
目录
1. 使用工作流需要依赖的包和设置
2. 触发方式
2.1 自动触发方式
2.2 触发方式
1.使用工作流需要依赖的包和设置
1.1 工作流需要依赖的模块
需在pom.xml中增加workflow、sql-record和trigger相关模块的依赖
- workflow:工作流运行核心模块
- sql-record:监听流程发布以后对应模型的增删改监听
- trigger:异步任务调度模块
<dependency>
<groupId>pro.shushi.pamirs.workflow</groupId>
<artifactId>pamirs-workflow-api</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.workflow</groupId>
<artifactId>pamirs-workflow-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-sql-record-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-trigger-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-trigger-bridge-tbschedule</artifactId>
</dependency>在application.yml中增加对应模块的依赖以及sql-record路径以及其他相关设置
pamirs:
...
record:
sql:
#改成自己路径
store: /opt/pamirs/logs
...
boot:
init: true
sync: true
modules:
...
- sql_record
- trigger
- workflow
...
sharding:
define:
data-sources:
ds:
pamirs
models:
"[trigger.PamirsSchedule]":
tables: 0..13
event:
enabled: true
schedule:
enabled: true
# ownSign区分不同应用
ownSign: demo
rocket-mq:
# enabled 为 false情况不用配置
namesrv-addr: 192.168.6.2:19876
trigger:
auto-trigger: true2.触发方式
2.1自动触发方式
在流程设计器中设置触发方式,如果设置了代码触发方式则不会自动触发
2.2代码调用方式触发
2.2.1.再流程设计器中触发设置中,设置为是否人工触发设置为是
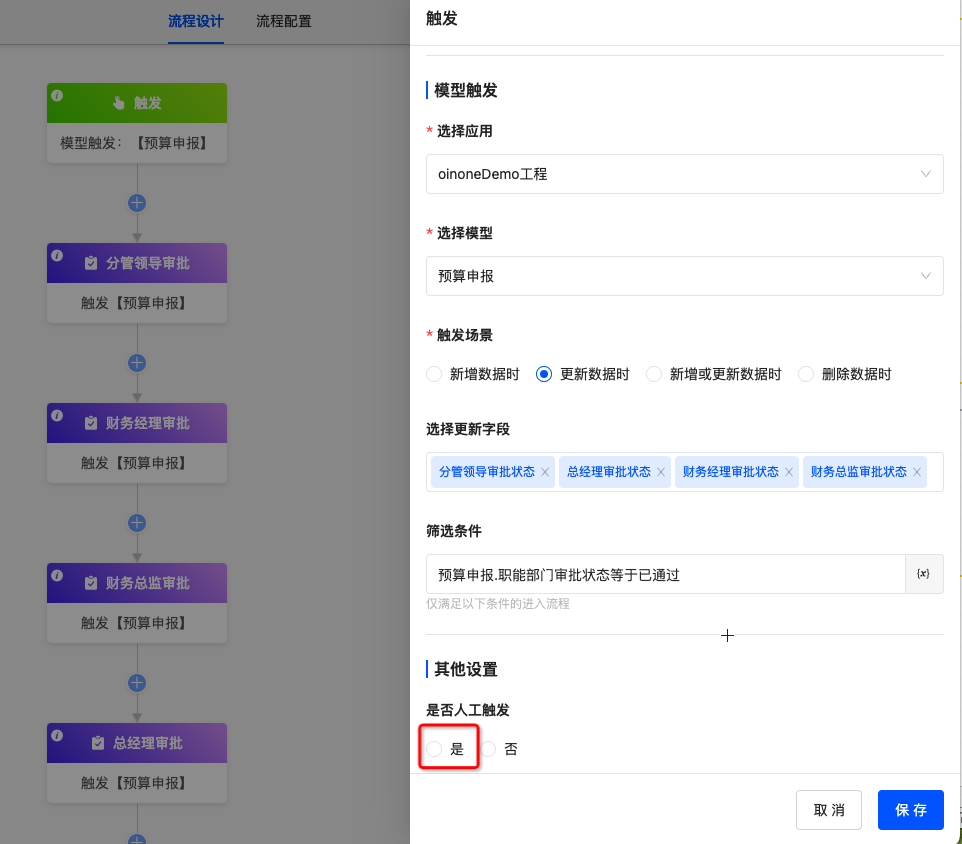

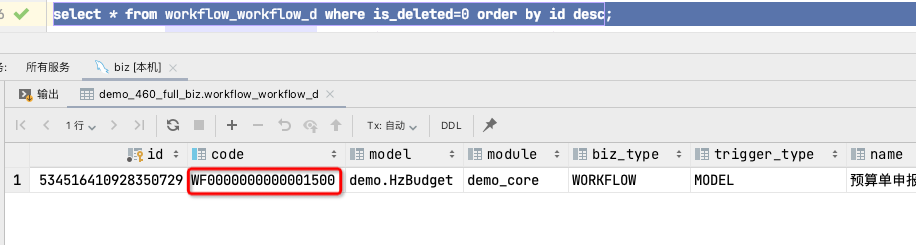
2.2.2.查询数据库获取该流程的编码
2.2.3.在代码中调用
/**
* 触发⼯作流实例
*/
private Boolean startWorkflow(WorkflowD workflowD, IdModel modelData) {
WorkflowDefinition workflowDefinition = new WorkflowDefinition().queryOneByWrapper(
Pops.<WorkflowDefinition>lambdaQuery()
.from(WorkflowDefinition.MODEL_MODEL)
.eq(WorkflowDefinition::getWorkflowCode, workflowD.getCode())
.eq(WorkflowDefinition::getActive, 1)
);
if (null == workflowDefinition) {
// 流程没有运⾏实例
return Boolean.FALSE;
}
String model = Models.api().getModel(modelData);
//⼯作流上下⽂
WorkflowDataContext wdc = new WorkflowDataContext();
wdc.setDataType(WorkflowVariationTypeEnum.ADD);
wdc.setModel(model);
wdc.setWorkflowDefinitionDefinition(workflowDefinition.parseContent());
wdc.setWorkflowDefinition(workflowDefinition);
wdc.setWorkflowDefinitionId(workflowDefinition.getId());
IdModel copyData = KryoUtils.get().copy(modelData);
// ⼿动触发创建的动作流,将操作⼈设置为当前⽤户,作为流程的发起⼈
copyData.setCreateUid(PamirsSession.getUserId());
copyData.setWriteUid(PamirsSession.getUserId());
String jsonData = JsonUtils.toJSONString(copyData.get_d());
//触发⼯作流 新增时触发-onCreateManual 更新时触发-onUpdateManual
Fun.run(WorkflowModelTriggerFunction.FUN_NAMESPACE, "onCreateManual", wdc, msgId, jsonData);
return Boolean.TRUE;
}Oinone社区 作者:数式-海波原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/4361.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验