
场景举例
日常有很多项目,数据库中都有表示“多选状态标识”的字段。在这里用我们项目中的一个例子进行说明一下:
- 示例一:
表示某个商家是否支持多种会员卡打折(如有金卡、银卡、其他卡等),项目中的以往的做法是:在每条商家记录中为每种会员卡建立一个标志位字段。如图:


用多字段来表示“多选标识”存在一定的缺点:首先这种设置方式很明显不符合数据库设计第一范式,增加了数据冗余和存储空间。再者,当业务发生变化时,不利于灵活调整。比如,增加了一种新的会员卡类型时,需要在数据表中增加一个新的字段,以适应需求的变化。
- 改进设计:标签位flag设计
二进制的“位”本来就有表示状态的作用。可以用各个位来分别表示不同种类的会员卡打折支持: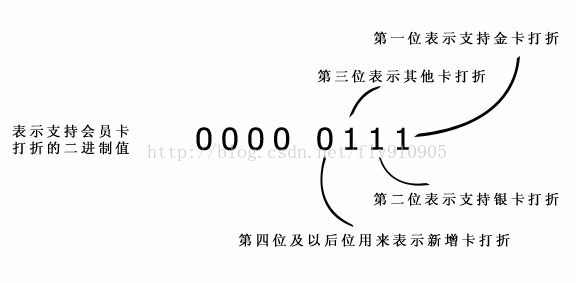
这样,“MEMBERCARD”字段仍采用整型。当某个商家支持金卡打折时,则保存“1(0001)”,支持银卡时,则保存“2(0010)”,两种都支持,则保存“3(0011)”。其他类似。表结构如图:
我们在编写SQL语句时,只需要通过“位”的与运算,就能简单的查询出想要数据。通过这样的处理方式既节省存储空间,查询时又简单方便。
//查询支持金卡打折的商家信息:
select * from factory where MEMBERCARD & b'0001';
// 或者:
select * from factory where MEMBERCARD & 1;
// 查询支持银卡打折的商家信息:
select * from factory where MEMBERCARD & b'0010';
// 或者:
select * from factory where MEMBERCARD & 2;二进制( 位运算)枚举
可以通过@Dict注解设置数据字典的bit属性或者实现BitEnum接口来标识该枚举值为2的次幂。二进制枚举最大的区别在于值的序列化和反序列化方式是不一样的。
位运算的枚举定义示例
import pro.shushi.pamirs.meta.annotation.Dict;
import pro.shushi.pamirs.meta.common.enmu.BitEnum;
@Dict(dictionary = ClientTypeEnum.DICTIONARY, displayName = "客户端类型枚举", summary = "客户端类型枚举")
public enum ClientTypeEnum implements BitEnum {
PC(1L, "PC端", "PC端"),
MOBILE(1L << 1, "移动端", "移动端"),
;
public static final String DICTIONARY = "base.ClientTypeEnum";
private final Long value;
private final String displayName;
private final String help;
ClientTypeEnum(Long value, String displayName, String help) {
this.value = value;
this.displayName = displayName;
this.help = help;
}
@Override
public Long value() {
return value;
}
@Override
public String displayName() {
return displayName;
}
@Override
public String help() {
return help;
}
}使用方法示例
-
API: addTo 和 removeFrom
List<ClientTypeEnum> clientTypes = module.getClientTypes(); // addTo ClientTypeEnum.PC.addTo(clientTypes); // removeFrom ClientTypeEnum.PC.removeFrom(clientTypes); -
在查询条件中的使用
List<Menu> moduleMenus = new Menu().queryListByWrapper(menuPage, LoaderUtils.authQuery(wrapper).eq(Menu::getClientTypes, ClientTypeEnum.PC));
Oinone社区 作者:nation原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/4757.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验