
介绍
本文需要阅读过前置文档如何自定义Excel导出功能,动态表头的功能在前置文档的基础上做的进一步扩展,本文未提到的部分都参考这个前置文档。
在日常的业务开发中,我们在导出的场景会遇到需要设置动态表头的场景,比如统计商品在最近1个月的销量,固定表头列为商品的名称等基础信息,动态表头列为最近一个月的日期,在导出的时候设置每个日期的销量,本文将通过此业务场景提供示例代码。
1.自定义导出任务模型
package pro.shushi.pamirs.demo.api.model;
import pro.shushi.pamirs.file.api.model.ExcelExportTask;
import pro.shushi.pamirs.meta.annotation.Model;
@Model.model(DemoItemDynamicExcelExportTask.MODEL_MODEL)
@Model(displayName = "商品-Excel动态表头导出任务")
public class DemoItemDynamicExcelExportTask extends ExcelExportTask {
public static final String MODEL_MODEL = "demo.DemoItemDynamicExcelExportTask";
}2.自定义导出任务处理数据的扩展点
package pro.shushi.pamirs.demo.core.excel.exportdemo.extPoint;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.core.common.FetchUtil;
import pro.shushi.pamirs.core.common.cache.MemoryIterableSearchCache;
import pro.shushi.pamirs.demo.api.model.DemoItem;
import pro.shushi.pamirs.file.api.config.FileConstant;
import pro.shushi.pamirs.file.api.context.ExcelDefinitionContext;
import pro.shushi.pamirs.file.api.enmu.ExcelTemplateTypeEnum;
import pro.shushi.pamirs.file.api.entity.EasyExcelCellDefinition;
import pro.shushi.pamirs.file.api.extpoint.impl.ExcelExportSameQueryPageTemplate;
import pro.shushi.pamirs.file.api.model.ExcelExportTask;
import pro.shushi.pamirs.file.api.model.ExcelWorkbookDefinition;
import pro.shushi.pamirs.file.api.util.ExcelFixedHeadHelper;
import pro.shushi.pamirs.file.api.util.ExcelHelper;
import pro.shushi.pamirs.file.api.util.ExcelTemplateInit;
import pro.shushi.pamirs.framework.common.entry.TreeNode;
import pro.shushi.pamirs.meta.annotation.ExtPoint;
import pro.shushi.pamirs.meta.api.CommonApiFactory;
import pro.shushi.pamirs.meta.api.core.orm.ReadApi;
import pro.shushi.pamirs.meta.api.core.orm.systems.relation.RelationReadApi;
import pro.shushi.pamirs.meta.api.dto.config.ModelConfig;
import pro.shushi.pamirs.meta.api.dto.config.ModelFieldConfig;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.meta.enmu.TtypeEnum;
import pro.shushi.pamirs.meta.util.FieldUtils;
import java.util.*;
@Component
public class DemoItemDynamicExportExtPoint extends ExcelExportSameQueryPageTemplate<DemoItem> implements ExcelTemplateInit {
public static final String TEMPLATE_NAME ="商品动态导出";
@Override
public List<ExcelWorkbookDefinition> generator() {
ExcelFixedHeadHelper excelFixedHeadHelper = ExcelHelper.fixedHeader(DemoItem.MODEL_MODEL,TEMPLATE_NAME)
.createBlock(TEMPLATE_NAME, DemoItem.MODEL_MODEL)
.setType(ExcelTemplateTypeEnum.EXPORT);
return Collections.singletonList(excelFixedHeadHelper.build());
}
public static void buildHeader(ExcelFixedHeadHelper excelFixedHeadHelper) {
excelFixedHeadHelper.addColumn("name","名称")
.addColumn("cateName","类目")
.addColumn("searchFrom","搜索来源")
.addColumn("description","描述")
.addColumn("itemPrice","单价")
.addColumn("inventoryQuantity","库存");
}
@Override
@ExtPoint.Implement(expression = "context.model == \"" + DemoItem.MODEL_MODEL+"\" && context.name == \"" +TEMPLATE_NAME+"\"" )
public List<Object> fetchExportData(ExcelExportTask exportTask, ExcelDefinitionContext context) {
List<Object> result = super.fetchExportData(exportTask,context);
Object block = result.get(0);
if (block instanceof ArrayList) {
((List<Object>) block).forEach(o -> {
if (o instanceof DemoItem) {
DemoItem item = (DemoItem) o;
// TODO 设置动态表头部分字段的值
item.get_d().put("2024-09-10", "1111");
item.get_d().put("2024-09-11", "2222");
}
});
}
return result;
}
protected <DM extends ReadApi> boolean selectRelationField(DM dataManager, String model, List<TreeNode<EasyExcelCellDefinition>> fieldNodeList, Collection<?> list, Integer maxSupportLength, int currentMaxLength) {
Set<String> hasQueryFields = new HashSet<>();
RelationReadApi relationManagerProcessor = CommonApiFactory.getApi(RelationReadApi.class);
ModelConfig modelConfig = PamirsSession.getContext().getModelConfig(model);
if (modelConfig == null) {
return true;
}
MemoryIterableSearchCache<String, ModelFieldConfig> modelFieldsCache = new MemoryIterableSearchCache<>(modelConfig.getModelFieldConfigList(), ModelFieldConfig::getLname);
for (TreeNode<EasyExcelCellDefinition> fieldNode : fieldNodeList) {
String fieldKey = fieldNode.getKey();
TreeNode<EasyExcelCellDefinition> parentFieldNode = fieldNode.getParent();
if (parentFieldNode != null) {
fieldKey = fieldKey.substring(parentFieldNode.getKey().length() + 1);
int pi = fieldKey.indexOf(FileConstant.POINT_CHARACTER);
if (pi != -1) {
fieldKey = fieldKey.substring(0, pi);
}
}
ModelFieldConfig modelFieldConfig = modelFieldsCache.get(fieldKey);
if (modelFieldConfig == null) {
continue;
// throw new IllegalArgumentException("模板中存在无效的模型字段 model=" + model + ", field=" + fieldKey);
}
if (!TtypeEnum.isRelationType(modelFieldConfig.getTtype())) {
continue;
}
List<Object> needQueryList = new ArrayList<>();
for (Object item : list) {
if (relationManagerProcessor.isNeedQueryRelation(modelFieldConfig, FieldUtils.getFieldValue(item, modelFieldConfig.getLname()))) {
needQueryList.add(item);
}
}
if (needQueryList.isEmpty()) {
continue;
}
String field, indexString;
int li = fieldKey.indexOf("["), ri = fieldKey.indexOf("]"), index;
if (li != -1 && ri != -1) {
indexString = fieldKey.substring(li + 1, ri);
index = Integer.parseInt(indexString);
field = fieldKey.substring(0, li);
if (!hasQueryFields.contains(field)) {
currentMaxLength = computeCurrentMaxLength(maxSupportLength, currentMaxLength, needQueryList.size(), FetchUtil.listFieldQuery(dataManager, needQueryList, modelFieldsCache.get(field), maxSupportLength));
hasQueryFields.add(field);
}
if (index < needQueryList.size()) {
Object value = needQueryList.get(index);
if (!selectRelationField(dataManager, modelFieldConfig.getReferences(), fieldNode.getChildren(), Collections.singletonList(value), maxSupportLength, currentMaxLength)) {
return false;
}
}
} else if (li == -1 && ri == -1) {
field = fieldKey;
if (!hasQueryFields.contains(field)) {
currentMaxLength = computeCurrentMaxLength(maxSupportLength, currentMaxLength, needQueryList.size(), FetchUtil.listFieldQuery(dataManager, needQueryList, modelFieldsCache.get(field), maxSupportLength));
if (currentMaxLength == -1) {
return false;
}
hasQueryFields.add(field);
}
boolean isCollection = fieldNode.getValue().getIsCollection();
List<Object> childList = new ArrayList<>();
for (Object item : needQueryList) {
Object relationValue = FieldUtils.getFieldValue(item, field);
if (relationValue == null) {
continue;
}
if (isCollection) {
childList.addAll((Collection<?>) relationValue);
} else {
childList.add(relationValue);
}
}
if (!selectRelationField(dataManager, modelFieldConfig.getReferences(), fieldNode.getChildren(), childList, maxSupportLength, currentMaxLength)) {
return false;
}
}
}
return true;
}
private int computeCurrentMaxLength(int excelMaxSupportLength, int currentMaxLength, int needQuerySize, int listFieldQuerySize) {
int incrementalSize = listFieldQuerySize - needQuerySize;
if (incrementalSize <= 0) {
return currentMaxLength;
}
currentMaxLength += incrementalSize;
if (currentMaxLength > excelMaxSupportLength) {
return -1;
}
return currentMaxLength;
}
}3.自定义导出任务的action
package pro.shushi.pamirs.demo.core.action;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.demo.api.model.DemoItemDynamicExcelExportTask;
import pro.shushi.pamirs.demo.core.excel.exportdemo.extPoint.DemoItemDynamicExportExtPoint;
import pro.shushi.pamirs.file.api.action.AbstractExcelExportTaskAction;
import pro.shushi.pamirs.file.api.config.ExcelConstant;
import pro.shushi.pamirs.file.api.context.ExcelDefinitionContext;
import pro.shushi.pamirs.file.api.enmu.FileExpEnumerate;
import pro.shushi.pamirs.file.api.model.ExcelWorkbookDefinition;
import pro.shushi.pamirs.file.api.util.ExcelFixedHeadHelper;
import pro.shushi.pamirs.file.api.util.ExcelHelper;
import pro.shushi.pamirs.file.api.util.ExcelWorkbookDefinitionUtil;
import pro.shushi.pamirs.meta.annotation.Action;
import pro.shushi.pamirs.meta.annotation.Function;
import pro.shushi.pamirs.meta.annotation.Model;
import pro.shushi.pamirs.meta.annotation.fun.extern.Slf4j;
import pro.shushi.pamirs.meta.api.dto.config.ModelConfig;
import pro.shushi.pamirs.meta.api.session.PamirsSession;
import pro.shushi.pamirs.meta.common.exception.PamirsException;
import pro.shushi.pamirs.meta.enmu.ActionContextTypeEnum;
import pro.shushi.pamirs.meta.enmu.FunctionOpenEnum;
import pro.shushi.pamirs.meta.enmu.FunctionTypeEnum;
import pro.shushi.pamirs.meta.enmu.ViewTypeEnum;
@Slf4j
@Component
@Model.model(DemoItemDynamicExcelExportTask.MODEL_MODEL)
public class DemoItemDynamicExcelExportTaskAction extends AbstractExcelExportTaskAction<DemoItemDynamicExcelExportTask> {
@Action(displayName = "导出", contextType = ActionContextTypeEnum.CONTEXT_FREE, bindingType = {ViewTypeEnum.TABLE})
public DemoItemDynamicExcelExportTask createExportTask(DemoItemDynamicExcelExportTask data) {
if (data.getWorkbookDefinitionId() != null) {
ExcelWorkbookDefinition workbookDefinition = new ExcelWorkbookDefinition();
workbookDefinition.setId(data.getWorkbookDefinitionId());
data.setWorkbookDefinition(workbookDefinition);
}
super.createExportTask(data);
return data;
}
protected ExcelDefinitionContext fetchExcelDefinitionContextByWorkbookDefinition(DemoItemDynamicExcelExportTask data) {
String model = data.getModel();
if (StringUtils.isBlank(model)) {
throw PamirsException.construct(FileExpEnumerate.EXPORT_MODEL_IS_NULL).errThrow();
}
ModelConfig modelConfig = PamirsSession.getContext().getSimpleModelConfig(model);
if (modelConfig == null) {
throw PamirsException.construct(FileExpEnumerate.EXPORT_MODEL_NOT_EXIST).errThrow();
}
ExcelFixedHeadHelper fixedHeadHelper = ExcelHelper.fixedHeader(model, DemoItemDynamicExportExtPoint.TEMPLATE_NAME)
.setDisplayName(modelConfig.getDisplayName() + ExcelConstant.EXPORT_NAME)
.createBlock(modelConfig.getDisplayName(), model);
// 自定义excel START
DemoItemDynamicExportExtPoint.buildHeader(fixedHeadHelper);
// TODO 构建动态表头 addColumn第一个参数为动态字段的名称,第二个参数为在表头中的展示值,数据处理的扩展点内需要设置对应动态字段的值
fixedHeadHelper.addColumn("2024-09-10", "2024-09-10");
fixedHeadHelper.addColumn("2024-09-11", "2024-09-11");
// 自定义excel END
ExcelWorkbookDefinition workbookDefinition = fixedHeadHelper.build();
data.setWorkbookDefinition(workbookDefinition);
processClearExportStyle(data);
return ExcelWorkbookDefinitionUtil.getDefinitionContext(workbookDefinition);
}
/**
* @param data
* @return
*/
@Function(openLevel = FunctionOpenEnum.API)
@Function.Advanced(type = FunctionTypeEnum.QUERY)
public DemoItemDynamicExcelExportTask construct(DemoItemDynamicExcelExportTask data) {
data.construct();
return data;
}
@Override
protected void doExport(DemoItemDynamicExcelExportTask exportTask, ExcelDefinitionContext context) {
if (null != exportTask.getSync() && exportTask.getSync()) {
excelFileService.doExportSync(exportTask, context);
} else {
excelFileService.doExportAsync(exportTask, context);
}
}
}4.导出效果预览
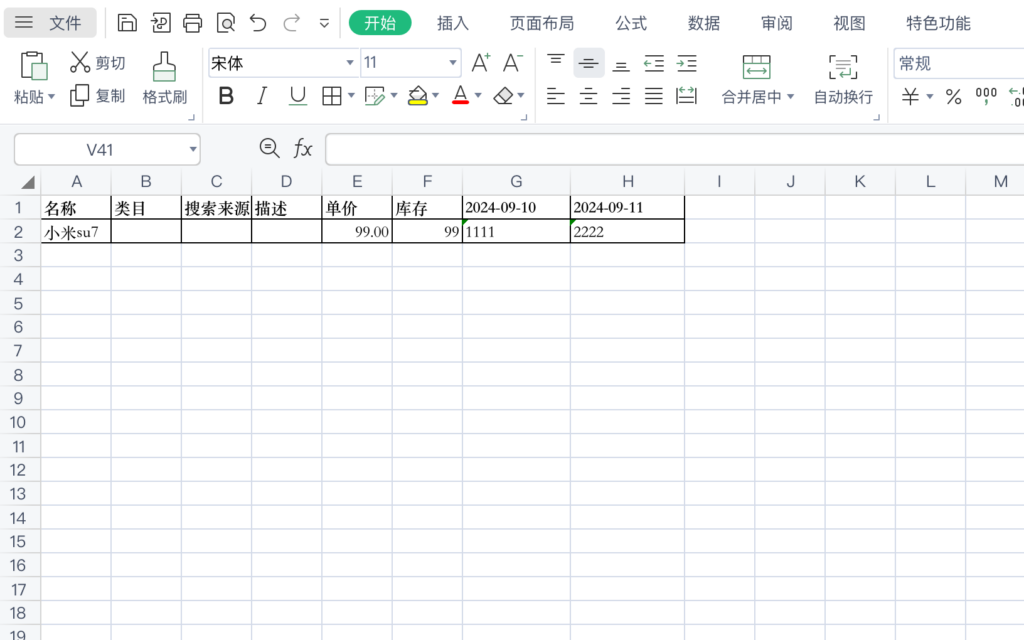

扩展学习
根据上面的例子,我们可以看出,所有需要对表头做自定义的场景都可以通过类似办法在DemoItemDynamicExcelExportTaskAction.fetchExcelDefinitionContextByWorkbookDefinition方法内进行处理
Oinone社区 作者:nation原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/17174.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验