
场景概述
【字段类型之关系与引用】一文中已经描述了各种关系字段的常规写法,还有一些特殊场景如:关系映射中存在常量,或者M2M中间表是大于两个字段构成。
场景描述
1、PetTalent模型增加talentType字段
2、PetItem与PetTalent的多对多关系增加talentType(达人类型),
3、PetItemRelPetTalent中间表维护petItemId、petTalentId以及talentType,PetDogItem和PetCatItem分别重写petTalents字段,关系中增加常量描述。示意图如下: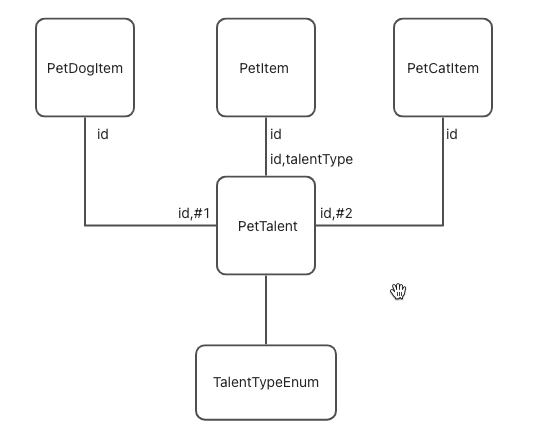

实际操作步骤
Step1 新增 TalentTypeEnum
package pro.shushi.pamirs.demo.api.enumeration;
import pro.shushi.pamirs.meta.annotation.Dict;
import pro.shushi.pamirs.meta.common.enmu.BaseEnum;
@Dict(dictionary = TalentTypeEnum.DICTIONARY,displayName = "达人类型")
public class TalentTypeEnum extends BaseEnum<TalentTypeEnum,Integer> {
public static final String DICTIONARY ="demo.TalentTypeEnum";
public final static TalentTypeEnum DOG =create("DOG",1,"狗达人","狗达人");
public final static TalentTypeEnum CAT =create("CAT",2,"猫达人","猫达人");
}Step2 PetTalent模型增加talentType字段
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.demo.api.enumeration.TalentTypeEnum;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Model;
@Model.model(PetTalent.MODEL_MODEL)
@Model(displayName = "宠物达人",summary="宠物达人",labelFields ={"name"})
public class PetTalent extends AbstractDemoIdModel{
public static final String MODEL_MODEL="demo.PetTalent";
@Field(displayName = "达人")
private String name;
@Field(displayName = "达人类型")
private TalentTypeEnum talentType;
}Step3 修改PetItem的petTalents字段,在关系描述中增加talentType(达人类型)
@Field.many2many(relationFields = {"petItemId"},referenceFields = {"petTalentId","talentType"},through = PetItemRelPetTalent.MODEL_MODEL )
@Field.Relation(relationFields = {"id"}, referenceFields = {"id","talentType"})
@Field(displayName = "推荐达人",summary = "推荐该商品的达人们")
private List<PetTalent> petTalents;Step4 PetDogItem增加petTalents字段,重写父类PetItem的关系描述
- talentType配置为常量,填入枚举的值
- 增加domain描述用户页面选择的时候自动过滤出特定类型的达人,RSQL用枚举的name
@Field(displayName = "推荐达人") @Field.many2many( through = "PetItemRelPetTalent", relationFields = {"petItemId"}, referenceFields = {"petTalentId","talentType"} ) @Field.Relation(relationFields = {"id"}, referenceFields = {"id", "#1#"}, domain = " talentType == DOG") private List<PetTalent> petTalents;
Step5 PetCatItem增加petTalents字段,重写父类PetItem的关系描述
- talentType配置为常量,填入枚举的值
- 增加domain描述用户页面选择的时候自动过滤出特定类型的达人,RSQL用枚举的name
@Field(displayName = "推荐达人") @Field.many2many( through = "PetItemRelPetTalent", relationFields = {"petItemId"}, referenceFields = {"petTalentId","talentType"} ) @Field.Relation(relationFields = {"id"}, referenceFields = {"id", "#2#"}, domain = " talentType == CAT") private List<PetTalent> petTalents;
Step6 PetCatItem增加petTalents字段,many2one关系示例
- talentType配置为常量,填入枚举的值
-
增加domain描述用户页面选择的时候自动过滤出特定类型的达人,RSQL用枚举的name
@Model.model(PetPet.MODEL_MODEL) @Model(displayName = "宠物宠物", summary = "宠物宠物") public class PetPet extends IdModel { public static final String MODEL_MODEL = "demo.PetPet"; @Field.many2one @Field(displayName = "品种") @Field.Relation(relationFields = {"typeId", "#CAT#"}, referenceFields = {"id", "kind"}, domain = "kind=='CAT'") private PetType type; @Field(displayName = "品种ID", invisible = true) private Long typeId; @Field(displayName = "原产地") private String provenance;
Oinone社区 作者:望闲原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/11463.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验