
场景描述
在碰到大数据量并且需要全文检索的场景,我们在分布式架构中基本会架设ElasticSearch来作为一个常规解决方案。在oinone体系中增强模型就是应对这类场景,其背后也是整合了ElasticSearch;
使用前你应该
- 了解ElasticSearch,包括不限于:Index(索引)、分词、Node(节点)、Document(文档)、Shards(分片) & Replicas(副本)。参考官方网站:https://www.elastic.co/cn/
- 有一个可用的ElasticSearch环境(本地项目能引用到)
前置约束
增强模型增量依赖数据变更实时消息,因此确保项目的event是开启的,mq配置正确。
项目引入搜索步骤
1、boot工程加入相关依赖包
- boot工程需要指定ES客户端包版本,不指定版本会隐性依赖顶层spring-boot依赖管理指定的低版本
- boot工程加入pamris-channel的工程依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.4.1</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-sql-record-core</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-channel-core</artifactId>
</dependency>2、api工程加入相关依赖包
在XXX-api中增加入pamirs-channel-api的依赖
<dependency>
<groupId>pro.shushi.pamirs.core</groupId>
<artifactId>pamirs-channel-api</artifactId>
</dependency>3、yml文件配置
在pamirs-demo-boot的application-dev.yml文件中增加配置pamirs.boot.modules增加channel,即在启动模块中增加channel模块。同时注意es的配置,是否跟es的服务一致
pamirs:
record:
sql:
#改成自己本地路径(或服务器路径)
store: /Users/oinone/record
boot:
modules:
- channel
## 确保也安装了sql_record
- sql_record
channel:
packages:
# 增强模型扫描包配置
- com.xxx.xxx
elastic:
url: 127.0.0.1:92004、项目的模块增加模块依赖
XXXModule增加对ChannelModule的依赖
@Module(dependencies = {ChannelModule.MODULE_MODULE})5、增加增强模型(举例)
package pro.shushi.pamirs.demo.api.enhance;
import pro.shushi.pamirs.channel.enmu.IncrementEnum;
import pro.shushi.pamirs.channel.meta.Enhance;
import pro.shushi.pamirs.channel.meta.EnhanceModel;
import pro.shushi.pamirs.demo.api.model.ShardingModel;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.ModelTypeEnum;
@Model(displayName = "测试EnhanceModel")
@Model.model(ShardingModelEnhance.MODEL_MODEL)
@Model.Advanced(type = ModelTypeEnum.PROXY, inherited = {EnhanceModel.MODEL_MODEL})
@Enhance(shards = "3", replicas = "1", reAlias = true,increment= IncrementEnum.OPEN)
public class ShardingModelEnhance extends ShardingModel {
public static final String MODEL_MODEL="demo.ShardingModelEnhance";
}6、重启系统看效果
1、进入【传输增强模型】应用,访问增强模型列表我们会发现一条记录,并点击【全量同步】初始化ES,并全量dump数据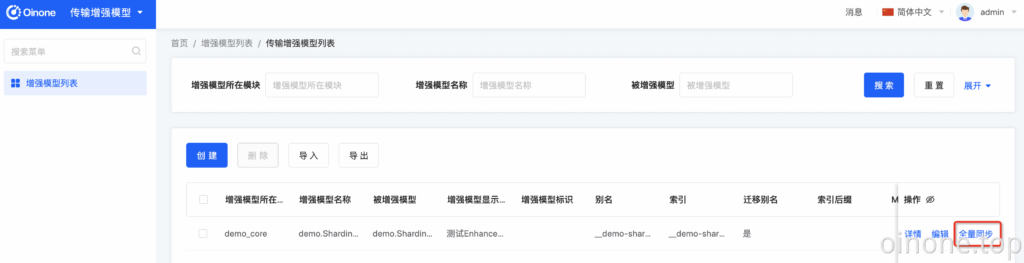

2、再次回到Demo应用,进入增强模型页面,可以正常访问并进增删改查操作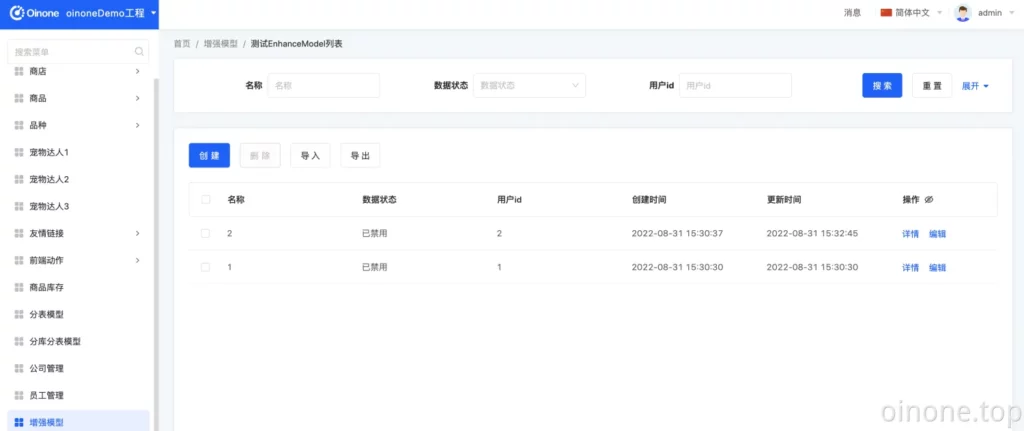
个性化dump逻辑
通常dump逻辑是有个性化需求,那么我们可以重写模型的synchronize方法,函数重写特性在“面向对象-继承与多态”部分中已经有详细介绍。
重写ShardingModelEnhance模型的synchronize方法
重写后,如果针对老数据记录需要把新增的字段都自动填充,可以进入【传输增强模型】应用,访问增强模型列表,找到对应的记录并点击【全量同步】
package pro.shushi.pamirs.demo.api.enhance;
import pro.shushi.pamirs.channel.enmu.IncrementEnum;
import pro.shushi.pamirs.channel.meta.Enhance;
import pro.shushi.pamirs.channel.meta.EnhanceModel;
import pro.shushi.pamirs.demo.api.model.ShardingModel;
import pro.shushi.pamirs.meta.annotation.Field;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.enmu.FunctionTypeEnum;
import pro.shushi.pamirs.meta.enmu.ModelTypeEnum;
import java.util.List;
@Model(displayName = "测试EnhanceModel")
@Model.model(ShardingModelEnhance.MODEL_MODEL)
@Model.Advanced(type = ModelTypeEnum.PROXY, inherited = {EnhanceModel.MODEL_MODEL})
@Enhance(shards = "3", replicas = "1", reAlias = true,increment= IncrementEnum.OPEN)
public class ShardingModelEnhance extends ShardingModel {
public static final String MODEL_MODEL="demo.ShardingModelEnhance";
@Field(displayName = "nick")
private String nick;
@Function.Advanced(displayName = "同步数据", type = FunctionTypeEnum.UPDATE)
@Function(summary = "数据同步函数")
public List<ShardingModelEnhance> synchronize(List<ShardingModelEnhance> data) {
for(ShardingModelEnhance shardingModelEnhance:data){
shardingModelEnhance.setNick(shardingModelEnhance.getName());
}
return data;
}
}给搜索增加个性化逻辑
如果我们需要在查询方法中增加逻辑,在前面的教程中一般是重写queryPage函数,但对于增强模型我们需要重写的是search函数。
个性化search函数
@Function(
summary = "搜索函数",
openLevel = {FunctionOpenEnum.LOCAL, FunctionOpenEnum.REMOTE, FunctionOpenEnum.API}
)
@pro.shushi.pamirs.meta.annotation.Function.Advanced(
type = {FunctionTypeEnum.QUERY},
category = FunctionCategoryEnum.QUERY_PAGE,
managed = true
)
public Pagination<ShardingModelEnhance> search(Pagination<ShardingModelEnhance> page, IWrapper<ShardingModelEnhance> queryWrapper) {
System.out.println("您的个性化搜索逻辑");
// return ((IElasticRetrieve) CommonApiFactory.getApi(IElasticRetrieve.class)).search(page, queryWrapper);
return ((ElasticSearchApi) CommonApiFactory.getApi(ElasticSearchApi.class)).search(page, queryWrapper);
}个性化search函数示例
@Override
@SuppressWarnings({"rawtypes"})
public <T> Pagination<T> search(Pagination<T> page, IWrapper<T> queryWrapper) {
String modelModel = queryWrapper.getModel();
if (null == modelModel || modelModel.isEmpty()) {
return page;
}
ModelConfig modelCfg = PamirsSession.getContext().getModelConfig(modelModel);
if (null == modelCfg) {
return page;
}
String rsql = queryWrapper.getOriginRsql();
if (StringUtils.isBlank(rsql)) {
rsql = "id>0";
}
BoolQuery.Builder queryBuilder = ElasticRSQLHelper.parseRSQL(modelCfg, rsql);
TermQuery isDeletedTerm = QueryBuilders.term()
.queryName(IS_DELETED)
.field(IS_DELETED).value(0)
.build();
BoolQuery.Builder builder = QueryBuilders.bool().must(new Query(queryBuilder.build()));
builder.must(new Query(isDeletedTerm));
String alias = IndexNaming.aliasByModel(modelModel);
Query query = new Query(builder.build());
log.info("{}", query);
List<Order> orders = Optional.ofNullable(page.getSort()).map(Sort::getOrders).orElse(new ArrayList<>());
int currentPage = Optional.ofNullable(page.getCurrentPage()).orElse(1);
Long size = Optional.ofNullable(page.getSize()).orElse(10L);
int pageSize = size.intValue();
List<SortOptions> sortOptions = new ArrayList<>();
if (CollectionUtils.isEmpty(orders)) {
orders.add(new Order(SortDirectionEnum.DESC, ID));
orders.add(new Order(SortDirectionEnum.DESC, CREATE_DATE));
}
for (Order order : orders) {
sortOptions.add(new SortOptions.Builder()
.field(SortOptionsBuilders.field()
.field(order.getField())
.order(SortDirectionEnum.DESC.equals(order.getDirection()) ? SortOrder.Desc : SortOrder.Asc)
.build())
.build());
}
SearchRequest request = new SearchRequest.Builder()
.index(alias)
.from((currentPage - 1) * pageSize)
.size(pageSize)
.sort(sortOptions)
.query(query)
.highlight(_builder ->
_builder.numberOfFragments(4)
.fragmentSize(50)
.type(HighlighterType.Unified)
.fields("name", HighlightField.of(_fieldBuilder -> _fieldBuilder.preTags(ElasticsearchConstant.HIGH_LIGHT_PREFIX).postTags(ElasticsearchConstant.HIGH_LIGHT_POSTFIX)))
.fields("documentNo", HighlightField.of(_fieldBuilder -> _fieldBuilder.preTags(ElasticsearchConstant.HIGH_LIGHT_PREFIX).postTags(ElasticsearchConstant.HIGH_LIGHT_POSTFIX)))
.fields("keywords", HighlightField.of(_fieldBuilder -> _fieldBuilder.preTags(ElasticsearchConstant.HIGH_LIGHT_PREFIX).postTags(ElasticsearchConstant.HIGH_LIGHT_POSTFIX))))
.build();
SearchResponse<HashMap> response = null;
try {
log.info("ES搜索请求参数:{}", request.toString());
response = elasticsearchClient.search(request, HashMap.class);
} catch (ElasticsearchException e) {
log.error("索引异常", e);
PamirsSession.getMessageHub()
.msg(Message.init()
.setLevel(InformationLevelEnum.WARN)
.msg("索引异常"));
return page;
} catch (IOException e) {
log.error("ElasticSearch运行状态异常", e);
PamirsSession.getMessageHub()
.msg(Message.init()
.setLevel(InformationLevelEnum.WARN)
.msg("ElasticSearch运行状态异常"));
return page;
}
if (null == response || response.timedOut()) {
return page;
}
HitsMetadata<HashMap> hits = response.hits();
if (null == hits) {
return page;
}
TotalHits totalHits = hits.total();
long total = Optional.ofNullable(totalHits).map(TotalHits::value).orElse(0L);
List<HashMap> dataMapList = Optional.of(hits)
.map(HitsMetadata<HashMap>::hits)
.map(hitsMap ->{
hitsMap.stream().forEach(highlightForEach -> {
highlightForEach.highlight().forEach((key, value) -> {
if(highlightForEach.source().containsKey(key)){
highlightForEach.source().put(key,value.get(0));
}
});
});
return hitsMap;
})
.map(List::stream)
.orElse(Stream.empty())
.map(Hit::source)
.collect(Collectors.toList());
List<T> context = persistenceDataConverter.out(modelModel, dataMapList);
page.setSize(size);
page.setTotalElements(total);
page.setContent(context);
log.info("ES搜索请求参数返回total,{}", total);
return page;
}Oinone社区 作者:望闲原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/7235.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验