
1 自定义RSQL占位符常用场景
- 统一的数据权限配置
- 查询表达式的上下文变量扩展
2 自定义RSQL的模板
/**
* 演示Placeholder占位符基本定义
*
* @author Adamancy Zhang at 13:53 on 2024-03-24
*/
@Component
public class DemoPlaceHolder extends AbstractPlaceHolderParser {
private static final String PLACEHOLDER_KEY = "${thisPlaceholder}";
/**
* 占位符
*
* @return placeholder
*/
@Override
public String namespace() {
return PLACEHOLDER_KEY;
}
/**
* 占位符替换值
*
* @return the placeholder replace to the value
*/
@Override
protected String value() {
return PamirsSession.getUserId().toString();
}
/**
* 优先级
*
* @return execution order of placeholders, ascending order.
*/
@Override
public Integer priority() {
return 0;
}
/**
* 是否激活
*
* @return the placeholder is activated
*/
@Override
public Boolean active() {
return true;
}
}注意事项
-
在一些旧版本中,
priority和active可能不起作用,为保证升级时不受影响,请保证该属性配置正确。 -
PLACEHOLDER_KEY变量表示自定义占位符使用的关键字,需按照所需业务场景的具体功能并根据上下文语义正确定义。 -
为保证占位符可以被正确替换并执行,所有占位符都不应该出现重复,尤其是不能与系统内置的重复。
3 占位符使用时的优先级问题
多个占位符在进行替换时,会根据优先级按升序顺序执行,如需要指定替换顺序,可使用Spring的Order注解对其进行排序。
import org.springframework.core.annotation.Order;
@Order(0)4 Oinone平台内置的占位符
| 占位符 | 数据类型 | 含义 | 备注 |
|---|---|---|---|
| ${currentUser} | String | 当前用户ID | 未登录时无法使用 |
| ${currentRoles} | Set<String> | 当前用户的角色ID集合 | 未登录时无法使用 |
5 如何覆盖平台内置的占位符?
通过指定占位符的优先级,并定义相同的namespace可优先替换。
6 如何定义会话级别的上下文变量?
在上述模板中,我们使用的是Oinone平台内置的上下文变量进行演示,通常情况下,我们需要根据实际业务场景增加上下文变量,以此来实现所需功能。
下面,我们将根据当前用户获取当前员工ID定义该上下文变量进行演示。
/**
* 员工Session
*
* @author Adamancy Zhang at 14:33 on 2024-03-24
*/
@Component
public class EmployeeSession implements HookBefore {
private static final String SESSION_KEY = "CUSTOM_EMPLOYEE_ID";
@Autowired
private DemoEmployeeService demoEmployeeService;
public static String getEmployeeId() {
return PamirsSession.getTransmittableExtend().get(SESSION_KEY);
}
@Override
@Hook(priority = 1)
public Object run(Function function, Object... args) {
Long userId = PamirsSession.getUserId();
if (userId == null) {
return function;
}
if (StringUtils.isBlank(EmployeeSession.getEmployeeId())) {
PamirsSession.getTransmittableExtend().put(SESSION_KEY, getCurrentEmployeeId());
}
return function;
}
private String getCurrentEmployeeId() {
String employeeId = getEmployeeIdByCache();
if (employeeId == null) {
employeeId = demoEmployeeService.getCurrentEmployeeId();
}
return employeeId;
}
private String getEmployeeIdByCache() {
// do something.
return null;
}
}注意事项
-
使用
HookBefore在请求发起时向上下文中设置employeeId,使用EmployeeSession.getEmployeeId()获取即可。 -
将
HookBefore的优先级设置为priority = 1,需要该Hook在平台内置的UserHook之后执行,以确保PamirsSession.getUserId()中的值已经被正确设置。 -
DemoEmployeeService服务应使用平台@Fun及@Function注解进行实现,以确保该Session可在分布式环境中正确运行。 -
getEmployeeIdByCache方法需自行实现,在运行时使用缓存可有效提高性能。
7 将员工Session在placeholder中使用
将DemoPlaceHolder改写,使用${currentEmployeeId}获取员工Session中保存的employeeId。
/**
* 演示Placeholder占位符使用员工Session
*
* @author Adamancy Zhang at 15:02 on 2024-03-24
*/
@Component
public class DemoPlaceHolder extends AbstractPlaceHolderParser {
private static final String PLACEHOLDER_KEY = "${currentEmployeeId}";
/**
* 占位符
*
* @return placeholder
*/
@Override
public String namespace() {
return PLACEHOLDER_KEY;
}
/**
* 占位符替换值
*
* @return the placeholder replace to the value
*/
@Override
protected String value() {
return EmployeeSession.getEmployeeId();
}
/**
* 优先级
*
* @return execution order of placeholders, ascending order.
*/
@Override
public Integer priority() {
return 0;
}
/**
* 是否激活
*
* @return the placeholder is activated
*/
@Override
public Boolean active() {
return true;
}
}至此,我们已完成了一个员工ID占位符。
8 在权限配置时使用该占位符作为过滤条件
下面,我们将模拟一个简单业务场景,详细介绍该占位符如何在业务中使用。
8.1 场景描述
当前系统中包含部门和员工两个模型,模型的基本定义如下所示:
部门
/**
* 演示部门
*
* @author Adamancy Zhang at 15:18 on 2024-03-24
*/
@Model.model(DemoDepartment.MODEL_MODEL)
@Model(displayName = "演示部门", labelFields = "name")
public class DemoDepartment extends IdModel {
private static final long serialVersionUID = -300189841334506668L;
public static final String MODEL_MODEL = "demo.DemoDepartment";
@Field(displayName = "部门名称")
private String name;
@Field(displayName = "管理员")
private DemoEmployee manager;
}员工
/**
* 演示员工
*
* @author Adamancy Zhang at 15:17 on 2024-03-24
*/
@Model.model(DemoEmployee.MODEL_MODEL)
@Model.Advanced(unique = {"bindingUserId"})
@Model(displayName = "演示员工", labelFields = "name")
public class DemoEmployee extends IdModel {
private static final long serialVersionUID = -6237083162460091500L;
public static final String MODEL_MODEL = "demo.DemoEmployee";
@Field(displayName = "员工名称")
private String name;
@Field.Relation(relationFields = {"bindingUserId"}, referenceFields = {"id"})
@Field(displayName = "绑定用户")
private PamirsUser bindingUser;
@Field(displayName = "绑定用户ID")
private Long bindingUserId;
}我们要求当前登录用户仅能查看其作为管理员的所在部门,因此,我们需要使用managerId == ${currentEmployeeId}这一过滤条件,在权限中进行配置并使其生效。
此处忽略数据准备过程,仅展示关键页面的配置及最终效果。
8.2 权限项配置
从应用中切换至权限模块,并选择权限项列表,创建一个数据权限项,并按照下图内容进行配置。
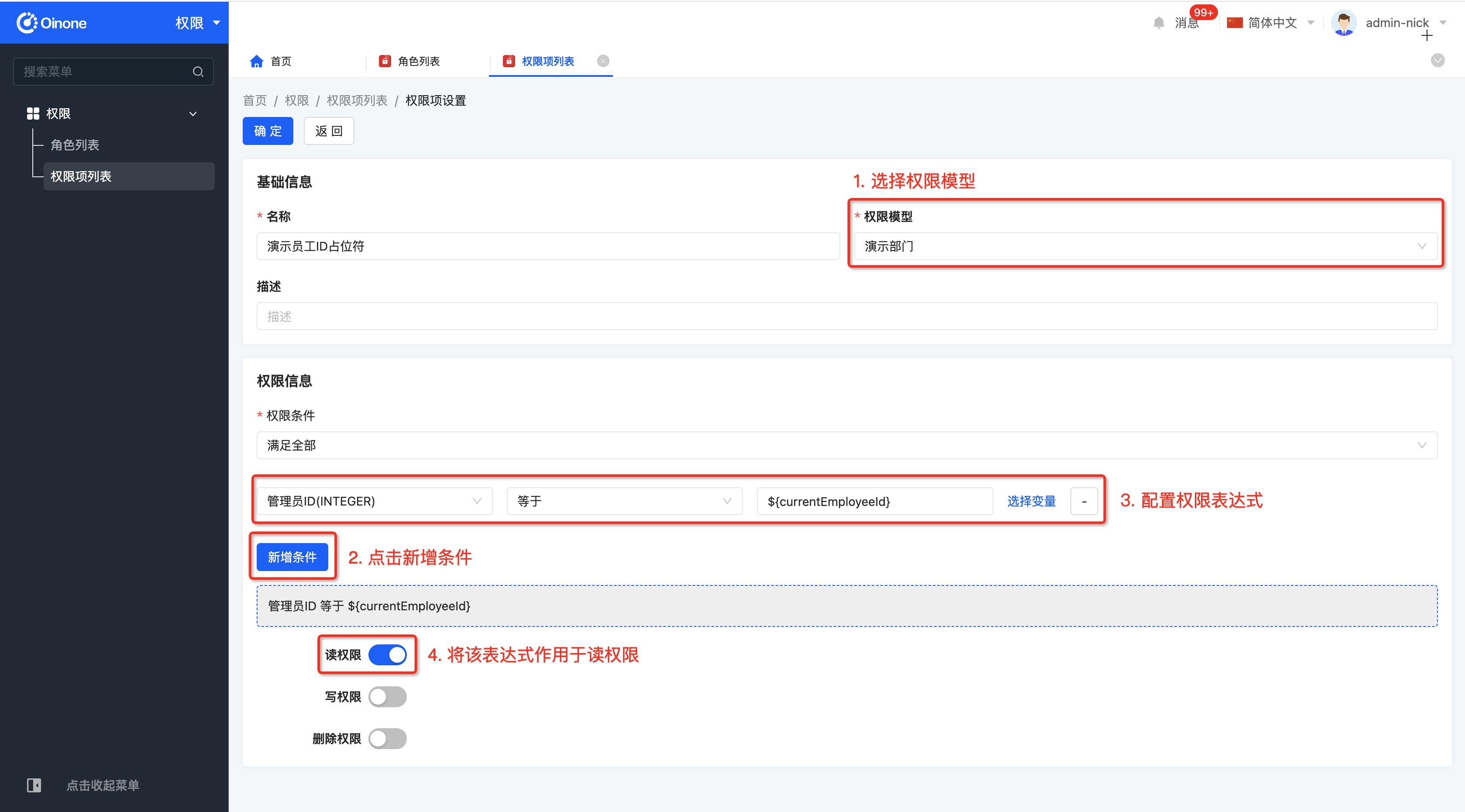

8.3 角色权限配置
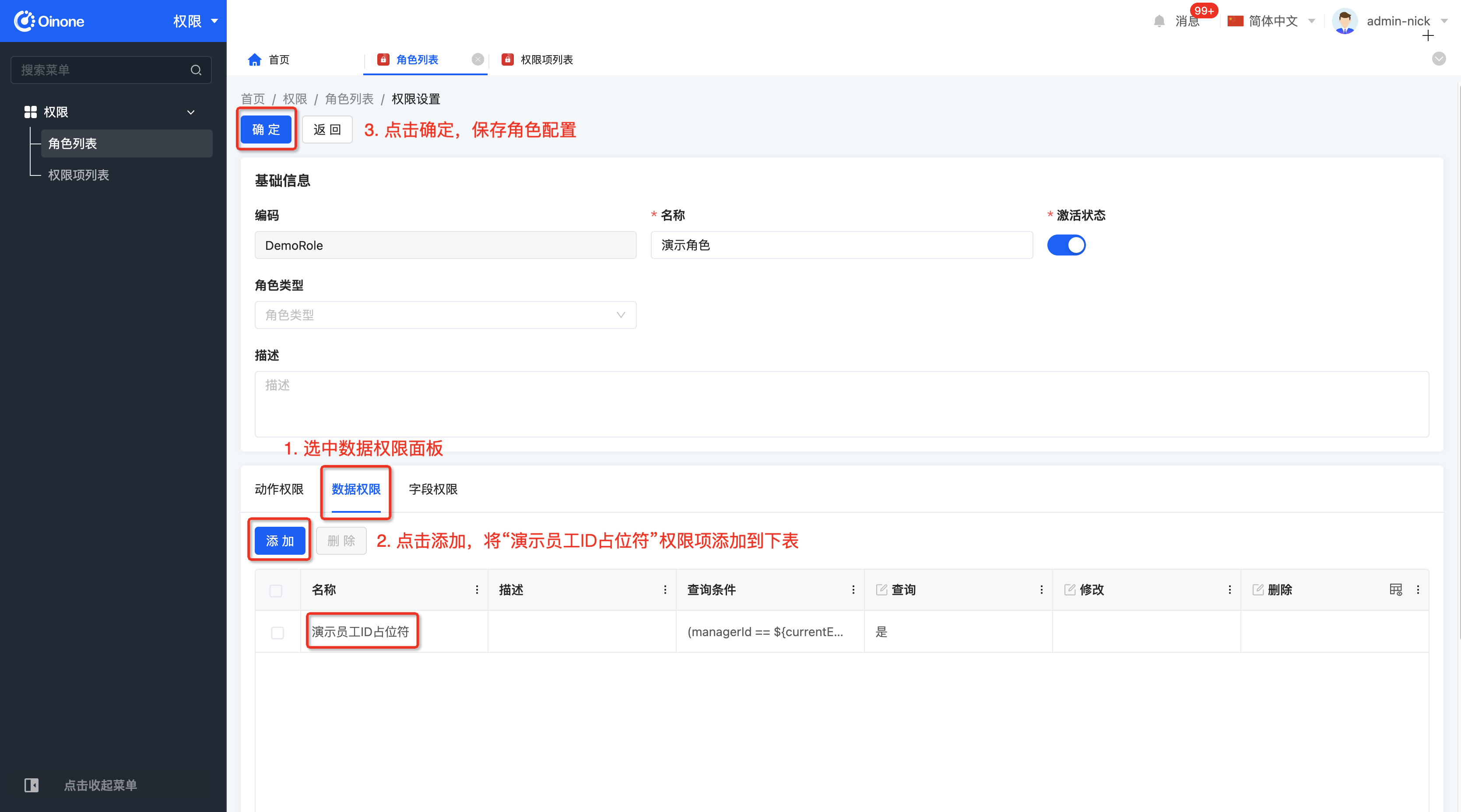
选择角色列表,并选择角色表格中指定角色的权限配置按钮,进入权限配置页面,并按照下图内容进行配置。
PS:这里省略了动作权限相关配置,配置的权限应保证该角色可以正确进入演示部门页面查看效果。
8.4 为用户绑定指定角色(如已绑定可忽略该步骤)
从应用中切换至用户中心模块,选择指定用户,绑定指定角色。
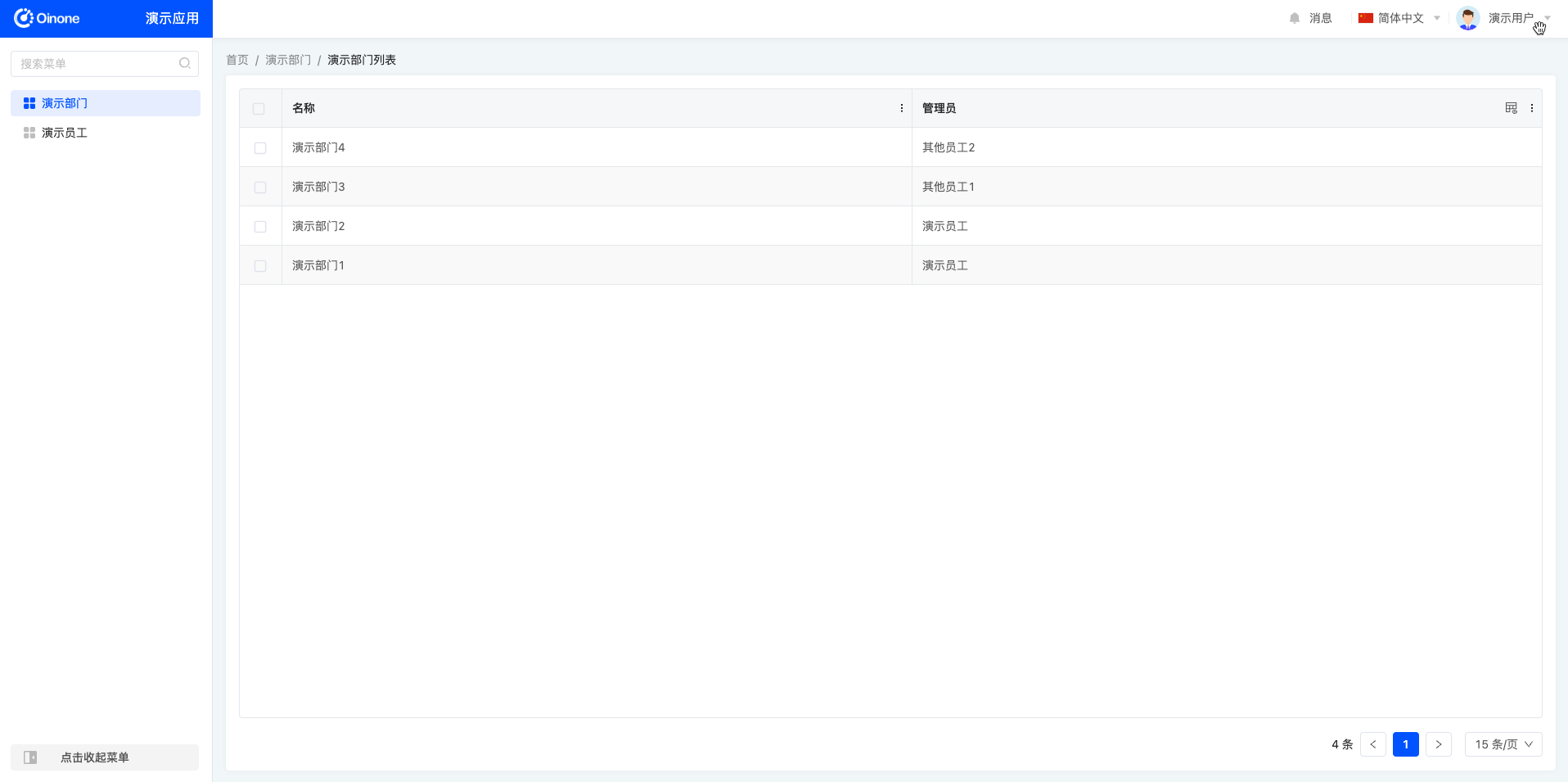
8.5 在演示部门页面查看权限配置效果
未配置权限页面效果
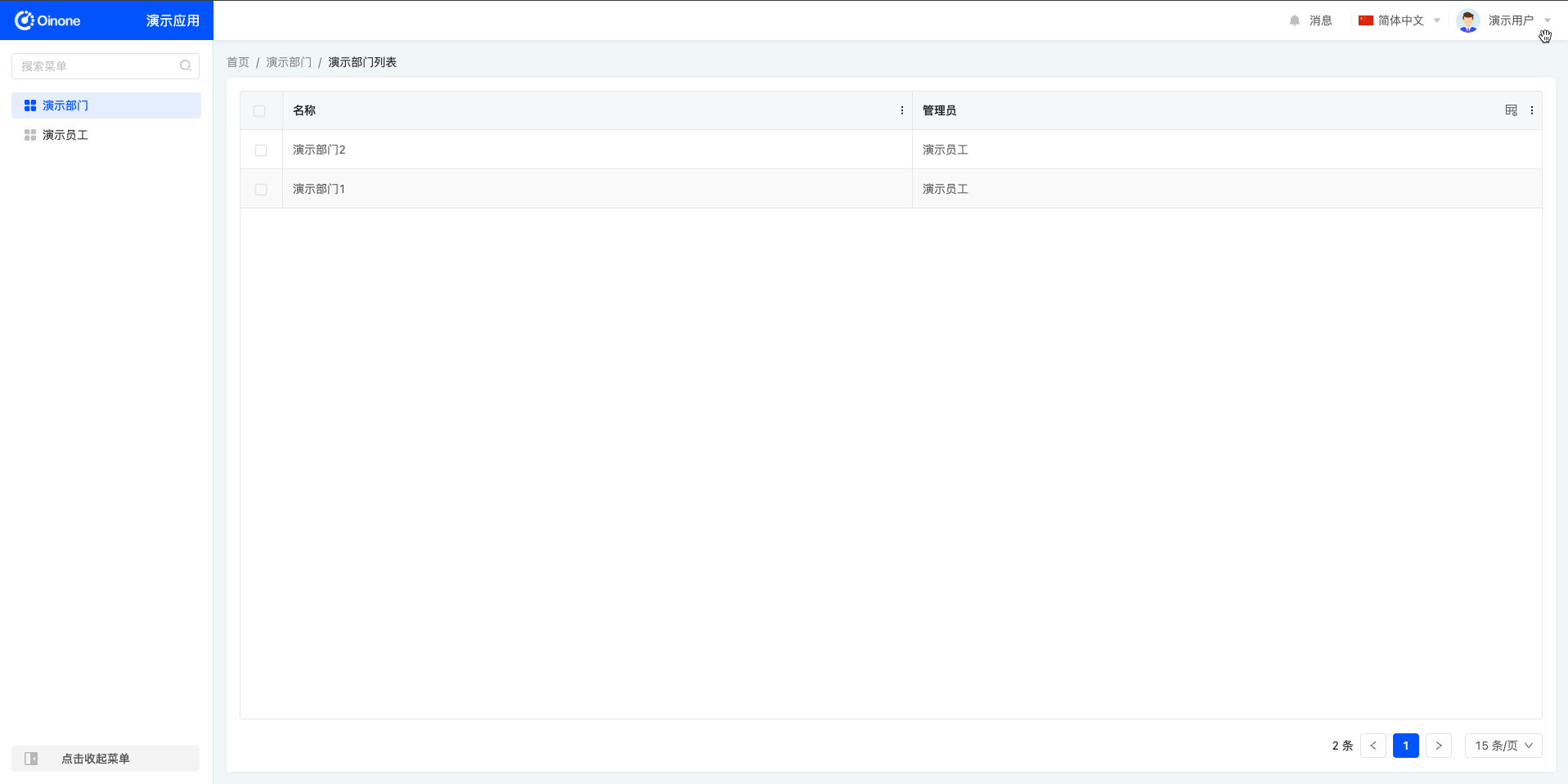
权限配置后页面效果
本文来自投稿,不代表Oinone社区立场,如若转载,请注明出处:https://doc.oinone.top/backend/6393.html