
项目工程管理
项目工程顶层分层
项目分层设计,划分出 CDM层、 标准业务层 、定制业务层;

- 沉淀领域业务模型至CDM层;
- 沉底业内通用功能至标准业务层;
- 客户定制化功能在定制业务层;
项目内部的层级划分

项目包结构管理及规范
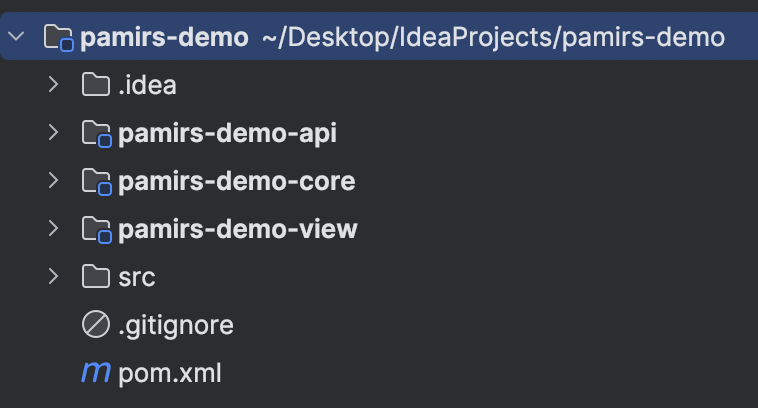
-
pamirs-demo-api
- constant【常量的包路径】
- enums【枚举类的包路径】
- model【该领域核⼼模型的包路径】
- pmodel【该领域代理模型的包路径】
- tmodel【该领域传输模型的包路径】
- service【存放该领域的⾮存储模型如:⽤于传输的临时模型】
- utils【工具类】
- XXModule【该类是Demo模块的定义】
-
pamirs-demo-core
- service【接口实现类】
- init【模块初始化⼯作的包路径】
- manager 【manager是 service的⼀些公共逻辑,不会定义为独⽴的function的类】
-
pamirs-demo-view(可选)
- action【模型对外交互的⾏为的包路径】
项目中模块间依赖
- action【模型对外交互的⾏为的包路径】
-
禁止出现api模块依赖core模块的情况,api模块只允许依赖api模块;
-
根据当前项目结构进行模块划分,避免循环依赖;
规划项目模块
项目阶段,代码开发前,业务架构师需充分的理解需求和蓝图,对系统进行业务域, 功能域的划分;
例如:对一个电商系统:
-
提高系统的可维护性:通过将系统拆分为不同的业务域,每个业务域都有清晰的边界和职责,可以独立开发、测试和维护;
-
提升开发效率:业务域划分可以使开发团队更加专注于自己负责的业务,减少不必要的沟通和协调,提升开发效率;
-
促进团队合作:通过业务域划分,每个团队可以负责一个或多个业务域,团队成员之间可以有更高效的合作和协同。
-
支持系统的扩展和演化:业务域划分可以使系统更加灵活和可扩展。当需要新增一个新的业务功能或调整现有的业务逻辑时,只需要修改对应的业务域,而不需要对整个系统进行改动。
项目文档管理
项目文档管理对于项目的实施,项目进度管理,项目后期维护等都是至关重要的。系统详细的产品文档,测试文档,运维文档,开发文档,项目管理文档等。
-
协同合作:团队成员可以共享和访问项目文档,促进协同合作和信息共享,避免信息孤岛和重复工作。
-
知识管理:项目中所获得的知识,对项目的成功和后续的知识积累至关重要。通过良好的文档管理,可以确保项目知识的保存和传承,提高组织的知识管理能力。
-
问题解决:项目文档中记录了项目的需求、决策、问题和解决方案等信息。当出现问题或需要做决策时,可以通过查阅文档来获取相关信息,加快问题解决的速度,并减少错误和重复。
-
项目追踪:通过文档管理,可以跟踪项目的进展和状态。可以记录项目的里程碑、任务分配、进度更新等信息,帮助团队了解项目的整体情况,及时发现和解决问题。
-
知识共享:好的文档管理可以促进知识共享和传播。通过将项目文档进行分类、索引和存档,可以使团队成员更容易找到所需的信息,并从中学习和借鉴经验,提高工作效率和质量。 
数据库和事务
多表联合查询
减少需要join的操作出现 用多次查询替代
索引相关
- 核心业务访问DB的Sql 要命中或者覆盖索引,保存核心业务的响应时间;
- 控制单表的索引数量,注意联合索引
- 数据一致性:乐观锁控制,unique�等
事务代码示例
事务相关注意点参考【Oinone如何支持构建分布式项目】:https://doc.oinone.top/kai-fa-shi-jian/5572.html
Oinone社区 作者:shao原创文章,如若转载,请注明出处:https://doc.oinone.top/kai-fa-shi-jian/5564.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验