虚拟机异常退出再启动后,docker run 出现错误:
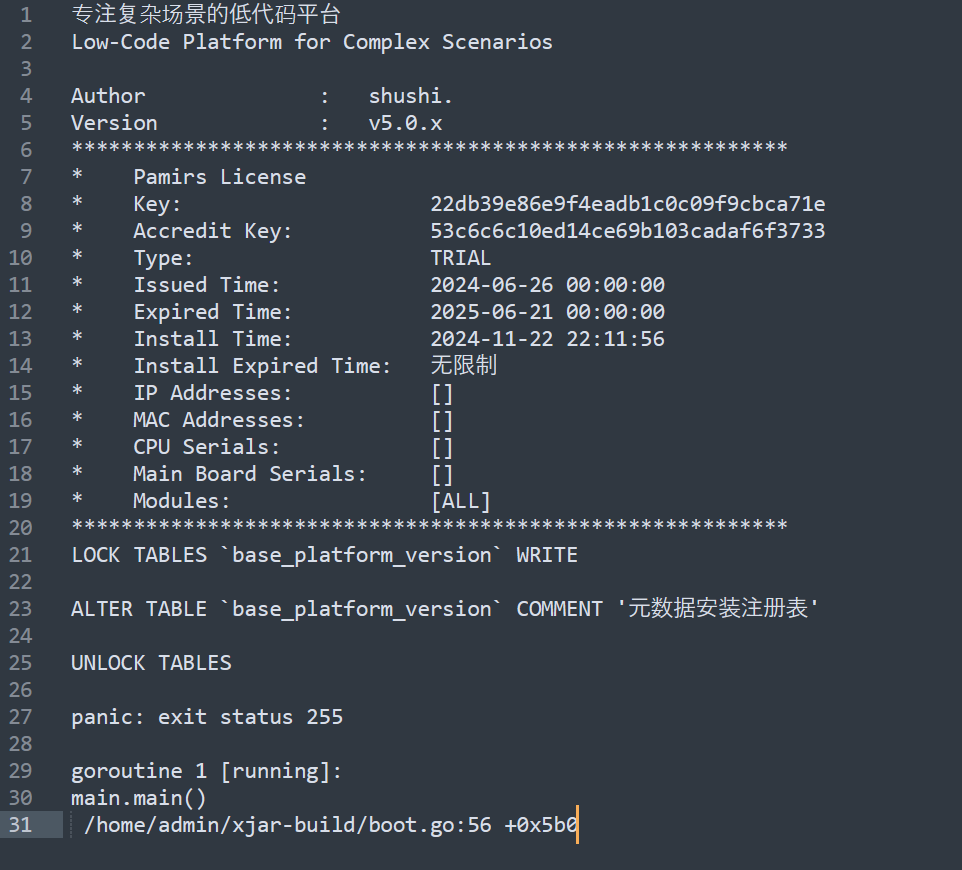

查看所有容器发现确实存在一个容器,status是 exited(255)
docker container ls -all
删除这个容器,命令 docker run 容器id
docker rm 56e0
本文来自投稿,不代表Oinone社区立场,如若转载,请注明出处:https://doc.oinone.top/backend/19571.html

虚拟机异常退出再启动后,docker run 出现错误:
查看所有容器发现确实存在一个容器,status是 exited(255)
docker container ls -all
删除这个容器,命令 docker run 容器id
docker rm 56e0
本文来自投稿,不代表Oinone社区立场,如若转载,请注明出处:https://doc.oinone.top/backend/19571.html
1.邮件发送 1.1 邮件服务设置 1.1.1 方法一:通过yaml文件配置 pamirs: email: smtp: smtpHost: smtp.exmail.qq.com smtpUser: xxx@xxx.com smtpPassword: xxxxxx smtpPort: 465 smtpSecurity: SSL #邮件模块可后续后台自行添加 templates: – name: 邮箱注册邮件 title: '${code}是你此次注册的验证码' body: '<div>Hi ${realname},</div><div>你正在使用验证码注册。</div>' 1.1.2 方法二:工程启动加入初始化设置方法 /** * 初始化邮件模板 */ private void initEmailTemplate(){ EmailSenderSource emailSenderSource = new EmailSenderSource(); emailSenderSource.setName("邮件发送服务"); emailSenderSource.setType(MessageEngineTypeEnum.EMAIL_SEND); //优先级 emailSenderSource.setSequence(10); //发送账号 emailSenderSource.setSmtpUser("xxx@xxx.com"); //发送密码 emailSenderSource.setSmtpPassword("xxxxxx"); //发送服务器地址和端口 emailSenderSource.setSmtpHost("smtp.exmail.qq.com"); emailSenderSource.setSmtpPort(465); //" None: SMTP 对话用明文完成。" + //" TLS (STARTTLS): SMTP对话的开始时要求TLS 加密 (建议)" + //" SSL/TLS: SMTP对话通过专用端口用 SSL/TLS 加密 (默认是: 465)") emailSenderSource.setSmtpSecurity(EmailSendSecurityEnum.SSL); emailSenderSource.setActive(true); emailSenderSource.createOrUpdate(); List<EmailTemplate> templates = new ArrayList<>(); templates.add(new EmailTemplate().setName("重置密码邮件模板").setTitle("请确认你的密码修改请求").setBody("<div>Hi ${realname},</div><div>你正在使用验证码注册。</div>").setModel(PamirsUser.MODEL_MODEL).setEmailSenderSource(emailSenderSource)); new EmailTemplate().createOrUpdateBatch(templates); } 1.2 调用邮件发送组件发送邮件 /** * 代码中使用消息组件发送Email */ public void sendEmailByTemplate(){ try { EmailSender emailSender = (EmailSender) MessageEngine.get(MessageEngineTypeEnum.EMAIL_SEND).get(null);; EmailTemplate template = new EmailTemplate().setName("邮件模版名称").queryOne(); //标题:${name} //内容:${fieldInt}次数 String sendTo = "xxx@xxx.com"; String copyTo = "yyy@yyy.com"; Map<String, Object> objectData = new HashMap<>(); objectData.put("name","张三"); objectData.put("fieldInt",999); Boolean aBoolean = emailSender.send(template, objectData, sendTo, copyTo); if (null == aBoolean || !aBoolean) { log.error("发送邮件失败"); } } catch (Exception e) { log.error("发送确认邮件失败:,异常:{}", e); } } 2.发送短信 2.1 短信通道设置 2.1.1 方法一:通过yaml文件配置 pamirs: sms: aliyun: signatureMethod: HMAC-SHA1 endpoint: https://dysmsapi.aliyuncs.com version: '2017-05-25' accessKeyId: xxxxxxxxxxxxx signatureVersion: '1.0' accessKeySecret: xxxxxxxxxxxx regionId: cn-hangzhou timeZone: GMT signName: xxxxxx 2.1.2 方法二:工程启动加入初始化设置方法 private void…
1.实现SPI接口 import pro.shushi.pamirs.meta.common.spi.SPI; import pro.shushi.pamirs.meta.common.spi.factory.SpringServiceLoaderFactory; import pro.shushi.pamirs.workflow.app.api.entity.WorkflowContext; import pro.shushi.pamirs.workflow.app.api.model.WorkflowInstance; @SPI(factory = SpringServiceLoaderFactory.class) public interface WorkflowEndNoticeApi { void execute(WorkflowContext context, WorkflowInstance instance); } 自定义通知逻辑 /** * 自定义扩展流程结束时扩展点 */ @Order(999) @Component @SPI.Service public class MyWorkflowEndNoticeApi implements WorkflowEndNoticeApi { @Override public void execute(WorkflowContext context, WorkflowInstance instance) { Long dataBizId = instance.getDataBizId(); //todo自定义逻辑 } }
概述 Oinone提供两种设计器部署方式,合作伙伴可以自行选择适合自己的部署方式。 Docker配置参数 环境变量 ARG_ENV:指定spring.profiles.active(默认:dev) ARG_LIFECYCLE:指定-Plifecycle(默认:INSTALL) JVM_OPTIONS:jvm参数 PROGRAM_ARGS:程序参数 JVM_OPTIONS和PROGRAM_ARGS参数说明 java [JVM_OPTIONS?] -jar boot.jar [PROGRAM_ARGS?] 端口说明 PS:以下为目前设计器镜像的全部端口,不同类型镜像的端口由于内置服务不同,使用的端口数量不同,但端口号是完全一致的。 80:前端服务端口(设计器访问入口) 8091:后端服务端口 8093:后端EIP服务端口 20880:Dubbo端口 3306:内置MySQL端口 2181:内置Zookeeper端口 6379:内置Redis端口 9876/10991:内置RocketMQ端口 9999:内置本地OSS默认端口 挂载目录说明(挂载虚拟卷) /opt/pamirs为镜像的工作目录,所有挂载目录均在该目录下。 /opt/pamirs/ext:应用配置文件目录;包含application.yml、logback.xml、license.lic等配置文件 /opt/pamirs/nginx/vhost:Nginx配置文件目录 /opt/pamirs/logs:后端服务日志目录 /opt/mq/conf/broker.conf:RocketMQ的broker配置文件 /opt/pamirs/outlib:非设计器内置包的外部加载目录(外部库),可以添加任何jar包集成到设计器中。 /opt/pamirs/dist:前端服务目录 /opt/pamirs/static:前端静态文件目录;LOCAL类型的OSS上传和下载目录; docker run启动常用参数 -e:指定环境变量 -p:指定端口映射 -v:指定挂载目录(挂载虚拟卷) docker run [OPTIONS] IMAGE [COMMAND] [ARG…] docker compose启动常用配置 services: container: image: $IMAGE container_name: $CONTAINER_NAME restart: always # docker run -e environment: KEY1: VALUE1 KEY2: VALUE2 … # docker run -p ports: – $machinePort1:$containerPort1 – $machinePort2:$containerPort2 … # docker run -v volumes: – $machinePath1:$containerPath1 – $machinePath2:$containerPath2 … docker compose常用命令 # 使用docker-compose.yaml启动 docker compose up -d # 使用docker-compose.yaml停止并删除容器 docker compose down -v # 指定配置文件启动 docker compose -f config.yaml up -d # 指定配置文件停止并删除容器 docker compose -f config.yaml down -v JAR包方式启动 下载Oinone专属启动器 oinone-boot-starter.zip 启动命令变化 # 原命令 java -jar boot.jar # 变更后命令 boot-starter java -jar boot.jar PS:更多命令可查看后端无代码设计器Jar包启动方法
本文核心是带大家全面了解oinone的序列方式,包括支持的序列化类型、注意点、如果新增客户化序列化方式以及字段默认值的反序列化。 字段序列化方式说明 序列化方式 说明 备注 JSON JSON序列化 主要用于模型相关类型字段的序列化,是@Field.serialize默认选项 DOT 点拼接集合元素 COMMA 逗号拼接集合元素 BIT 按位与,2次幂数求和 非@Field.serialize可选项列表,用于二进制枚举序列化不需要配置,由oinone自动推断 字段序列化方式举例 1、给模型PetItemDetail 增加两个字段:petItemDetails类型为List 和 tags类型为List,并设置为不同的序列化方式,petItemDetails为JSON(缺省就是JSON,可不配),tags为COMMA。2、同时设置 @Field.Advanced(columnDefinition = "varchar(1024)"),防止序列化后存储过长。 @Model.model(PetItem.MODEL_MODEL) @Model(displayName = "宠物商品",summary="宠物商品",labelFields = {"itemName"}) public class PetItem extends AbstractDemoCodeModel{ public static final String MODEL_MODEL="demo.PetItem"; @Field(displayName = "品种") @Field.many2one @Field.Relation(relationFields = {"typeId"},referenceFields = {"id"}) private PetType type; @Field(displayName = "品种类型",invisible = true) private Long typeId; @Field(displayName = "详情", serialize = Field.serialize.JSON, store = NullableBoolEnum.TRUE) @Field.Advanced(columnDefinition = "varchar(1024)") private List<PetItemDetail> petItemDetails; @Field(displayName = "商品标签",serialize = Field.serialize.COMMA,store = NullableBoolEnum.TRUE,multi = true) @Field.Advanced(columnDefinition = "varchar(1024)") private List<String> tags; } 字段序列化注意点 必须使用Field#store属性将字段存储设置为NullableBoolEnum.TRUE。 使用Field#serialize属性指定序列化方式,默认为JSON。 如把PetItemDetail设置为存储模型,须在PetItem的petItemDetails字段上使用Field.Relation#store属性将关联关系存储设置为false。不然会同时存储petItemDetails字段和对应的PetItemDetail表记录 注册自己的序列化器 注册自己的序列化器(实现pro.shushi.pamirs.meta.api.core.orm.serialize.Serializer接口), 如oinone的DOT的序列化方式,用type()方法返回值做匹配,serialize和deserialize分别对应序列化和反序列化方法。 package pro.shushi.pamirs.framework.compute.serialize; import org.apache.commons.lang3.StringUtils; import org.springframework.stereotype.Component; import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j; import pro.shushi.pamirs.meta.api.core.orm.serialize.Serializer; import pro.shushi.pamirs.meta.common.constants.CharacterConstants; import pro.shushi.pamirs.meta.enmu.SerializeEnum; import pro.shushi.pamirs.meta.util.TypeUtils; import java.util.ArrayList; import java.util.Collections; import java.util.List; /** * 点表达式序列生成处理器实现 * @author shushi@shushi.pro * @version 1.0.0 */ @SuppressWarnings("rawtypes") @Slf4j @Component public class DotSerializeProcessor implements Serializer<Object, String> { @Override public String serialize(String ltype, Object value) { if (null == value) { return null; } if (List.class.isAssignableFrom(value.getClass())) { return StringUtils.join((List) value, CharacterConstants.SEPARATOR_DOT); } else { return StringUtils.join(Collections.singletonList(value), CharacterConstants.SEPARATOR_DOT); } } @SuppressWarnings("unchecked") @Override public Object deserialize(String ltype, String ltypeT, String value,…
场景描述 在实际业务场景中,存在复杂SQL的情况,具体表现为: 单表单SQL满足不了的情况下 有复杂的Join关系或者子查询 复杂SQL的逻辑通过程序逻辑难以实现或实现代价较大 在此情况下,通过原生的mybatis/mybatis-plus, 自定义Mapper的方式实现业务功能 1、编写所需的Mapper SQL Mapper写法无限制,与使用原生的mybaits/mybaits-plus用法一样; Mapper(DAO)和SQL可以写在一个文件中,也分开写在两个文件中。 package pro.shushi.pamirs.demo.core.map; import org.apache.ibatis.annotations.Mapper; import org.apache.ibatis.annotations.Param; import org.apache.ibatis.annotations.Select; import java.util.List; import java.util.Map; @Mapper public interface DemoItemMapper { @Select("<script>select sum(item_price) as itemPrice,sum(inventory_quantity) as inventoryQuantity,categoryId from ${demoItemTable} as core_demo_item ${where} group by category_id</script>") List<Map<String, Object>> groupByCategoryId(@Param("demoItemTable") String pamirsUserTable, @Param("where") String where); } 2.调用mapper 调用Mapper代码示例 package pro.shushi.pamirs.demo.core.map; import com.google.api.client.util.Lists; import org.springframework.stereotype.Component; import pro.shushi.pamirs.demo.api.model.DemoItem; import pro.shushi.pamirs.framework.connectors.data.api.datasource.DsHintApi; import pro.shushi.pamirs.meta.api.core.orm.convert.DataConverter; import pro.shushi.pamirs.meta.api.session.PamirsSession; import pro.shushi.pamirs.meta.common.spring.BeanDefinitionUtils; import java.util.List; import java.util.Map; @Component public class DemoItemDAO { public List<DemoItem> customSqlDemoItem(){ try (DsHintApi dsHint = DsHintApi.model(DemoItem.MODEL_MODEL)) { String demoItemTable = PamirsSession.getContext().getModelCache().get(DemoItem.MODEL_MODEL).getTable(); DemoItemMapper demoItemMapper = BeanDefinitionUtils.getBean(DemoItemMapper.class); String where = " where status = 'ACTIVE'"; List<Map<String, Object>> dataList = demoItemMapper.groupByCategoryId(demoItemTable,where); DataConverter persistenceDataConverter = BeanDefinitionUtils.getBean(DataConverter.class); return persistenceDataConverter.out(DemoItem.MODEL_MODEL, dataList); } return Lists.newArrayList(); } } 调用Mapper一些说明 启动类需要配置扫描包MapperScan @MapperScan(value = "pro.shushi", annotationClass = Mapper.class) @SpringBootApplication(exclude = {DataSourceAutoConfiguration.class, FreeMarkerAutoConfiguration.class}) public class DemoApplication { 调用Mapper接口的时候,需要指定数据源;即上述示例代码中的 DsHintApi dsHint = DsHintApi.model(DemoItem.MODEL_MODEL), 实际代码中使用 try-with-resources语法。 从Mapper返回的结果中获取数据 如果SQL Mapper中已定义了resultMap,调用Mapper(DAO)返回的就是Java对象 如果Mapper返回的是Map<String, Object>,则通过 DataConverter.out进行转化,参考上面的示例 其他参考:Oinone连接外部数据源方案:https://doc.oinone.top/backend/4562.html