
在使用继承IDModel或CodeModel时,id和code是系统默认自动生成, 默认值规则:ID-->分布式ID; CODE-->根据定义的SequenceConfig规则自动生成。
在特定情况下需要落库前先生成ID或者Code,这些场景下可参照如下代码示例
一、使用自增ID
单个字段设置方式
// 主键字段,可以使用mysql的自增能力
@Field.Integer
@Field.PrimaryKey(keyGenerator = KeyGeneratorEnum.AUTO_INCREMENT)
@Field.Advanced(batchStrategy = FieldStrategyEnum.NEVER)
@Field(displayName = "id", summary = "Id字段,⾃增")
private Long id;
@Field.Integer
@Field(displayName = "自增版本")
@Field.Sequence(sequence = "SEQ", initial = 1)
private Long version;全局设置方式
该方式会作用到每一个存储模型的id字段,在application.yml配置文件中修改id的生成规则,查找配置项关键字key-generator,默认为DISTRIBUTION(分布式id),可修改为 AUTO_INCREMENT(自增id)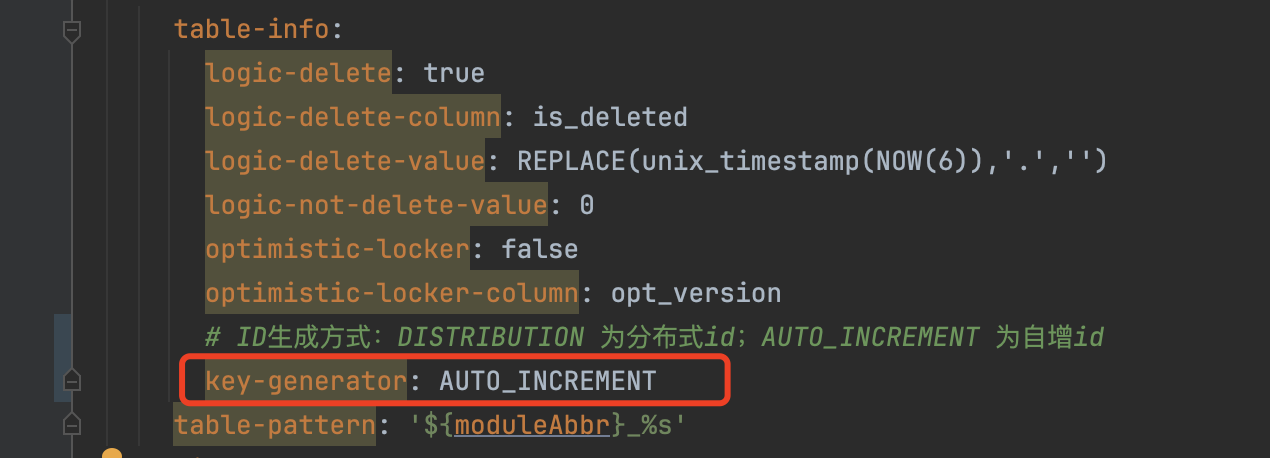

二、手动方式获取序列
获取方式示例1
/**
* 在特定场景下需要手动生成Id或者code时,可参照这个示例
*/
public void manualSetIdCode(){
DemoItem demoItem = new DemoItem();
//手动生成ID和code
Object idObj = Spider.getDefaultExtension(IdGenerator.class).generate(PamirsTableInfo.fetchKeyGenerator(DemoItem.MODEL_MODEL));
demoItem.setId(TypeUtils.createLong(idObj));
Object codeObj = CommonApiFactory.getSequenceGenerator().generate("SEQ",DemoItem.MODEL_MODEL);
String code = TypeUtils.stringValueOf(codeObj);
demoItem.setCode(code);
//……
}获取方式示例2
1、在系统启动的时候初始化SequenceConfig
package pro.shushi.pamirs.demo.core.init;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.boot.common.api.command.AppLifecycleCommand;
import pro.shushi.pamirs.boot.common.extend.MetaDataEditor;
import pro.shushi.pamirs.core.common.InitializationUtil;
import pro.shushi.pamirs.demo.api.DemoModule;
import pro.shushi.pamirs.demo.core.constant.SeqConstants;
import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j;
import pro.shushi.pamirs.meta.api.dto.meta.Meta;
import pro.shushi.pamirs.meta.enmu.SequenceEnum;
import java.util.Map;
/**
* DemoMetadataEditor
*/
@Slf4j
@Component
public class DemoMetadataEditor implements MetaDataEditor {
@Override
public void edit(AppLifecycleCommand command, Map<String, Meta> metaMap) {
InitializationUtil util = InitializationUtil.get(metaMap, DemoModule.MODULE_MODULE, DemoModule.MODULE_NAME);
if (util == null) {
log.error("获取初始化序列失败");
return;
}
bizSequence(util);
}
private void bizSequence(InitializationUtil util) {
util.createSequenceConfig("申请单编码生成", SeqConstants.NABEL_SAMPLE_APPLY_SEQ, SequenceEnum.ORDERLY_SEQ, 8)
.setStep(1)
.setInitial(80000000L)
.setIsRandomStep(false);
util.createSequenceConfig("订单编码生成", SeqConstants.NABEL_SAMPLE_ORDER_SEQ_YP, SequenceEnum.ORDERLY_SEQ, 8)
.setPrefix("YP")
.setStep(1)
.setInitial(80000000L)
.setIsRandomStep(false);
}
}
2、在代码中使用序列
public static String getSaleOrderCode() {
Object sequence = CommonApiFactory.getSequenceGenerator().generate(SequenceEnum.ORDERLY_SEQ.value(),
SeqConstants.NABEL_SAMPLE_STRUCTURE_SEQ);
return TypeUtils.stringValueOf(sequence);
}
public static String getApplyOrderCode(String prefix) {
Object sequence = CommonApiFactory.getSequenceGenerator().generate(SequenceEnum.ORDERLY_SEQ.value(),
SeqConstants.NABEL_SAMPLE_APPLY_SEQ);
return SeqConstants.NABEL_SAMPLE_APPLY_PREFIX + prefix + TypeUtils.stringValueOf(sequence);
}Oinone社区 作者:望闲原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/11457.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验