
协同开发概述
在使用Oinone进行业务开发中,目前开发方式为: 开发各个本地启动项目 与 设计器环境共库共redis的方式进行。
在多个开发人员同时修改一个模型,或者没有及时更新其他同学提交的代码时,存在业务模型创建的数据表字段被删除的情况,协同开发模式正式为解决这个问题而生。
版本支持
4.7.x版本 已经包含分布式支持。
使用步骤
1、业务后端boot工程引入协同开发包
<dependency>
<groupId>pro.shushi.pamirs.distribution</groupId>
<artifactId>pamirs-distribution-session-cd</artifactId>
</dependency>2、yml文件配置ownSign
pamirs:
distribution:
session:
allMetaRefresh: false
# ownSign根据实际情况修改,一般为研发各自名称
ownSign: wangxian配置说明:
allMetaRefresh,全量刷新Redis中的元数据,绝大多数情况下都不需要配置;
1)第一次启动或者Redis的缓存被清空后,会自动进行全量。
2)配置为true表示强制进行全量,一般都不需要配置;
3)【推荐】默认增量的方式(即allMetaRefresh: false)写入redis的数据更少,相应的启动速度也更快
4)【强制】ownSign是环境隔离的设置,同一个项目组不同的开发人员之间,ownSign配置成不同的(即各自配置成各自的,达到互不干扰)
3、业务系统DB和缓存的约束
1)【强制】业务库和设计器Redis共用,包括Redis的前缀,租户和系统隔离键都需要一样(这三个值影响RedisKey的拼接)
2)【强制】base库业务系统与设计器共用;
3) 【强制】公共库即pamirs (资源-resource、用户-user、权限-auth、文件-file等)共用;
4)【强制】「业务库」数据源的别名必须一直,每个开发人员必须配置到自己的本地 或者是远程库库加一个后缀区分;
4、开发同学在各自访问设计器时,URL最后面增加;ownSign=wangxian后回车,ownSign会被保存到浏览器缓存中,后续访问其他的URL访问不需要再次输入;如果需要去掉ownSign的值,则直接把界面上的悬浮窗删掉即可。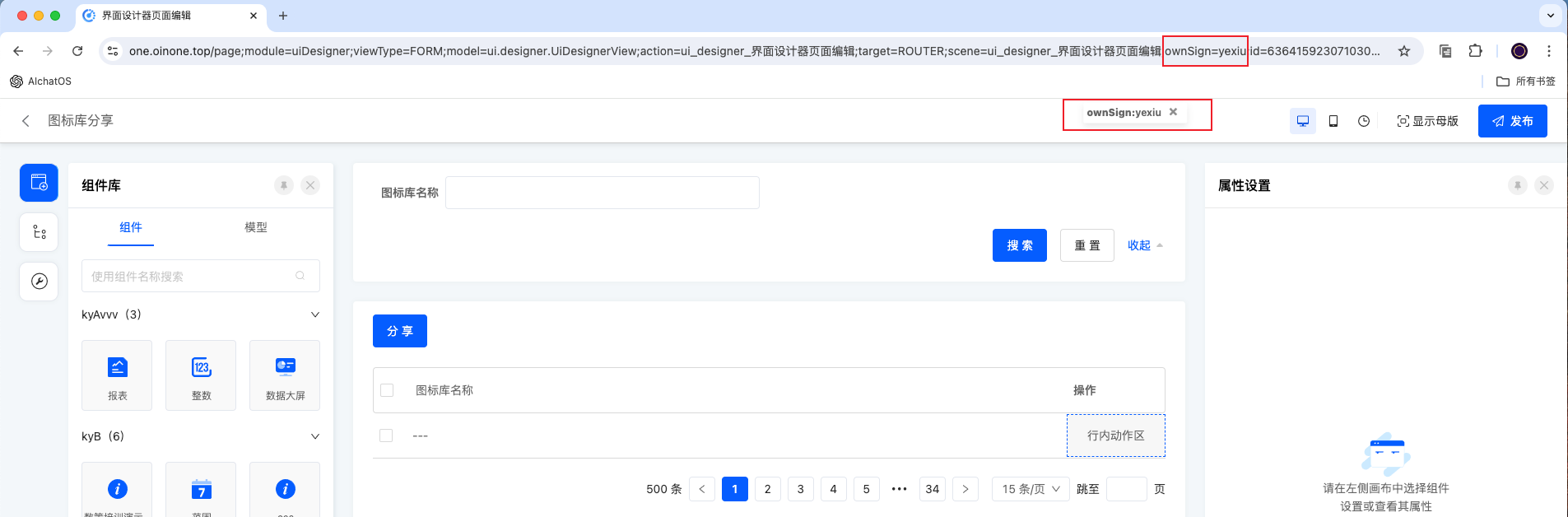

说明:访问设计URL上增加的ownSign需要与开发各自本地项目yml文件中ownSign的值相同。(每个开发人员各自用各自的ownSign)
PS:具体参数配置详见Oinone协同开发使用手册
Oinone社区 作者:望闲原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/4821.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验