
分布式调用下的[强制]约束
1、[强制]分布式调用情况下base库和redis需共用;
2、[强制]如果环境有设计器,设计器的base库和redis保持一致也需与项目中的保持一致;
3、[强制]相同base库下,不同应用的相同模块的数据源需保持一致;
4、[强制]项目中需引入分布式缓存包。参考下文的分布式包依赖
分布式支持
1、分布式包依赖
1) 父pom的依赖管理中先加入pamirs-distribution的依赖
<dependency>
<groupId>pro.shushi.pamirs</groupId>
<artifactId>pamirs-distribution</artifactId>
<version>${pamirs.distribution.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
2) 启动的boot工程中增加pamirs-distribution相关包
<!-- 分布式服务发布 -->
<dependency>
<groupId>pro.shushi.pamirs.distribution</groupId>
<artifactId>pamirs-distribution-faas</artifactId>
</dependency>
<!-- 分布式元数据缓存 -->
<dependency>
<groupId>pro.shushi.pamirs.distribution</groupId>
<artifactId>pamirs-distribution-session</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.distribution</groupId>
<artifactId>pamirs-distribution-gateway</artifactId>
</dependency>3)启动工程的Application中增加类注解@EnableDubbo
@EnableDubbo
public class XXXStdApplication {
public static void main(String[] args) throws IOException {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// ………………………………
log.info("XXXX Application loading...");
}
}2、修改bootstrap.yml文件
注意序列化方式:serialization: pamirs
以下只是一个示例(zk为注册中心),注册中心支持zk和Nacos;
Nacos作为注册中心参考:https://doc.oinone.top/kai-fa-shi-jian/5835.html
spring:
profiles:
active: dev
application:
name: pamirs-demo
cloud:
service-registry:
auto-registration:
enabled: false
pamirs:
default:
environment-check: true
tenant-check: true
---
spring:
profiles: dev
cloud:
service-registry:
auto-registration:
enabled: false
config:
enabled: false
uri: http://127.0.0.1:7001
label: master
profile: dev
nacos:
server-addr: http://127.0.0.1:8848
discovery:
enabled: false
namespace:
prefix: application
file-extension: yml
config:
enabled: false
namespace:
prefix: application
file-extension: yml
dubbo:
application:
name: pamirs-demo
version: 1.0.0
registry:
address: zookeeper://127.0.0.1:2181
protocol:
name: dubbo
port: -1
serialization: pamirs
scan:
base-packages: pro.shushi
cloud:
subscribed-services:
metadata-report:
disabled: true3、模块启动的最⼩集
pamirs:
boot:
init: true
sync: true
modules:
- base
- sequence
- 业务工程的Module4、业务模型间的依赖关系
- 服务调用方(即Client端),在启动yml中modules不安装服务提供方的Module
- 服务调用方(即Client端),项目的pom中只依赖服务提供方的API(即模型和API的定义)
- 服务调用方(即Client端),项目模块定义(即模型Module定义),dependencies中增加服务提供方的Modeule. 如下面示例代码中的FileModule
@Module( name = DemoModule.MODULE_NAME, displayName = "oinoneDemo工程", version = "1.0.0", dependencies = {ModuleConstants.MODULE_BASE, CommonModule.MODULE_MODULE, FileModule.MODULE_MODULE, SecondModule.MODULE_MODULE/**服务提供方的模块定义*/ } ) - 服务调用方(即Client端),启动类的
ComponentScan需要配置服务提供方API定义所在的包. 如下面示例中的:pro.shushi.pamirs.second@ComponentScan( basePackages = {"pro.shushi.pamirs.meta", "pro.shushi.pamirs.framework", "pro.shushi.pamirs", "pro.shushi.pamirs.demo", "pro.shushi.pamirs.second" /**服务提供方API定义所在的包*/ }, excludeFilters = { @ComponentScan.Filter( type = FilterType.ASSIGNABLE_TYPE, value = {RedisAutoConfiguration.class, RedisRepositoriesAutoConfiguration.class, RedisClusterConfig.class} ) }) @Slf4j @EnableTransactionManagement @EnableAsync @EnableDubbo @MapperScan(value = "pro.shushi.pamirs", annotationClass = Mapper.class) @SpringBootApplication(exclude = {DataSourceAutoConfiguration.class, FreeMarkerAutoConfiguration.class}) public class DemoApplication {
5、模块启动顺序
服务提供方的模块需先启动。原因:模块在启动过程中,会校验依赖模块是否存在。
6、Dubbo日志相关
关闭Dubbo元数据上报
dubbo:
metadata-report:
disabled: true关闭元数据上报,还有错误日志打印出来的话,可以在log中配置
logging:
level:
root: info
pro.shushi.pamirs.framework.connectors.data.mapper.PamirsMapper: info
pro.shushi.pamirs.framework.connectors.data.mapper.GenericMapper: info # mybatis sql日志
RocketmqClient: error
# Dubbo相关的日志
org.apache.dubbo.registry.zookeeper.ZookeeperRegistry: error
org.apache.dubbo.registry.integration.RegistryDirectory: error
org.apache.dubbo.registry.client.metadata.store.RemoteMetadataServiceImpl: off
org.apache.dubbo.metadata.store.zookeeper.ZookeeperMetadataReport: off
org.apache.dubbo.metadata.store.nacos.NacosMetadataReport: off更详细的教程参考:https://shushi.yuque.com/yoxz76/oio3/deaa1p
分布式支持-事务相关
1、分布式事务解决方案
完成某一个业务功能可能需要横跨多个服务,操作多个数据库。这就涉及到到了分布式事务,分布式事务就是为了保证不同资源服务器的数据一致性。典型的分布式事务场景:
1、跨库事务, 补充具体场景
2、微服务拆分带来的跨内部服务;
3、微服务拆分带来的跨外部服务;
2、事务策略
采用微服务架构,需考虑分布式事务问题(即平台各子系统之间的数据一致性)。
1)对于单个系统/模型内部, 比如:库存中心、账户中心等,采用强事务的方式。比如:在扣减库存的时候,库存日志和库存数列的变化在一个事务中,保证两个表的数据同时成功或者失败。
强事务管理采用编码式,Oinone事务管理兼容Spring的事务管理方式;
2)为了提高系统的可用性、可扩展性和性能,对于某些关键业务和数据一致性要求特别高的场景,采用强一致性外,其他的场景建议采用最终一致性的方案;
对于分布式事务采用最终数据一致性,借助可靠消息和 Job 等方式来实现。
2.1 基于MQ的事务消息
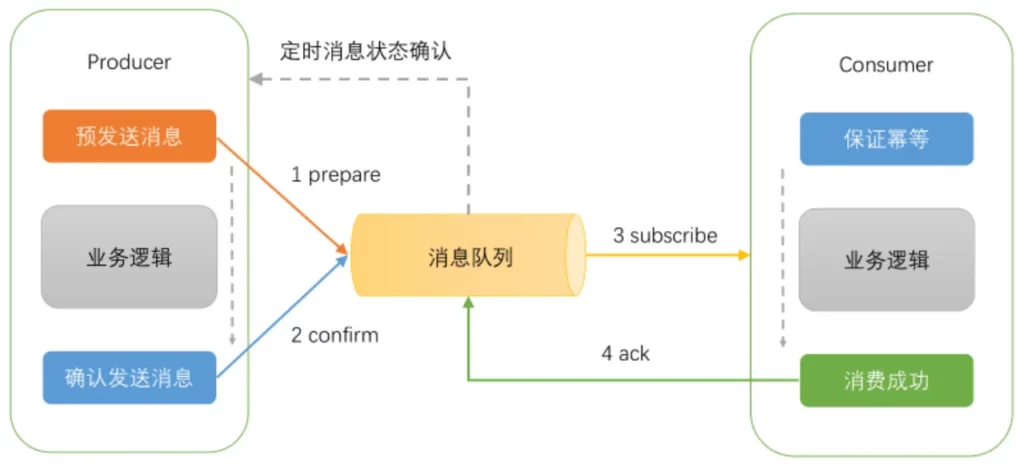

采用最终一致性方案,基于MQ的事务消息的方式。
事务消息的逻辑由发送端 Producer进行保证(消费端无需考虑)。基于MQ事务消息的实现步骤:
1)首先,发送一个事务消息,MQ将消息状态标记为Prepared,注意此时这条消息消费者是无法消费到的。
2)接着,执行业务代码逻辑,可能是一个本地数据库事务操作
3)确认发送消息,这个时候,MQ将消息状态标记为可消费,这个时候消费者,才能真正的保证消费到这条数据。
2.2 基于JOB的补偿
定期校对:业务活动的被动方,根据定时策略,向业务活动主动方查询(主动方提供查询接口),恢复丢失的业务消息。
2.3 数据一致性
- 对RPC超时和重试机制设计的检查,是否会带来重复数据
- 对数据幂等、去重机制的设计是否有考虑到
- 对事务、数据(最终)一致性设计是否有考虑到
- 数据缓存时,当数据发生变化时,是否有相应的机制保证缓存数据的一致性和有效性
Oinone构建分布式项目一些注意点
参考文档:https://doc.oinone.top/kai-fa-shi-jian/6475.html
Oinone社区 作者:shao原创文章,如若转载,请注明出处:https://doc.oinone.top/kai-fa-shi-jian/5572.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验