
1、非存储字段搜索
1.1 描述
通常根据本模型之外的信息作为搜索条件时,通常会把 这些字段放在代理模型上。这类场景我们称之为 非存储字段搜索
1.2 场景一
非存储字段为基本的String。
1.代码定义:非存储字段为基本的包装数据类型
@Field(displayName = "确认密码", store = NullableBoolEnum.FALSE)
private String confirmPassword;2.设计器拖拽:列表中需要有退拽这个字段,字段是否隐藏的逻辑自身业务是否需要决定。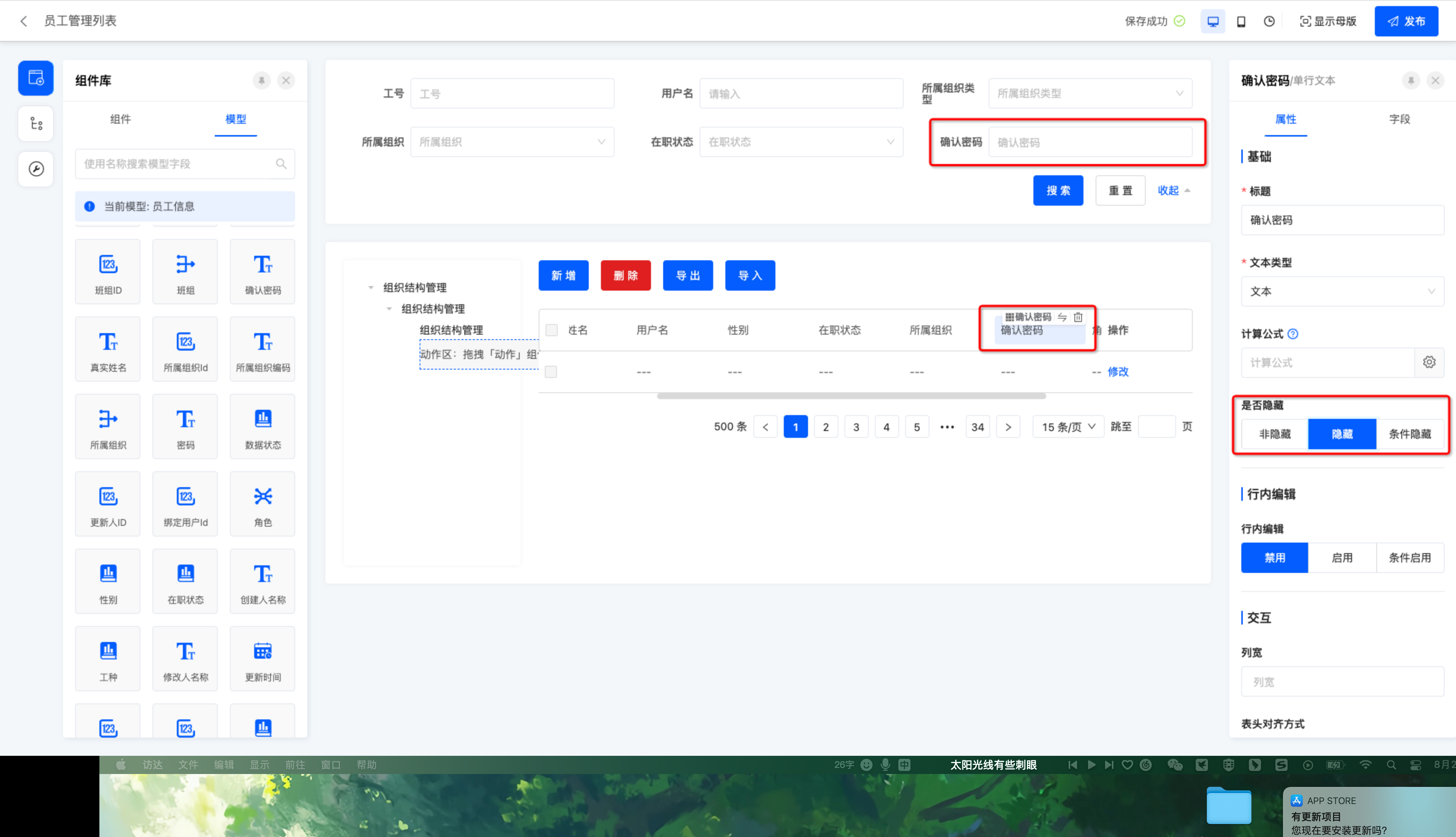

3.页面通过非存储字段为基本的包装数据类型进行搜索时。会拼在 queryWrapper 的属性queryData中,queryData为Map,key为字段名,value为搜索值。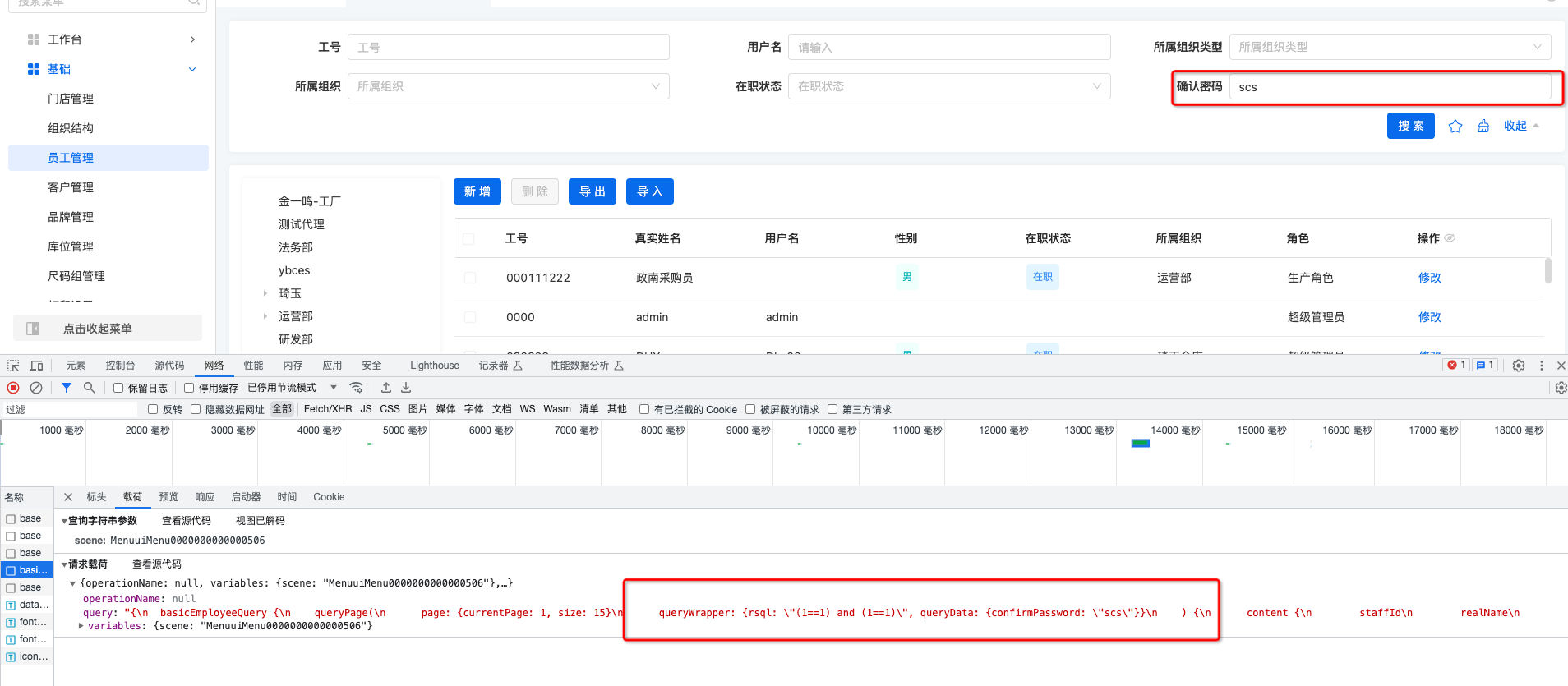
4.后台逻辑处理代码示例:
Map<String, Object> queryData = queryWrapper.getQueryData();
if (null != queryData) {
Object productIdObj = queryData.get(PRODUCT_ID);
if (Objects.nonNull(productIdObj)) {
String productId = productIdObj.toString();
queryWrapper.lambda().eq(MesProduceOrderProxy::getProductId, productId);
}
}1.3 场景二
非存储字段为非存储对象。
- 定义 为非存储的
@Field(displayName = "款", store = NullableBoolEnum.FALSE) @Field.many2one @Field.Relation(store = false) private MesProduct product;
2.页面在搜索栏拖拽非存储字段作为搜索条件
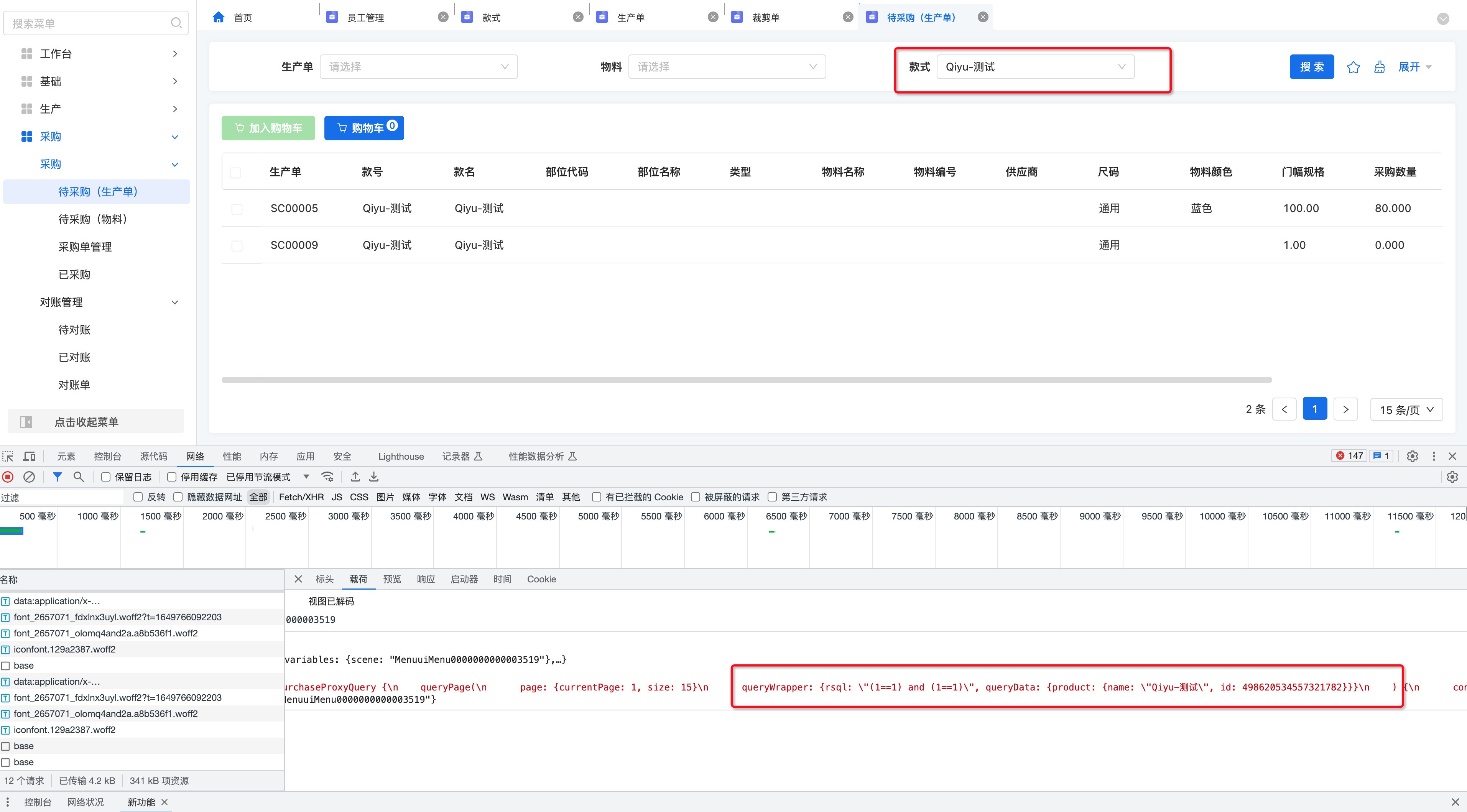
3.后台逻辑处理代码示例:
try {
if (null != queryData && !queryData.isEmpty()) {
List<Long> detailId = null;
BasicSupplier supplier = JsonUtils.parseMap2Object((Map<String, Object>) queryData.get(supplierField), BasicSupplier.class);
MesProduct product = JsonUtils.parseMap2Object((Map<String, Object>) queryData.get(productField), MesProduct.class);
MesMaterial material = JsonUtils.parseMap2Object((Map<String, Object>) queryData.get(materialField), MesMaterial.class);
if (supplier != null) {
detailId = bomService.queryBomDetailIdBySupplierId(supplier.getId());
if (CollectionUtils.isEmpty(detailId)) {
detailId.add(-1L);
}
}
if (product != null) {
List<Long> produceOrderId = produceOrderService.queryProductOrderIdByProductIds(product.getId());
if (CollectionUtils.isNotEmpty(produceOrderId)) {
queryWrapper.lambda().in(MesProduceBomSizes::getProduceOrderId, produceOrderId);
}
}
if (material != null) {
//找出两个bom列表的并集
List<Long> materBomDetailId = bomService.queryBomDetailIdByMaterialId(material.getId());
if (CollectionUtils.isNotEmpty(detailId)) {
detailId = detailId.stream().filter(materBomDetailId::contains).collect(Collectors.toList());
} else {
detailId = new ArrayList<>();
if (CollectionUtils.isEmpty(materBomDetailId)) {
detailId.add(-1L);
} else {
detailId.addAll(materBomDetailId);
}
}
}
if (CollectionUtils.isNotEmpty(detailId)) {
queryWrapper.lambda().in(MesProduceBomSizes::getProductBomId, detailId);
}
}
} catch (Exception e) {
log.error("queryData处理异常", e);
}注意: 如果这样定义
@Field(displayName = "款",store = NullableBoolEnum.FALSE)
@Field.Relation(relationFields = "produceId", referenceFields = "id",store = false)
@Field.many2one
private MesProduct product;
@Field(displayName = "款Id",store = NullableBoolEnum.FALSE)
private Long produceId;
搜索时 produceId 选择product 搜索是 produceId 会被拼接在QueryWrapper 的Rsql中
Rsql解析类
pro.shushi.pamirs.framework.gateways.rsql.RSQLHelper
Rsql参考代码
/**
* Rsql解析 将属性字段值从QueryWrapper中originRsql属性值的Rsql解出来
* 将原有条件替换成 ’1‘==’1‘
*
* @param queryWrapper 查询Wrapper
* @param fields 需要解析出来的属性字段列表
* @param valeMap 属性对应值的Map
* @return 返回生产单Id列表
*/
public static QueryWrapper convertWrapper(QueryWrapper queryWrapper, List<String> fields, Map<String, Object> valeMap) {
if (StringUtils.isNotBlank(queryWrapper.getOriginRsql())) {
String rsql = RSQLHelper.toTargetString(RSQLHelper.parse(queryWrapper.getModel(), queryWrapper.getOriginRsql()), new RSQLNodeConnector() {
@Override
public String comparisonConnector(RSQLNodeInfo nodeInfo) {
//判断字段为unStore,则进行替换
String field = nodeInfo.getField();
if (fields.contains(field)) {
valeMap.put(field, nodeInfo.getArguments().get(0));
RSQLNodeInfo newNode = new RSQLNodeInfo(nodeInfo.getType());
//设置查询字段为name
newNode.setField("1");
newNode.setOperator(RsqlSearchOperation.EQUAL.getOperator());
newNode.setArguments(Collections.singletonList("1"));
return super.comparisonConnector(newNode);
}
return super.comparisonConnector(nodeInfo);
}
});
queryWrapper = Pops.f(Pops.query().from(queryWrapper.getModel())).get();
//把RSQL转换成SQL
String sql = RsqlParseHelper.parseRsql2Sql(queryWrapper.getModel(), rsql);
if (StringUtils.isNotBlank(sql)) {
queryWrapper.apply(sql);
}
return queryWrapper;
}
return queryWrapper;
}Oinone社区 作者:shao原创文章,如若转载,请注明出处:https://doc.oinone.top/dai-ma-shi-jian/5592.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验