
1、【导入】在有些场景,需要获取Excel导入的整体数据,进行批量的操作或者校验
可以通过实现导入扩展点的方式实现,入参data是导入Excel的数据列表;业务可以根据实际情况进行数据校验
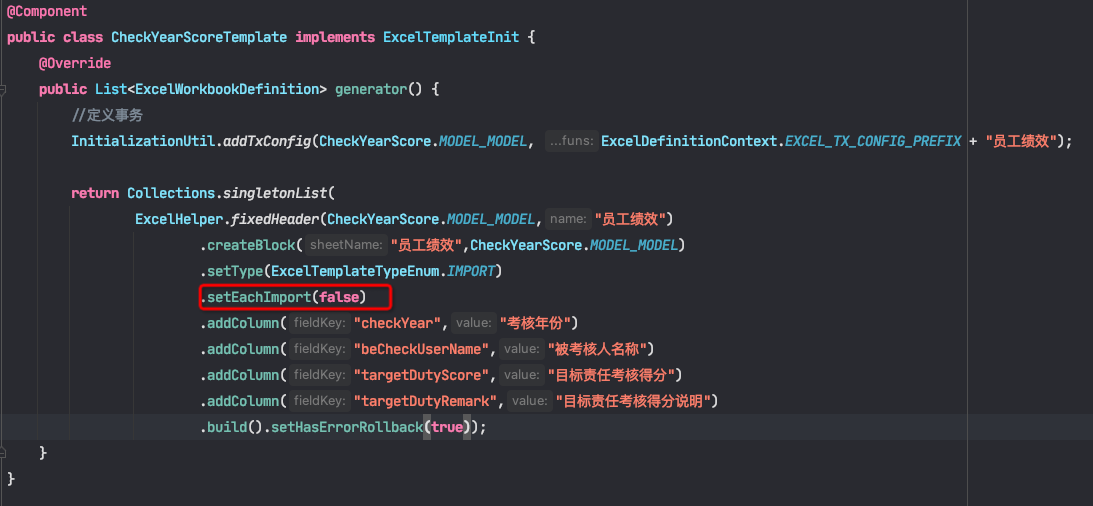
1)Excel模板定义,需要设置setEachImport(false)

2)导入扩展点API定义
pro.shushi.pamirs.file.api.extpoint.ExcelImportDataExtPoint#importData3)示例代码参考:
pro.shushi.pamirs.translate.extpoint.ResourceTranslationImportExtPoint#importData
@Slf4j
@Component
@Ext(ExcelImportTask.class)
public class ResourceTranslationImportExtPoint extends AbstractExcelImportDataExtPointImpl<List<ResourceTranslationItem>> {
@Override
//TODO 表达式,可以自定义,比如可以支持1个模型的多个【导入名称】的不同模板
@ExtPoint.Implement(expression = "importContext.definitionContext.model==\"" + ResourceTranslation.MODEL_MODEL + "\"")
public Boolean importData(ExcelImportContext importContext, List<ResourceTranslationItem> dataList) {
//TODO dataList就是excel导入那个sheet的所有内容
return true;
}
}2、【导入】逐行导入的时候做事务控制
在模板中定义中增加事务的定义,并设置异常后回滚。参加示例代码:
excel模板定义
@Component
public class DemoItemImportTemplate implements ExcelTemplateInit {
public static final String TEMPLATE_NAME = "商品导入模板";
@Override
public List<ExcelWorkbookDefinition> generator() {
//定义事务(导入处理中,只操作单个表的不需要事务定义。)
//是否定义事务根据实际业务逻辑确定。比如:有些场景在导入前需要删除数据后在进行导入就需要定义事务
InitializationUtil.addTxConfig(DemoItem.MODEL_MODEL, ExcelDefinitionContext.EXCEL_TX_CONFIG_PREFIX + TEMPLATE_NAME);
return Collections.singletonList(
ExcelHelper.fixedHeader(DemoItem.MODEL_MODEL, TEMPLATE_NAME)
.setType(ExcelTemplateTypeEnum.IMPORT)
.createSheet("商品导入-sheet1")
.createBlock(DemoItem.MODEL_MODEL)
.addUnique(DemoItem.MODEL_MODEL,"name")
.addColumn("name","名称")
.addColumn("description","描述")
.addColumn("itemPrice","单价")
.addColumn("inventoryQuantity","库存")
.build().setEachImport(true)
//TODO 设置异常后回滚的标识,这个地方会回滚事务
.setHasErrorRollback(true)
.setExcelImportMode(ExcelImportModeEnum.SINGLE_MODEL)
);
}
}导入逻辑处理
@Slf4j
@Component
@Ext(ExcelImportTask.class)
public class DemoItemImportExtPoint extends AbstractExcelImportDataExtPointImpl<DemoItem> implements ExcelImportDataExtPoint<DemoItem> {
@Autowired
private DemoItemService demoItemService;
@Override
@ExtPoint.Implement(expression = "importContext.definitionContext.model == \"" + DemoItem.MODEL_MODEL + "\"")
public Boolean importData(ExcelImportContext importContext, DemoItem data) {
ExcelImportTask importTask = importContext.getImportTask();
try {
DemoItemImportTask hrExcelImportTask = new DemoItemImportTask().queryById(importTask.getId());
String publishUserName = Optional.ofNullable(hrExcelImportTask).map(DemoItemImportTask::getPublishUserName).orElse(null);
data.setPublishUserName(publishUserName);
demoItemService.create(data);
} catch(PamirsException e) {
log.error("导入异常", e);
} catch (Exception e) {
log.error("导入异常", e);
}
return Boolean.TRUE;
}
}Oinone社区 作者:望闲原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/4856.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验