
Oinone请求调用链路
请求格式与简单流程
在Oinone中请求数据存储在请求体中,以GQL的方式进行表示,也就是GQL格式的请求。
当我们发送一个GQL格式的请求,后端会对GQL进行解析,确定想要执行的方法,并对这个方法执行过程中所用到的模型进行构建,最后返回响应。
- 请求
# 请求路径 pamirs/base
http://127.0.0.1:8090/pamirs/base
# 请求体内容
query{
petShopProxyBQuery{
sayHello(shop:{shopName:"cpc"}){
shopName
}
}
} - 解析
# 简单理解
query 操作类型
petShopProxyBQuery 模块名称 + Query
sayHello 方法 fun
sayHello() 可以传入参数,参数名为 shop
shopName 需要得到的值- 响应
# data中的内容
"data": {
"petShopQuery": {
"hello": {
"shopName": "cpc"
}
}
}具体流程
Oinone是基于SpringBoot的,在Controller中处理请求
会接收所有以 /pamirs 开始的POST请求,/pamirs/后携带的是模块名
@RequestMapping(
value = "/pamirs/{moduleName:^[a-zA-Z][a-zA-Z0-9_]+[a-zA-Z0-9]$}",
method = RequestMethod.POST
)
public String pamirsPost(@PathVariable("moduleName") String moduleName,
@RequestBody PamirsClientRequestParam gql,
HttpServletRequest request,
HttpServletResponse response) {
........
}整体脉络
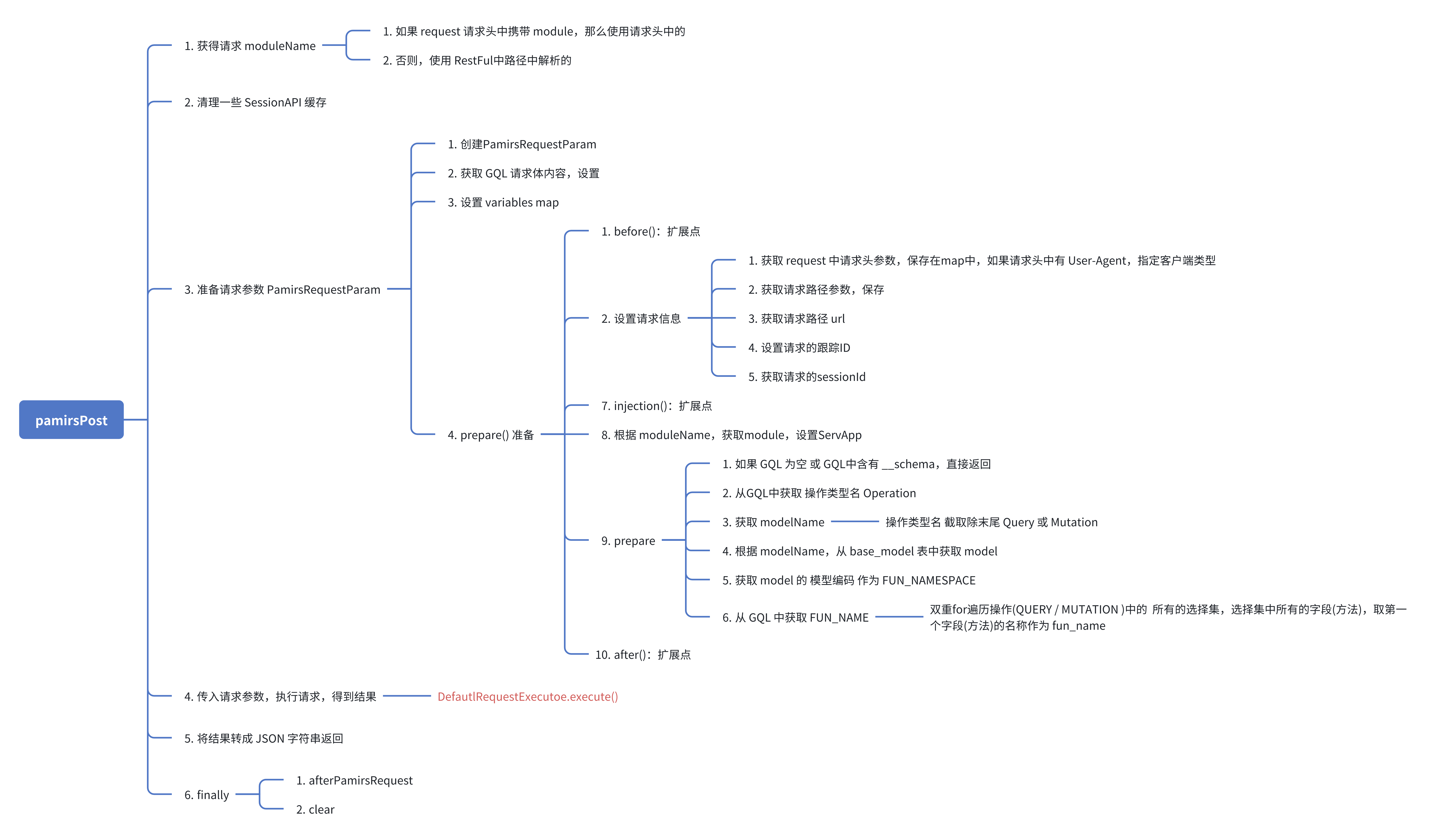

第四步执行中有两大重要的步骤,一步是动态构建GQL,一步是执行请求。
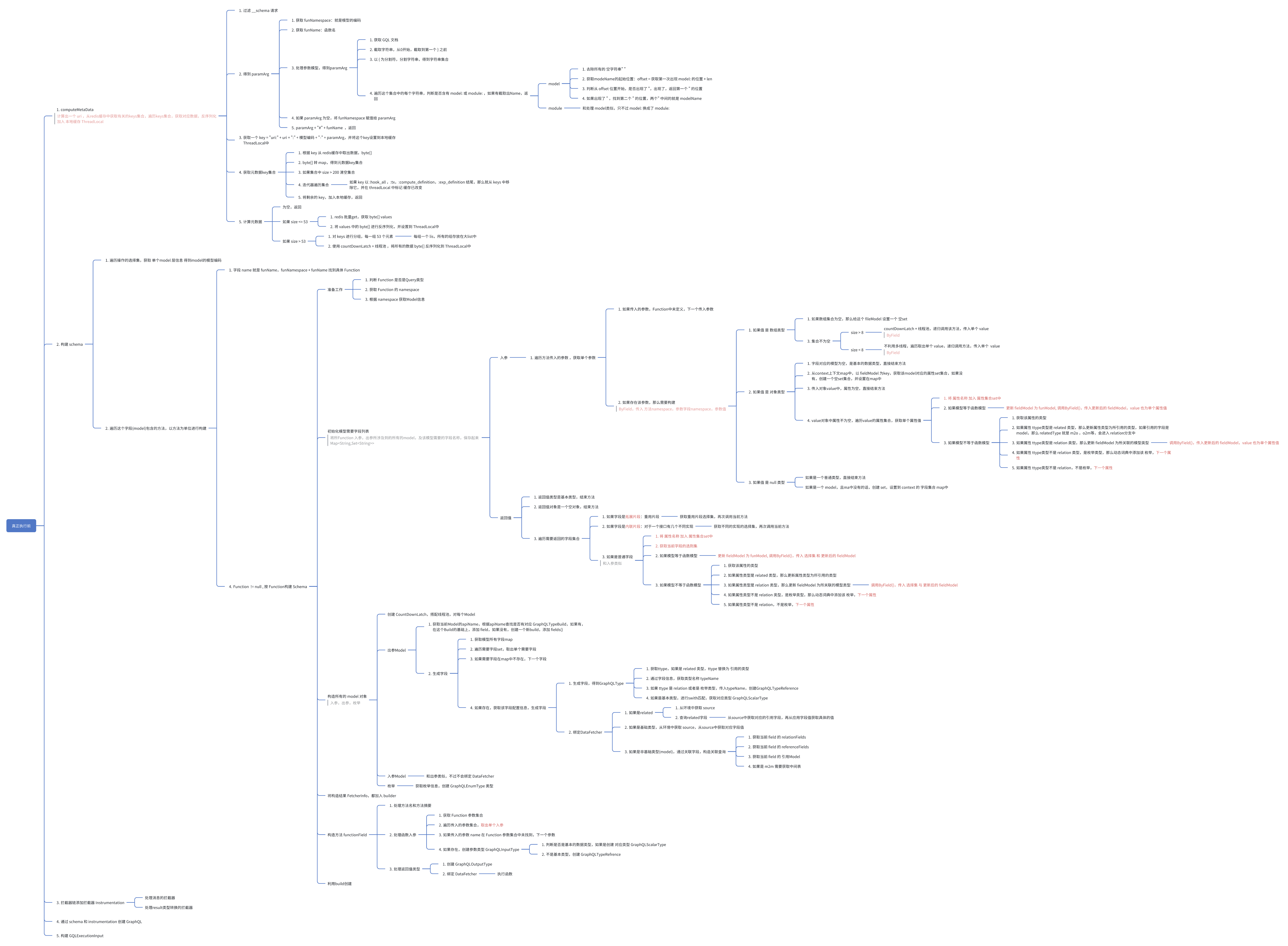
动态构建GQL
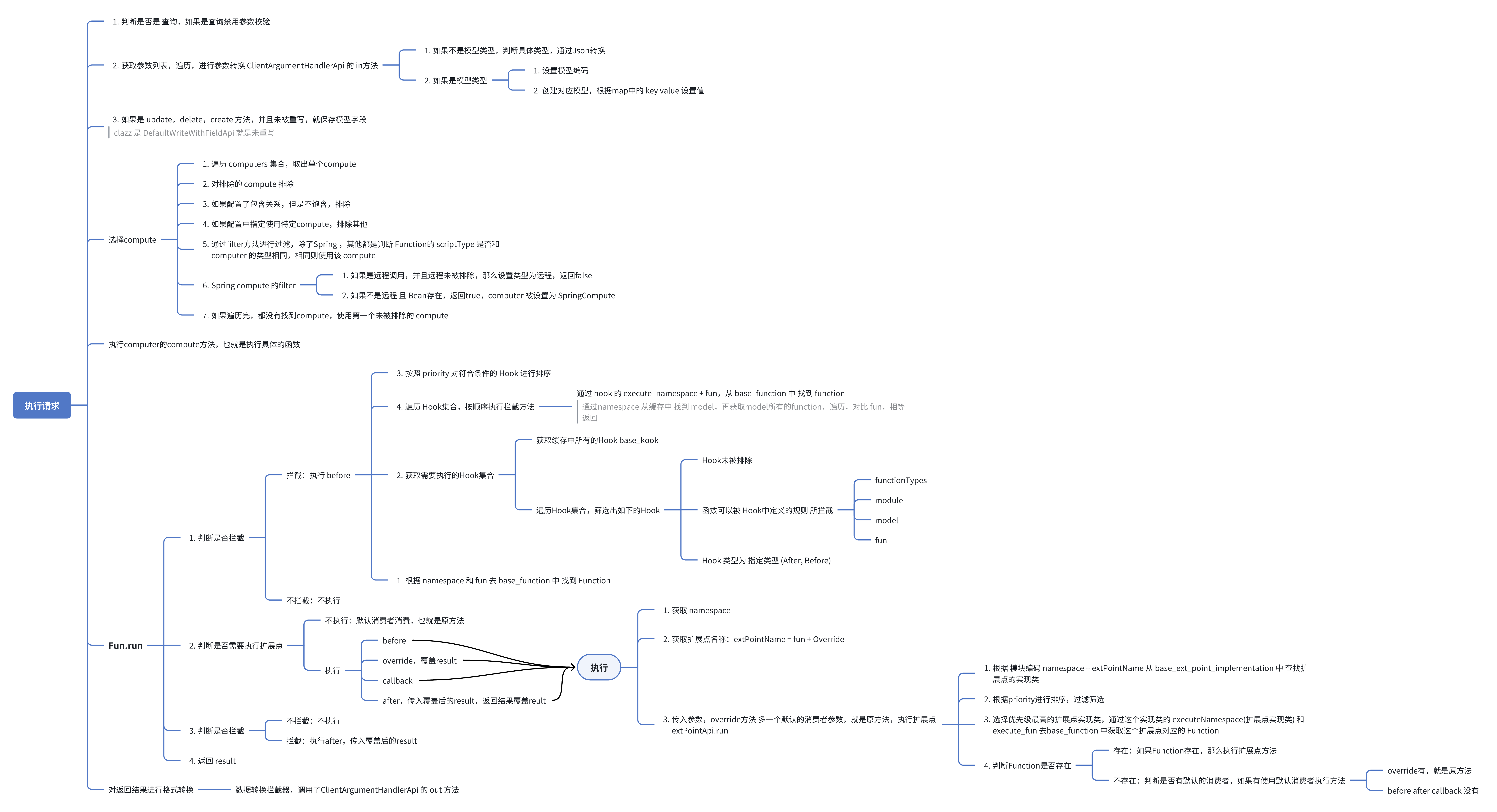
请求执行
Oinone社区 作者:oinone原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/19664.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验