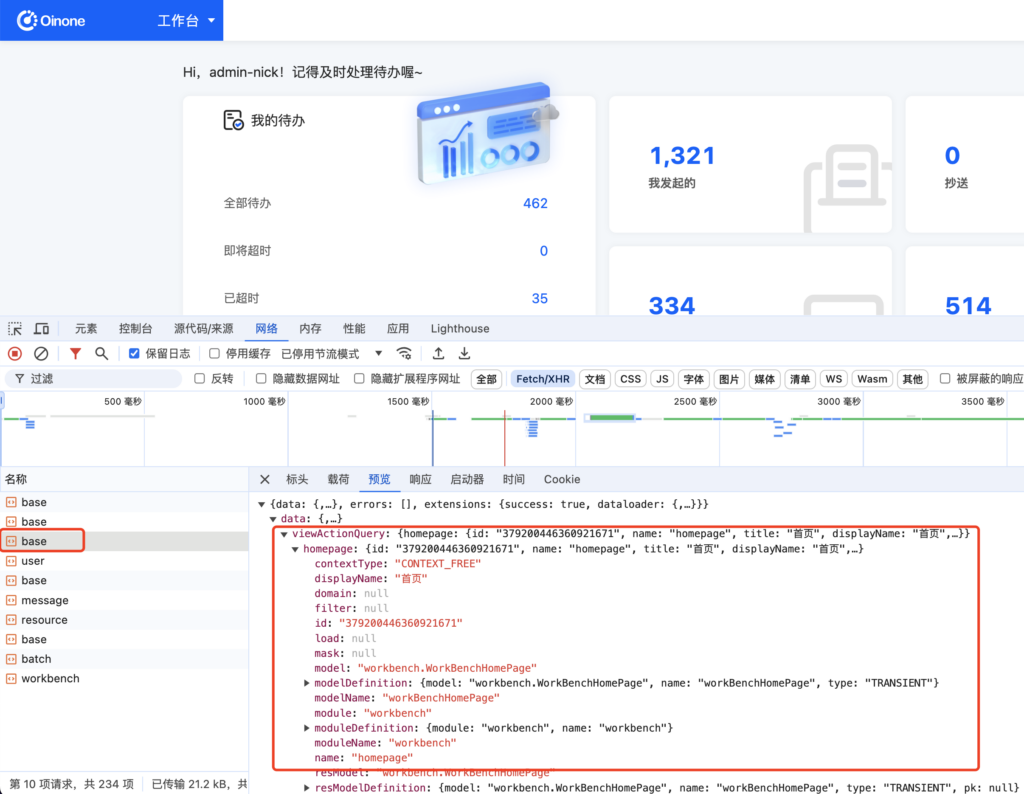

方案
我们可以通过在该方法的后置hook自定义获取首页的逻辑,下面以按角色跳转不同首页的需求示例
package pro.shushi.pamirs.demo.core.hook;
import org.apache.commons.collections4.CollectionUtils;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.auth.api.model.AuthRole;
import pro.shushi.pamirs.boot.base.enmu.BaseExpEnumerate;
import pro.shushi.pamirs.boot.base.model.ViewAction;
import pro.shushi.pamirs.boot.web.loader.PageLoadAction;
import pro.shushi.pamirs.demo.api.model.DemoItemCategory;
import pro.shushi.pamirs.demo.api.model.DemoItemLabel;
import pro.shushi.pamirs.meta.annotation.Hook;
import pro.shushi.pamirs.meta.api.CommonApiFactory;
import pro.shushi.pamirs.meta.api.core.faas.HookAfter;
import pro.shushi.pamirs.meta.api.dto.fun.Function;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.meta.common.exception.PamirsException;
import pro.shushi.pamirs.user.api.model.PamirsUser;
import java.util.List;
import java.util.stream.Collectors;
@Component
public class DemoHomepageHook implements HookAfter {
private static final String TEST_ROLE_CODE_01 = "ROLE_1211";
private static final String TEST_ROLE_CODE_02 = "ROLE_1211_1";
@Override
@Hook(module = {"base"}, model = {ViewAction.MODEL_MODEL}, fun = {"homepage"})
public Object run(Function function, Object ret) {
if (ret == null) {
return null;
}
ViewAction viewAction = getViewActionByCurrentRole();
if (viewAction != null) {
ViewAction retNew = CommonApiFactory.getApi(PageLoadAction.class).load(viewAction);
ViewAction viewActionRet = (ViewAction) ((Object[]) ret)[0];
viewActionRet.set_d(retNew.get_d());
}
return ret;
}
protected ViewAction getViewActionByCurrentRole() {
try {
PamirsUser user = new PamirsUser();
user.setId(PamirsSession.getUserId());
user.fieldQuery(PamirsUser::getRoles);
List<AuthRole> roles = user.getRoles();
if (CollectionUtils.isNotEmpty(roles)) {
List<String> roleCodes = roles.stream().map(AuthRole::getCode).collect(Collectors.toList());
if (roleCodes.contains(TEST_ROLE_CODE_01)) {
return new ViewAction().setModel(DemoItemCategory.MODEL_MODEL).setName("DemoMenus_ItemPMenu_DemoItemAndCateMenu_DemoItemCategoryMenu").queryOne();
} else if (roleCodes.contains(TEST_ROLE_CODE_02)) {
return new ViewAction().setModel(DemoItemLabel.MODEL_MODEL).setName("DemoMenus_ItemPMenu_DemoItemAndCateMenu_DemoItemLabelMenu").queryOne();
}
}
} catch (PamirsException exception) {
if (PamirsSession.getUserId() == null) {
throw PamirsException.construct(BaseExpEnumerate.BASE_USER_NOT_LOGIN_ERROR, exception.getCause()).errThrow();
} else {
throw exception;
}
}
return null;
}
}Oinone社区 作者:nation原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/14500.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验