
总体介绍
-
Oinone的分库分表方案是基于Sharding-JDBC的整合方案,要先具备一些Sharding-JDBC的知识。[Sharding-JDBC]https://shardingsphere.apache.org/document/current/cn/overview/
-
做分库分表前,大家要有一个明确注意的点就是分表字段(也叫
均衡字段)的选择,它是非常重要的,与业务场景非常相关。在明确了分库分表字段以后,甚至在功能上都要做一些妥协。比如分库分表字段在查询管理中做为查询条件是必须带上的,不然效率只会更低。 -
分表字段不允许更新,所以代码里更新策略设置类永不更新,并在设置了在页面修改的时候为readonly
配置分表策略
- 配置ShardingModel模型走分库分表的数据源pamirsSharding
- 为pamirsSharding配置数据源以及sharding规则
a. pamirs.sharding.define用于oinone的数据库表创建用
b. pamirs.sharding.rule用于分表规则配置 -
为pamirsSharding配置数据源以及sharding规则
1)指定模型对应数据源
pamirs:
framework:
system:
system-ds-key: base
system-models:
- base.WorkerNode
data:
default-ds-key: pamirs
ds-map:
base: base
modelDsMap:
"[demo.ShardingModel]": pamirsSharding #配置模型对应的库2)分库分表规则配置
pamirs:
sharding:
define:
data-sources:
ds: pamirs
pamirsSharding: pamirs #申明pamirsSharding库对应的pamirs数据源
models:
"[trigger.PamirsSchedule]":
tables: 0..13
"[demo.ShardingModel]":
tables: 0..7
table-separator: _
rule:
pamirsSharding: #配置pamirsSharding库的分库分表规则
actual-ds:
- pamirs #申明pamirsSharding库对应的pamirs数据源
sharding-rules:
# Configure sharding rule ,以下配置跟sharding-jdbc配置一致
- tables:
demo_core_sharding_model: #demo_core_sharding_model表规则配置
actualDataNodes: pamirs.demo_core_sharding_model_${0..7}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
table_inline:
type: INLINE
props:
algorithm-expression: demo_core_sharding_model_${(Long.valueOf(user_id) % 8)}
props:
sql.show: true自定义规则
- 默认规则即通用的分库分表策略,如按照数据量、哈希等方式进行分库分表;通常默认规则是可以的。
- 但在一些复杂的业务场景下,使用默认规则可能无法满足需求,需要根据实际情况进行自定义。例如,某些业务可能有特定的数据分布模式或者查询特点,需要定制化的分库分表规则来优化数据访问性能或者满足业务需求。在这种情况下,使用自定义规则可以更好地适应业务的需求。
自定义分表规则示例
示例1:按月份分表(DATE_MONTH )
package pro.shushi.pamirs.demo.core.sharding;
import cn.hutool.core.date.DateUtil;
import com.google.common.collect.Range;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j;
import java.util.*;
/**
* @author wangxian
* @version 1.0
* @description
*/
@Component
@Slf4j
public class DateMonthShardingAlgorithm implements StandardShardingAlgorithm<Date> {
private Properties props;
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> preciseShardingValue) {
Date date = preciseShardingValue.getValue();
String suffix = "_" + (DateUtil.month(date) + 1);
for (String tableName : availableTargetNames) {
if (tableName.endsWith(suffix)) {
return tableName;
}
}
throw new IllegalArgumentException("未找到匹配的数据表");
}
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Date> rangeShardingValue) {
List<String> list = new ArrayList<>();
log.info(rangeShardingValue.toString());
Range<Date> valueRange = rangeShardingValue.getValueRange();
Date lowerDate = valueRange.lowerEndpoint();
Date upperDate = valueRange.upperEndpoint();
Integer begin = DateUtil.month(lowerDate) + 1;
Integer end = DateUtil.month(upperDate) + 1;
TreeSet<String> suffixList = ShardingUtils.getSuffixListForRange(begin, end);
for (String tableName : availableTargetNames) {
if (containTableName(suffixList, tableName)) {
list.add(tableName);
}
}
return list;
}
private boolean containTableName(Set<String> suffixList, String tableName) {
boolean flag = false;
for (String s : suffixList) {
if (tableName.endsWith(s)) {
flag = true;
break;
}
}
return flag;
}
@Override
public void init() {
}
@Override
public String getType() {
return "DATE_MONTH";
}
@Override
public Properties getProps() {
return this.props;
}
@Override
public void setProps(Properties properties) {
this.props = props;
}
}示例2:按特定字段截取去取模分表
package pro.shushi.pamirs.demo.core.sharding;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j;
import java.util.Collection;
import java.util.Properties;
/**
* @author wangxian
* @version 1.0
* @description
*/
@Component
@Slf4j
public class AppUserCodeShardingAlgorithm implements StandardShardingAlgorithm<String> {
private Properties props;
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> preciseShardingValue) {
String appUserCode = preciseShardingValue.getValue();
String suffix = "_" + Long.parseLong(appUserCode.substring(1)) % 21;
for (String tableName : availableTargetNames) {
if (tableName.endsWith(suffix)) {
return tableName;
}
}
throw new IllegalArgumentException("未找到匹配的数据表");
}
@Override
public Collection<String> doSharding(final Collection<String> availableTargetNames, final RangeShardingValue<String> shardingValue) {
return availableTargetNames;
}
@Override
public String getType() {
return "APP_USER_CODE_TYPE";
}
@Override
public Properties getProps() {
return this.props;
}
@Override
public void setProps(Properties properties) {
this.props = props;
}
@Override
public void init() {
}
}使用自定义分表策略
1)指定模型对应数据源
pamirs:
framework:
system:
system-ds-key: base
system-models:
- base.WorkerNode
data:
default-ds-key: pamirs_biz
ds-map:
base: base
demo_core: pamirs
modelDsMap:
"[demo.record.MsgRecode]": pamirsSharding2)分库分表规则配置
pamirs:
sharding:
define:
data-sources:
ds: pamirs
pamirsSharding: pamirs
models:
"[trigger.PamirsSchedule]":
tables: 0..13
"[demo.record.MsgRecode]":
tables: 0..20
table-separator: _
rule:
pamirsSharding:
actual-ds:
- pamirs
sharding-rules:
- tables:
demo_core_record_msg_recode:
actualDataNodes: pamirs.demo_core_record_msg_recode_${0..20}
tableStrategy:
standard:
shardingColumn: app_user_code
shardingAlgorithmName: app_user_code_table_algorithm
shardingAlgorithms:
app_user_code_table_algorithm:
type: APP_USER_CODE_TYPE
props:
strategy: STANDARD
algorithmClassName:
pro.shushi.pamirs.demo.core.sharding.AppUserCodeShardingAlgorithm配置自定义规则SPI
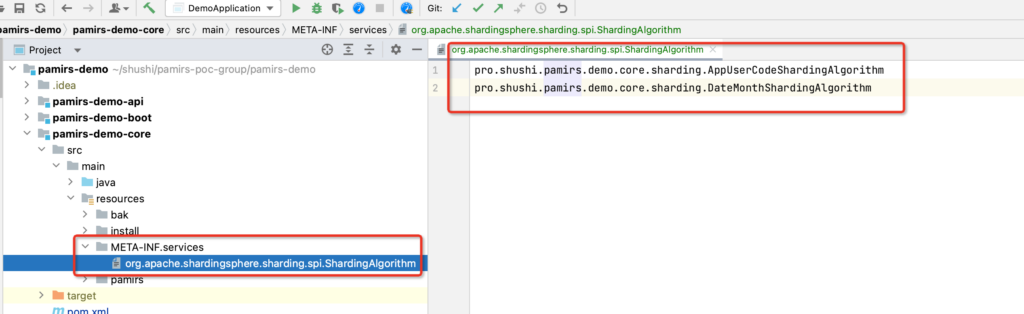

在resources/META-INF/services 配置 org.apache.shardingsphere.sharding.spi.ShardingAlgorithm
pro.shushi.pamirs.demo.core.sharding.AppUserCodeShardingAlgorithm
pro.shushi.pamirs.demo.core.sharding.DateMonthShardingAlgorithmOinone社区 作者:望闲原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/7155.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验