
概述
Oinone平台为开发人员提供了本地环境 - 测试环境之间的协同开发模式,可以使得开发人员在本地环境中设计的模型、函数等元数据实时被测试环境使用并设计。开发人员开发完成对应页面和功能后,可以部署至测试环境直接进行测试。
本篇文章将详细介绍协同开发模式在实际开发中的应用及相关内容。
名词解释
本地环境: 开发人员的本地启动环境测试环境: 在测试服务器上部署的业务测试环境,业务工程服务和设计器服务共用中间件业务工程服务:在测试服务器上部署的业务工程设计器服务: 在测试服务器上部署的设计器镜像一套环境:以测试环境为例,业务工程服务和设计器服务共同组成一套环境生产环境: 在生产服务器上部署的业务生产环境
环境准备
- 部署了一个可用的
设计器服务,并能正常访问。(需参照下文启动设计器环境内容进行相应修改) - 准备一个用于开发的java工程。
- 准备一个用于部署测试环境的服务器。
协同参数介绍
用于测试环境的参数
-PmetaProtected=${value}
启用元数据保护,只有配置相同启动参数的服务才允许对元数据进行更新。通常该命令用于设计器服务和业务工程服务,并且两个环境需使用相同的元数据保护标记(value)进行启动。本地环境不使用该命令,以防止本地环境在协同开发时意外修改测试环境元数据,导致元数据混乱。
用法
java -jar boot.jar -PmetaProtected=pamirs用于本地环境的配置
- 使用命令配置ownSign(推荐)
java -jar boot.jar --pamirs.distribution.session.ownSign=demo- 使用yaml配置ownSign
pamirs:
distribution:
session:
allMetaRefresh: false # 启用元数据全量刷新(备用配置,如遇元数据错误或混乱,启用该配置可进行恢复,使用一次后关闭即可)
ownSign: demo # 协同开发元数据隔离标记,用于区分不同开发人员的本地环境,其他环境不允许使用启动设计器环境
docker-run启动
-e PROGRAM_ARGS=-PmetaProtected=pamirsdocker-compose启动
services:
backend:
container_name: designer-backend
image: harbor.oinone.top/oinone/designer-backend-v5.0
restart: always
environment:
# 指定spring.profiles.active
ARG_ENV: dev
# 指定-Plifecycle
ARG_LIFECYCLE: INSTALL
# jvm参数
JVM_OPTIONS: ""
# 程序参数
PROGRAM_ARGS: "-PmetaProtected=pamirs"PS: java [JVM_OPTIONS?] -jar boot.jar [PROGRAM_ARGS?]
开发流程示例图
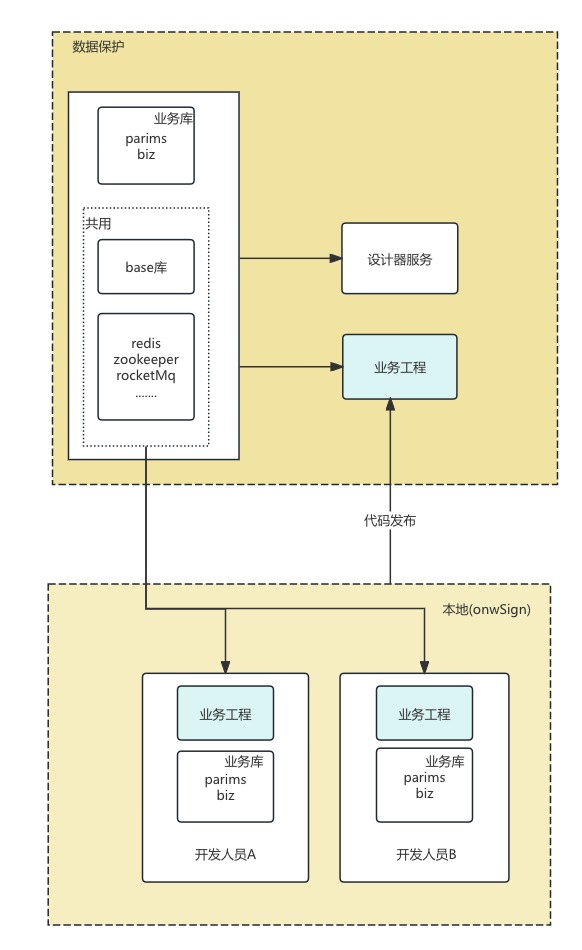

具体使用步骤详见协同开发支持
Oinone社区 作者:张博昊原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/14878.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验