
1.首先通过sql查询找到我们需要的页面,从其中的template字段复制出原视图的配置
通过模型编码model在base_view查找需要修改的视图
select * from base_view where model='workflow.WorkflowUserTask' and is_deleted = 0;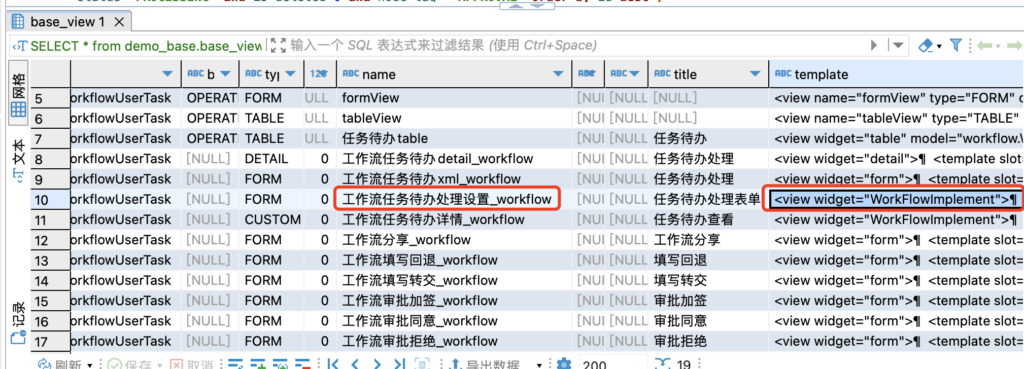

2.将base_view的template内容复制到java的core工程的resources目录下新建一个xml文件,修改里面的动作名称
<view widget="WorkFlowImplement">
<template slot="actions">
<action name="$$internal_GotoListTableRouter" priority="1" model="workflow.WorkflowUserTask" tag="contextFreeAction"/>
<action name="approveStaging" widget="FlowTaskCommonAction" invisible="!(activeRecord.allowStaging)" priority="2" label="新暂存" model="workflow.WorkflowUserTask" displayName="新暂存"/>
<action name="workflow_agree" invisible="!(activeRecord.allowAgree && activeRecord.status == 'ACTIVE')" priority="3" label="新同意" model="workflow.WorkflowUserTask" load="fetchDetailReadOnly" displayName="新同意" goBack="true" validateForm="true" loadRootData="true"/>
<action name="workflow_rejust" invisible="!(activeRecord.allowReject && activeRecord.status == 'ACTIVE')" priority="4" label="新拒绝" model="workflow.WorkflowUserTask" displayName="新拒绝" goBack="true" loadRootData="true" tag="contextFreeAction"/>
<action name="workflow_turnon" invisible="!(activeRecord.taskType == 'APPROVE' && activeRecord.allowTransfer && activeRecord.status == 'ACTIVE')" priority="5" label="新转交" model="workflow.WorkflowUserTask" load="fetchDetailReadOnly" displayName="新转交" goBack="true" loadRootData="true" tag="contextFreeAction"/>
<action name="workflow_addsign" invisible="!(activeRecord.taskType == 'APPROVE' && activeRecord.allowAddSign && activeRecord.status == 'ACTIVE')" priority="6" label="新加签" model="workflow.WorkflowUserTask" load="fetchDetailReadOnly" displayName="新加签" goBack="true" loadRootData="true" tag="contextFreeAction"/>
<action name="workflow_write_fallback" invisible="!(activeRecord.taskType == 'WRITE' && activeRecord.allowFallback && activeRecord.status == 'ACTIVE')" priority="7" label="新回退" model="workflow.WorkflowUserTask" displayName="新回退" goBack="true" loadRootData="true" tag="contextFreeAction"/>
<action name="workflow_sharing" priority="8" label="新分享" model="workflow.WorkflowUserTask" displayName="新分享" goBack="true" loadRootData="true" tag="contextFreeAction"/>
</template>
<template slot="fields">
<field name="remark" widget="TextArea" invisible="activeRecord.taskType != 'APPROVE'" priority="8" model="workflow.WorkflowUserTask" data="remark" displayName="意见备注"/>
</template>
</view>
3.在生命周期的元数据编辑方法内覆盖视图
package pro.shushi.pamirs.demo.core.init;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.boot.common.api.command.AppLifecycleCommand;
import pro.shushi.pamirs.boot.common.extend.MetaDataEditor;
import pro.shushi.pamirs.core.common.InitializationUtil;
import pro.shushi.pamirs.demo.api.DemoModule;
import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j;
import pro.shushi.pamirs.meta.api.dto.meta.Meta;
import pro.shushi.pamirs.meta.enmu.ViewTypeEnum;
import pro.shushi.pamirs.workflow.app.api.model.WorkflowUserTask;
import java.util.Map;
@Slf4j
@Component
@Order(Ordered.LOWEST_PRECEDENCE)
public class DemoModuleMetaInstall implements MetaDataEditor {
@Override
public void edit(AppLifecycleCommand command, Map<String, Meta> metaMap) {
InitializationUtil util = InitializationUtil.get(metaMap, DemoModule.MODULE_MODULE, DemoModule.MODULE_NAME);
if (util != null) {
// 参数按base_view内的数据填写
util.createView(WorkflowUserTask.MODEL_MODEL, "任务待办处理表单", "工作流任务待办处理设置_workflow", "file:pamirs/workflow_task_todo_form.xml", ViewTypeEnum.FORM, 10, false);
}
}
}Oinone社区 作者:nation原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/14331.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验