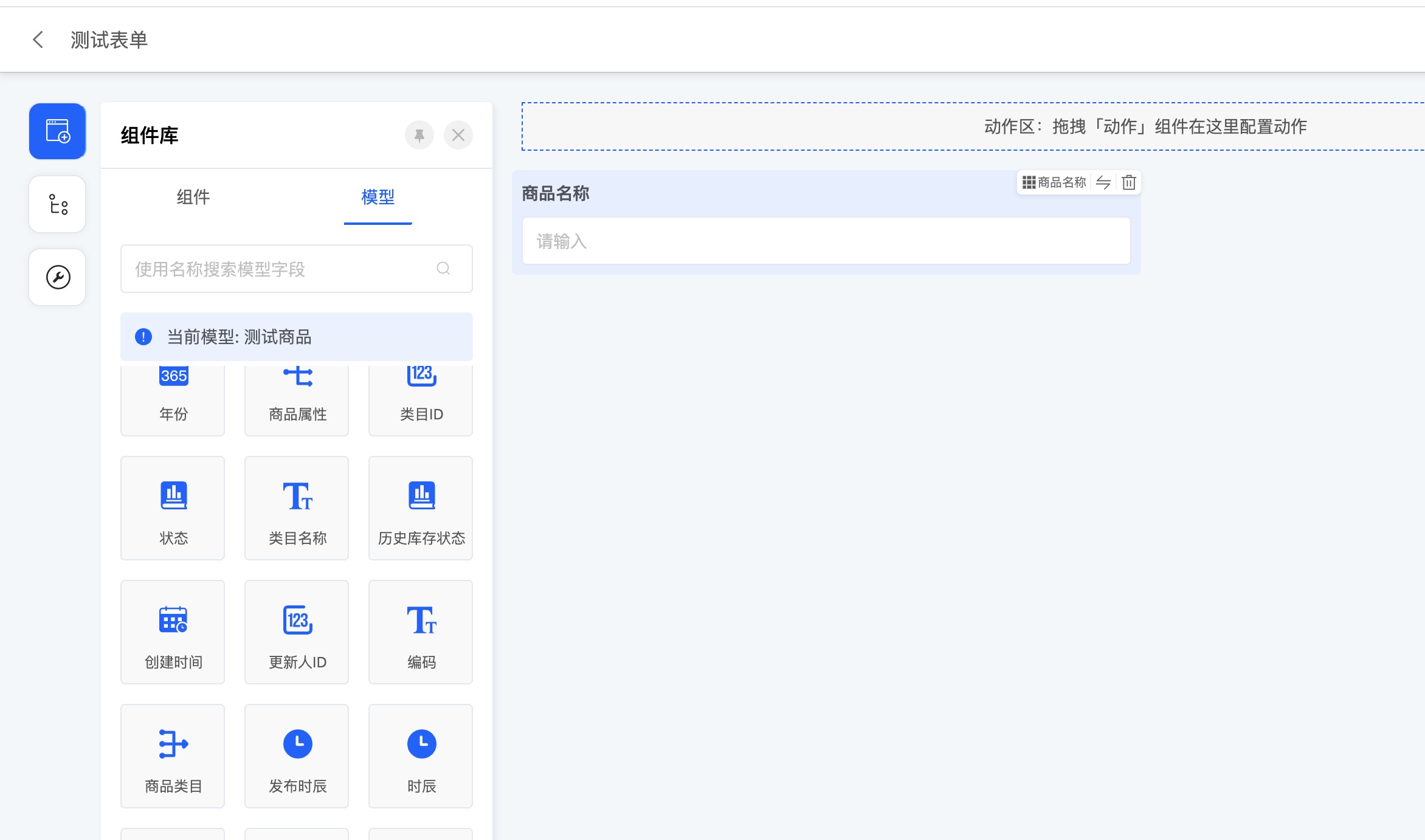
1. 审批/填写节点的视图页面
在界面设计器中创建对应模型的表单视图,可根据业务场景需要自定义所需流程待办的审批页面
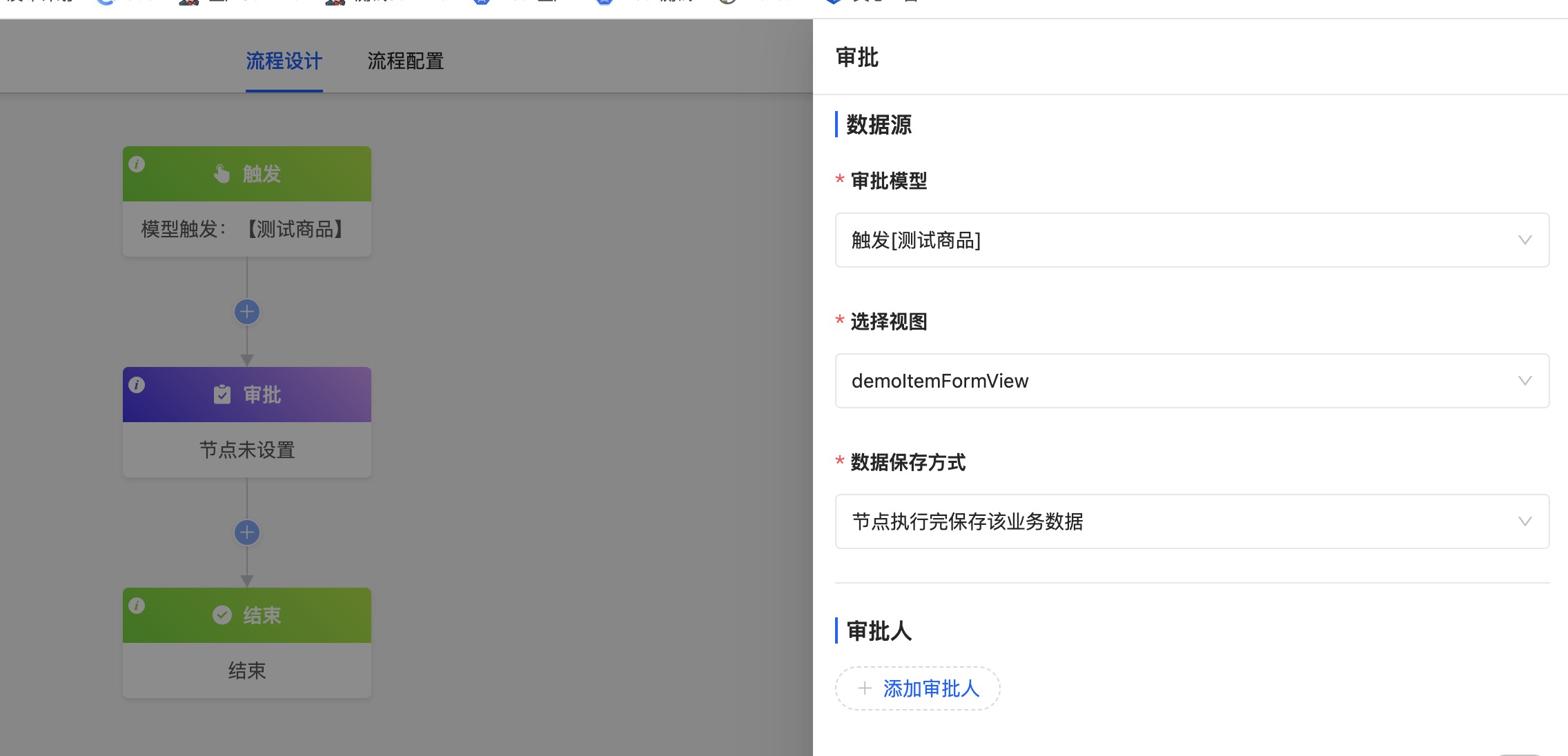
2. 在审批/填写节点中选择刚创建的视图
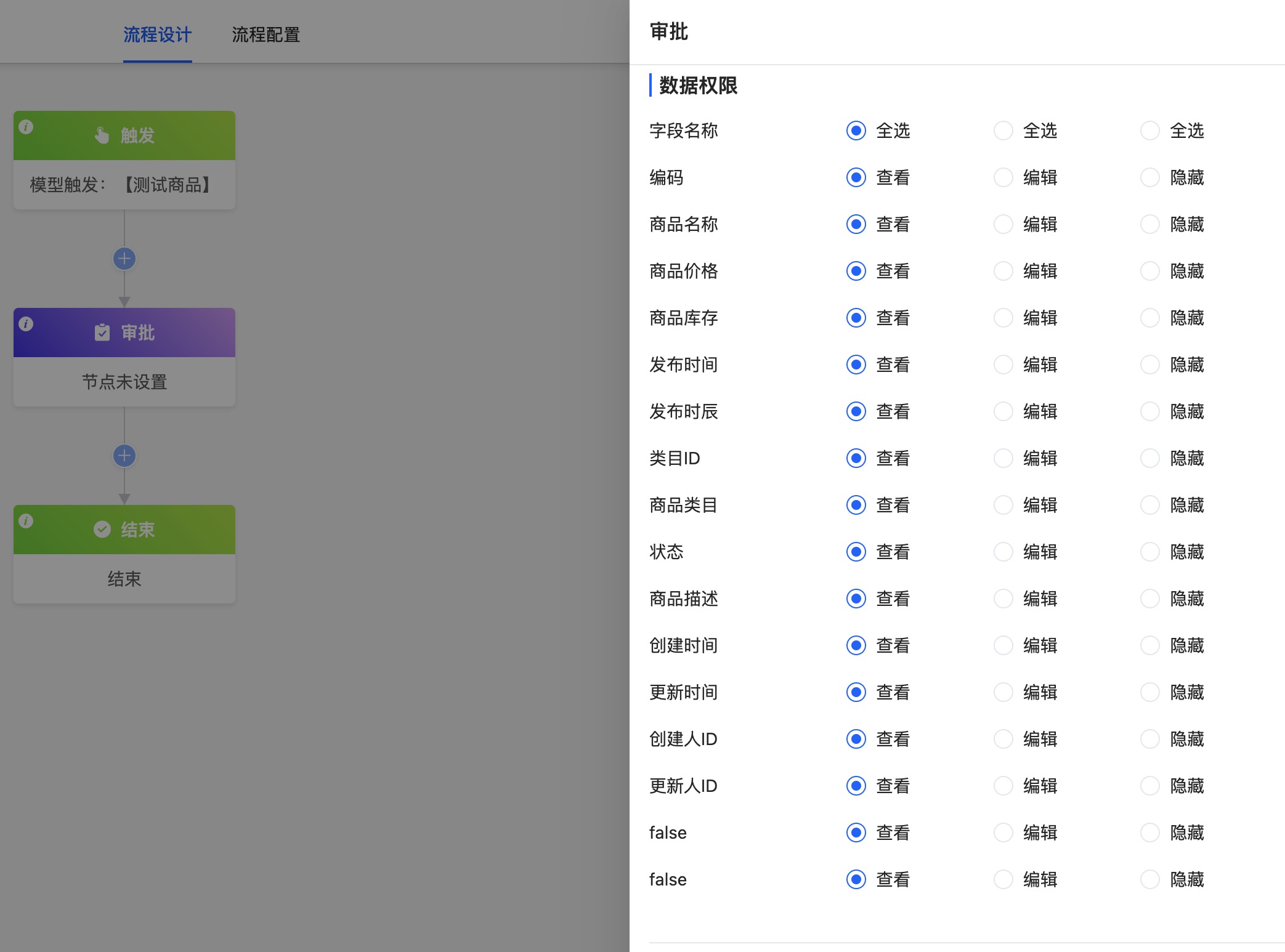
在工作流待办数据权限可在节点数据权限中可对字段设置查看、编辑、隐藏

Oinone社区 作者:数式-海波原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/7224.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验

在界面设计器中创建对应模型的表单视图,可根据业务场景需要自定义所需流程待办的审批页面
2. 在审批/填写节点中选择刚创建的视图
在工作流待办数据权限可在节点数据权限中可对字段设置查看、编辑、隐藏
Oinone社区 作者:数式-海波原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/7224.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验
验签工具类 PS:该验签方法仅在pamirs-core的5.0.16版本以上可正常使用 public class EipSignUtils { public static final String SIGN_METHOD_MD5 = "md5"; private static final String SIGN_METHOD_HMAC = "hmac"; private static final String SECRET_KEY_ALGORITHM = "HmacMD5"; private static final String MESSAGE_DIGEST_MD5 = "MD5"; public static String signTopRequest(Map<String, String> params, String secret, String signMethod) throws IOException { // 第一步:检查参数是否已经排序 String[] keys = params.keySet().toArray(new String[0]); Arrays.sort(keys); // 第二步:把所有参数名和参数值串在一起 StringBuilder query = new StringBuilder(); if (SIGN_METHOD_MD5.equals(signMethod)) { query.append(secret); } for (String key : keys) { String value = params.get(key); if (StringUtils.isNoneBlank(key, value)) { query.append(key).append(value); } } // 第三步:使用MD5/HMAC加密 byte[] bytes; if (SIGN_METHOD_HMAC.equals(signMethod)) { bytes = encryptHMAC(query.toString(), secret); } else { query.append(secret); bytes = encryptMD5(query.toString()); } // 第四步:把二进制转化为大写的十六进制(正确签名应该为32大写字符串,此方法需要时使用) return byte2hex(bytes); } private static byte[] encryptHMAC(String data, String secret) throws IOException { byte[] bytes; try { SecretKey secretKey = new SecretKeySpec(secret.getBytes(StandardCharsets.UTF_8), SECRET_KEY_ALGORITHM); Mac mac = Mac.getInstance(secretKey.getAlgorithm()); mac.init(secretKey); bytes = mac.doFinal(data.getBytes(StandardCharsets.UTF_8)); } catch (GeneralSecurityException e) { throw new IOException(e.toString(), e); } return bytes; } private static byte[] encryptMD5(String data) throws IOException { return encryptMD5(data.getBytes(StandardCharsets.UTF_8)); } private static byte[] encryptMD5(byte[] data) throws IOException { try { MessageDigest md = MessageDigest.getInstance(MESSAGE_DIGEST_MD5); return md.digest(data); } catch (NoSuchAlgorithmException e)…
代码示例 示例仅供参考 点击下载代码示例 业务场景 准备工作:两个模型,物料(Material)和物料类别(MaterialCategory)。目标:在一个Excel模板中同时导入和导出两个模型的数据。 Material模型 @Model.model(Material.MODEL_MODEL) @Model.Advanced(unique = {"code"}) @Model(displayName = "物料", labelFields = {"name"}) public class Material extends IdModel { private static final long serialVersionUID = -2594216864389636135L; public static final String MODEL_MODEL = "maas.Material"; @Field.String @Field(displayName = "物料编码", required = true) private String code; @Field.String @Field(displayName = "物料名称", required = true) private String name; } MaterialCategory模型 @Model.model(MaterialCategory.MODEL_MODEL) @Model.Advanced(unique = {"code"}) @Model(displayName = "物料类别", labelFields = {"name"}) public class MaterialCategory extends IdModel { private static final long serialVersionUID = 6300896634558908349L; public static final String MODEL_MODEL = "maas.MaterialCategory"; @Field.String @Field(displayName = "类别编码", required = true) private String code; @Field.String @Field(displayName = "类别名称", required = true) private String name; } 模板定义 MaterialTemplate @Component public class MaterialTemplate implements ExcelTemplateInit { public static final String TEMPLATE_NAME = "materialTemplate"; @Override public List<ExcelWorkbookDefinition> generator() { WorkbookDefinitionBuilder builder = WorkbookDefinitionBuilder.newInstance(Material.MODEL_MODEL, TEMPLATE_NAME) .setDisplayName("物料和物料类别") .setEachImport(Boolean.FALSE);//设置importData的入参为 (ExcelImportContext importContext, List<MaterialCategory> data),如入参是单个对象,请删除setEachImport(Boolean.FALSE) createMaterialSheet(builder); createMaterialCategorySheet(builder); return Collections.singletonList(builder.build()); } private static void createMaterialSheet(WorkbookDefinitionBuilder builder) { builder.createSheet().setName("物料") .createBlock(Material.MODEL_MODEL, ExcelAnalysisTypeEnum.FIXED_HEADER, ExcelDirectionEnum.HORIZONTAL, "A1:B2") .createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle()).setIsConfig(Boolean.TRUE) .createCell().setField("code").setAutoSizeColumn(Boolean.TRUE).and() .createCell().setField("name").setAutoSizeColumn(Boolean.TRUE).and() .and() .createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle(v -> v.setBold(Boolean.TRUE)).setHorizontalAlignment(ExcelHorizontalAlignmentEnum.CENTER)) .createCell().setValue("物料编码").and() .createCell().setValue("物料名称"); } private static void createMaterialCategorySheet(WorkbookDefinitionBuilder builder) { builder.createSheet().setName("物料类别") .createBlock(MaterialCategory.MODEL_MODEL, ExcelAnalysisTypeEnum.FIXED_HEADER, ExcelDirectionEnum.HORIZONTAL, "A1:B2") .createHeader().setStyleBuilder(ExcelHelper.createDefaultStyle()).setIsConfig(Boolean.TRUE) .createCell().setField("code").setAutoSizeColumn(Boolean.TRUE).and()…
1、【导入】在有些场景,需要获取Excel导入的整体数据,进行批量的操作或者校验 可以通过实现导入扩展点的方式实现,入参data是导入Excel的数据列表;业务可以根据实际情况进行数据校验 1)Excel模板定义,需要设置setEachImport(false) 2)导入扩展点API定义 pro.shushi.pamirs.file.api.extpoint.ExcelImportDataExtPoint#importData 3)示例代码参考: pro.shushi.pamirs.translate.extpoint.ResourceTranslationImportExtPoint#importData @Slf4j @Component @Ext(ExcelImportTask.class) public class ResourceTranslationImportExtPoint extends AbstractExcelImportDataExtPointImpl<List<ResourceTranslationItem>> { @Override //TODO 表达式,可以自定义,比如可以支持1个模型的多个【导入名称】的不同模板 @ExtPoint.Implement(expression = "importContext.definitionContext.model==\"" + ResourceTranslation.MODEL_MODEL + "\"") public Boolean importData(ExcelImportContext importContext, List<ResourceTranslationItem> dataList) { //TODO dataList就是excel导入那个sheet的所有内容 return true; } } 2、【导入】逐行导入的时候做事务控制 在模板中定义中增加事务的定义,并设置异常后回滚。参加示例代码: excel模板定义 @Component public class DemoItemImportTemplate implements ExcelTemplateInit { public static final String TEMPLATE_NAME = "商品导入模板"; @Override public List<ExcelWorkbookDefinition> generator() { //定义事务(导入处理中,只操作单个表的不需要事务定义。) //是否定义事务根据实际业务逻辑确定。比如:有些场景在导入前需要删除数据后在进行导入就需要定义事务 InitializationUtil.addTxConfig(DemoItem.MODEL_MODEL, ExcelDefinitionContext.EXCEL_TX_CONFIG_PREFIX + TEMPLATE_NAME); return Collections.singletonList( ExcelHelper.fixedHeader(DemoItem.MODEL_MODEL, TEMPLATE_NAME) .setType(ExcelTemplateTypeEnum.IMPORT) .createSheet("商品导入-sheet1") .createBlock(DemoItem.MODEL_MODEL) .addUnique(DemoItem.MODEL_MODEL,"name") .addColumn("name","名称") .addColumn("description","描述") .addColumn("itemPrice","单价") .addColumn("inventoryQuantity","库存") .build().setEachImport(true) //TODO 设置异常后回滚的标识,这个地方会回滚事务 .setHasErrorRollback(true) .setExcelImportMode(ExcelImportModeEnum.SINGLE_MODEL) ); } } 导入逻辑处理 @Slf4j @Component @Ext(ExcelImportTask.class) public class DemoItemImportExtPoint extends AbstractExcelImportDataExtPointImpl<DemoItem> implements ExcelImportDataExtPoint<DemoItem> { @Autowired private DemoItemService demoItemService; @Override @ExtPoint.Implement(expression = "importContext.definitionContext.model == \"" + DemoItem.MODEL_MODEL + "\"") public Boolean importData(ExcelImportContext importContext, DemoItem data) { ExcelImportTask importTask = importContext.getImportTask(); try { DemoItemImportTask hrExcelImportTask = new DemoItemImportTask().queryById(importTask.getId()); String publishUserName = Optional.ofNullable(hrExcelImportTask).map(DemoItemImportTask::getPublishUserName).orElse(null); data.setPublishUserName(publishUserName); demoItemService.create(data); } catch(PamirsException e) { log.error("导入异常", e); } catch (Exception e) { log.error("导入异常", e); } return Boolean.TRUE; } }
介绍 本文需要阅读过前置文档如何自定义Excel导出功能,动态表头的功能在前置文档的基础上做的进一步扩展,本文未提到的部分都参考这个前置文档。 在日常的业务开发中,我们在导出的场景会遇到需要设置动态表头的场景,比如统计商品在最近1个月的销量,固定表头列为商品的名称等基础信息,动态表头列为最近一个月的日期,在导出的时候设置每个日期的销量,本文将通过此业务场景提供示例代码。 1.自定义导出任务模型 package pro.shushi.pamirs.demo.api.model; import pro.shushi.pamirs.file.api.model.ExcelExportTask; import pro.shushi.pamirs.meta.annotation.Model; @Model.model(DemoItemDynamicExcelExportTask.MODEL_MODEL) @Model(displayName = "商品-Excel动态表头导出任务") public class DemoItemDynamicExcelExportTask extends ExcelExportTask { public static final String MODEL_MODEL = "demo.DemoItemDynamicExcelExportTask"; } 2.自定义导出任务处理数据的扩展点 package pro.shushi.pamirs.demo.core.excel.exportdemo.extPoint; import org.springframework.stereotype.Component; import pro.shushi.pamirs.core.common.FetchUtil; import pro.shushi.pamirs.core.common.cache.MemoryIterableSearchCache; import pro.shushi.pamirs.demo.api.model.DemoItem; import pro.shushi.pamirs.file.api.config.FileConstant; import pro.shushi.pamirs.file.api.context.ExcelDefinitionContext; import pro.shushi.pamirs.file.api.enmu.ExcelTemplateTypeEnum; import pro.shushi.pamirs.file.api.entity.EasyExcelCellDefinition; import pro.shushi.pamirs.file.api.extpoint.impl.ExcelExportSameQueryPageTemplate; import pro.shushi.pamirs.file.api.model.ExcelExportTask; import pro.shushi.pamirs.file.api.model.ExcelWorkbookDefinition; import pro.shushi.pamirs.file.api.util.ExcelFixedHeadHelper; import pro.shushi.pamirs.file.api.util.ExcelHelper; import pro.shushi.pamirs.file.api.util.ExcelTemplateInit; import pro.shushi.pamirs.framework.common.entry.TreeNode; import pro.shushi.pamirs.meta.annotation.ExtPoint; import pro.shushi.pamirs.meta.api.CommonApiFactory; import pro.shushi.pamirs.meta.api.core.orm.ReadApi; import pro.shushi.pamirs.meta.api.core.orm.systems.relation.RelationReadApi; import pro.shushi.pamirs.meta.api.dto.config.ModelConfig; import pro.shushi.pamirs.meta.api.dto.config.ModelFieldConfig; import pro.shushi.pamirs.meta.api.session.PamirsSession; import pro.shushi.pamirs.meta.enmu.TtypeEnum; import pro.shushi.pamirs.meta.util.FieldUtils; import java.util.*; @Component public class DemoItemDynamicExportExtPoint extends ExcelExportSameQueryPageTemplate<DemoItem> implements ExcelTemplateInit { public static final String TEMPLATE_NAME ="商品动态导出"; @Override public List<ExcelWorkbookDefinition> generator() { ExcelFixedHeadHelper excelFixedHeadHelper = ExcelHelper.fixedHeader(DemoItem.MODEL_MODEL,TEMPLATE_NAME) .createBlock(TEMPLATE_NAME, DemoItem.MODEL_MODEL) .setType(ExcelTemplateTypeEnum.EXPORT); return Collections.singletonList(excelFixedHeadHelper.build()); } public static void buildHeader(ExcelFixedHeadHelper excelFixedHeadHelper) { excelFixedHeadHelper.addColumn("name","名称") .addColumn("cateName","类目") .addColumn("searchFrom","搜索来源") .addColumn("description","描述") .addColumn("itemPrice","单价") .addColumn("inventoryQuantity","库存"); } @Override @ExtPoint.Implement(expression = "context.model == \"" + DemoItem.MODEL_MODEL+"\" && context.name == \"" +TEMPLATE_NAME+"\"" ) public List<Object> fetchExportData(ExcelExportTask exportTask, ExcelDefinitionContext context) { List<Object> result = super.fetchExportData(exportTask,context); Object block = result.get(0); if (block instanceof ArrayList) { ((List<Object>) block).forEach(o -> { if (o instanceof DemoItem) { DemoItem item = (DemoItem) o; // TODO 设置动态表头部分字段的值 item.get_d().put("2024-09-10", "1111"); item.get_d().put("2024-09-11", "2222"); }…
注:该功能在pamirs-core 4.3.27 / 4.7.8.12以上版本可用 在模块依赖里新增DataAuditModule.MODULE_MODULE模块依赖。 @Module( name = DemoModule.MODULE_NAME, dependencies = { CommonModule.MODULE_MODULE, DataAuditModule.MODULE_MODULE }, displayName = “****”, version = “1.0.0” ) 继承OperationBody模型,设置需要在操作日志中显示的字段,并重写clone方法,设置自定义字段值。用于在计入日志处传递参数。 public class MyOperationBody extends OperationBody { public MyOperationBody(String operationModel, String operationName) { super(operationModel, operationName); } private String itemNames; public String getItemNames() { return itemNames; } public void setItemNames(String itemNames) { this.itemNames = itemNames; } @Override public OperationBody clone() { //设置自定义字段值 MyOperationBody body = OperationBody.transfer(this, new MyOperationBody(this.getOperationModel(), this.getOperationName())); body.setItemNames(this.getItemNames()); return body; } } 继承OperationLog模型,新增需要在操作日志中显示的字段。用于界面展示该自定义字段。 @Model.model(MyOperationLog.MODEL_MODEL) @Model(displayName = “自定义操作日志”, labelFields = {“itemNames”}) public class MyOperationLog extends OperationLog { public static final String MODEL_MODEL = “operation.MyOperationLog”; @Field(displayName = “新增日志字段”) @Field.String private String itemNames; } 定义一个常量 public interface OperationLogConstants { String MY_SCOPE = “MY_SCOPE”; } 在计入日志处,构造出MyOperationBody对象,向该对象中设置自定义日志字段。构造OperationLogBuilder对象并设置scope的值,用于跳转自定义服务实现。 MyOperationBody body = new MyOperationBody(CustomerCompanyUserProxy.MODEL_MODEL, CustomerCompanyUserProxyDataAudit.UPDATE); body.setItemNames(“新增日志字段”); OperationLogBuilder builder = OperationLogBuilder.newInstance(body); //设置一个scope,用于跳转自定义服务实现.OperationLogConstants.MY_SCOPE是常量,请自行定义 builder.setScope(OperationLogConstants.MY_SCOPE); //记录日志 builder.record(data.queryByPk(), data); 实现OperationLogService接口,加上@SPI.Service()注解,并设置常量,一般为类名。定义scope(注意:保持和计入日志处传入的scope值一致),用于计入日志处找到该自定义服务实现。根据逻辑重写父类中方法,便可以扩展操作日志,实现自定义记录了。 @Slf4j @Service @SPI.Service(“myOperationLogServiceImpl”) public class MyOperationLogServiceImpl< T extends D > extends OperationLogServiceImpl< T > implements OperationLogService< T >{ //定义scope,用于计入日志处找到该自定义服务实现 private static final String[] MY_SCOPE = new String[]{OperationLogConstants.MY_SCOPE}; @Override public String[] scopes() { return MY_SCOPE; } //此方法用于创建操作日志 @Override protected OperationLog createOperationLog(OperationBody body, OperationLogConfig config) { MyOperationBody body1 = (MyOperationBody)…