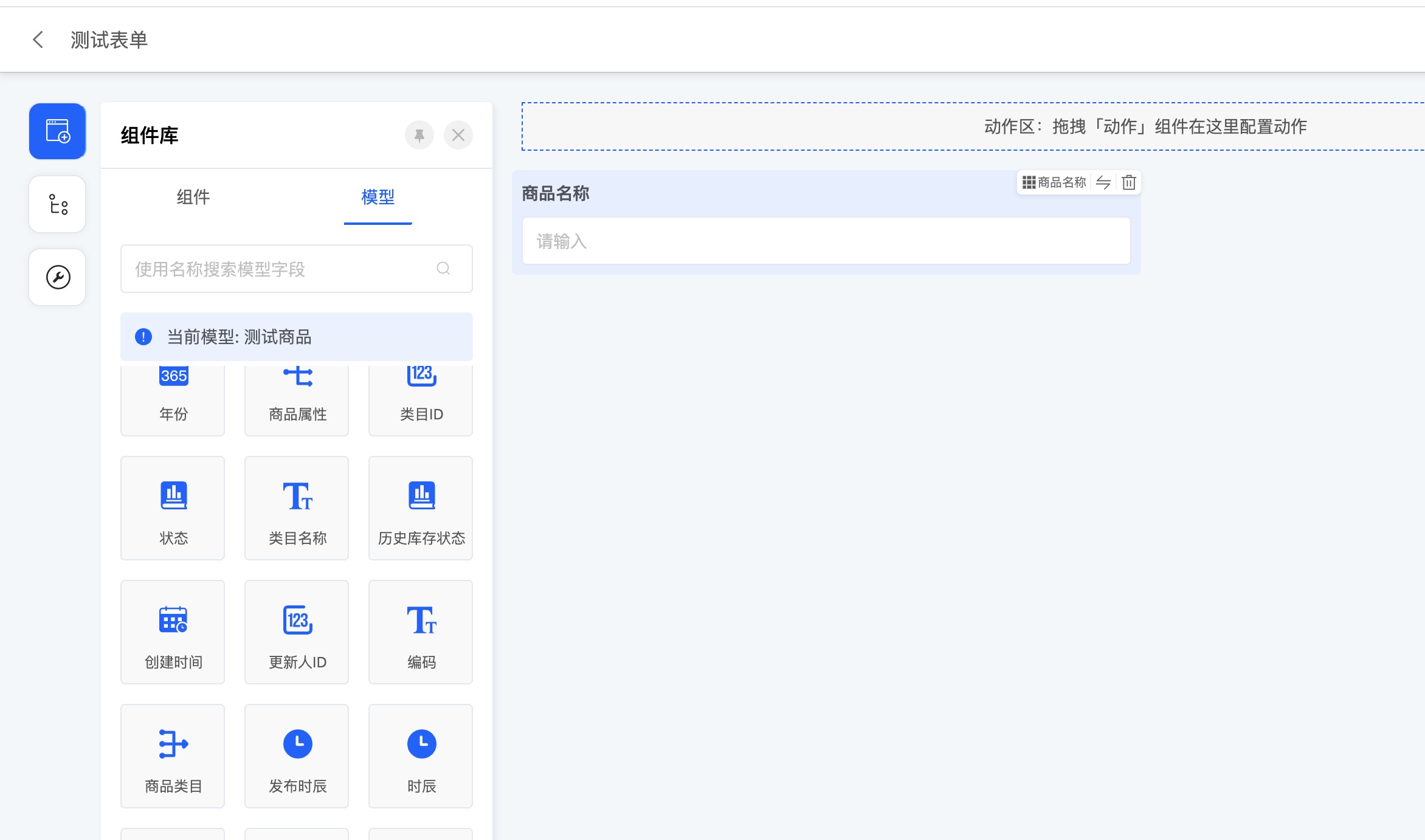
1. 审批/填写节点的视图页面
在界面设计器中创建对应模型的表单视图,可根据业务场景需要自定义所需流程待办的审批页面
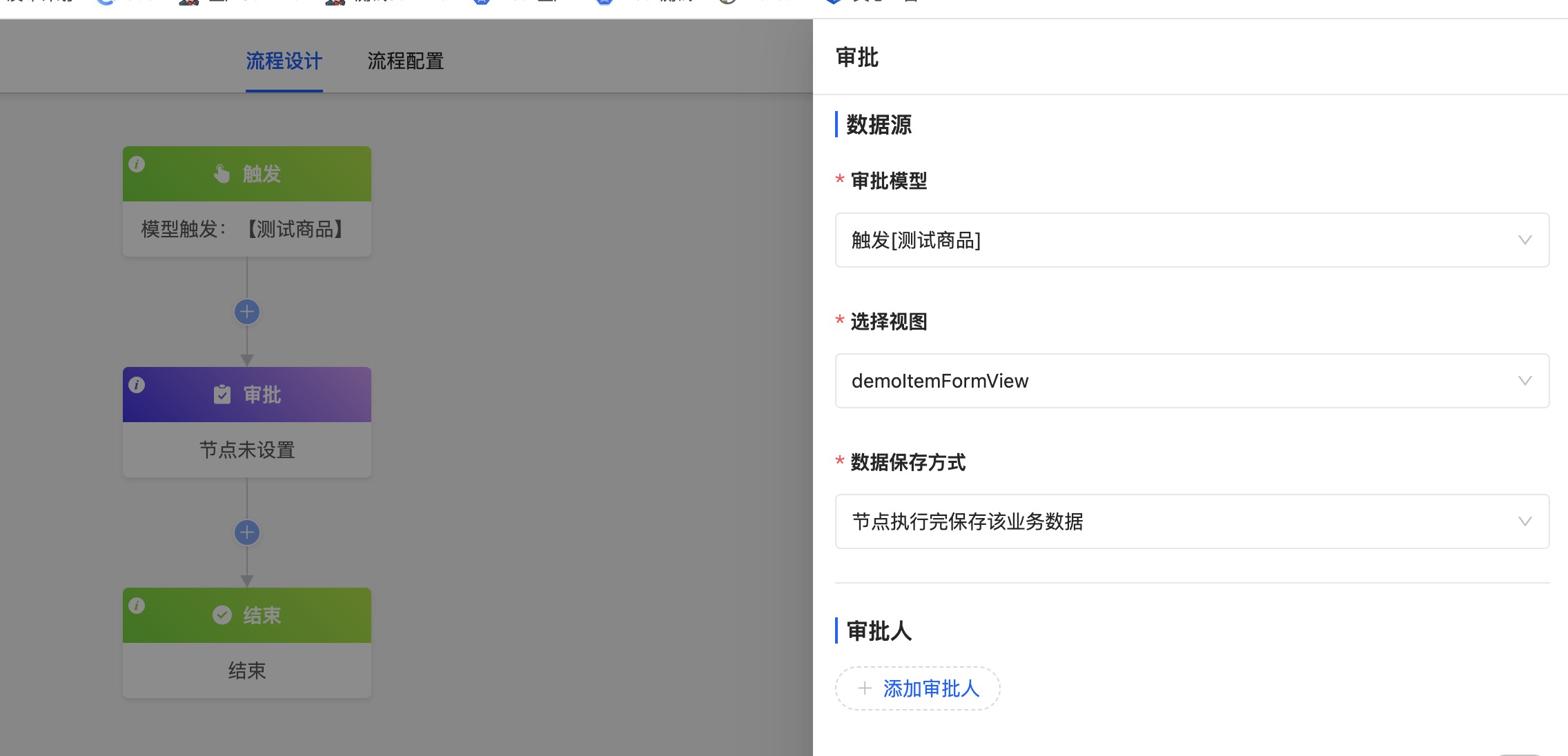
2. 在审批/填写节点中选择刚创建的视图
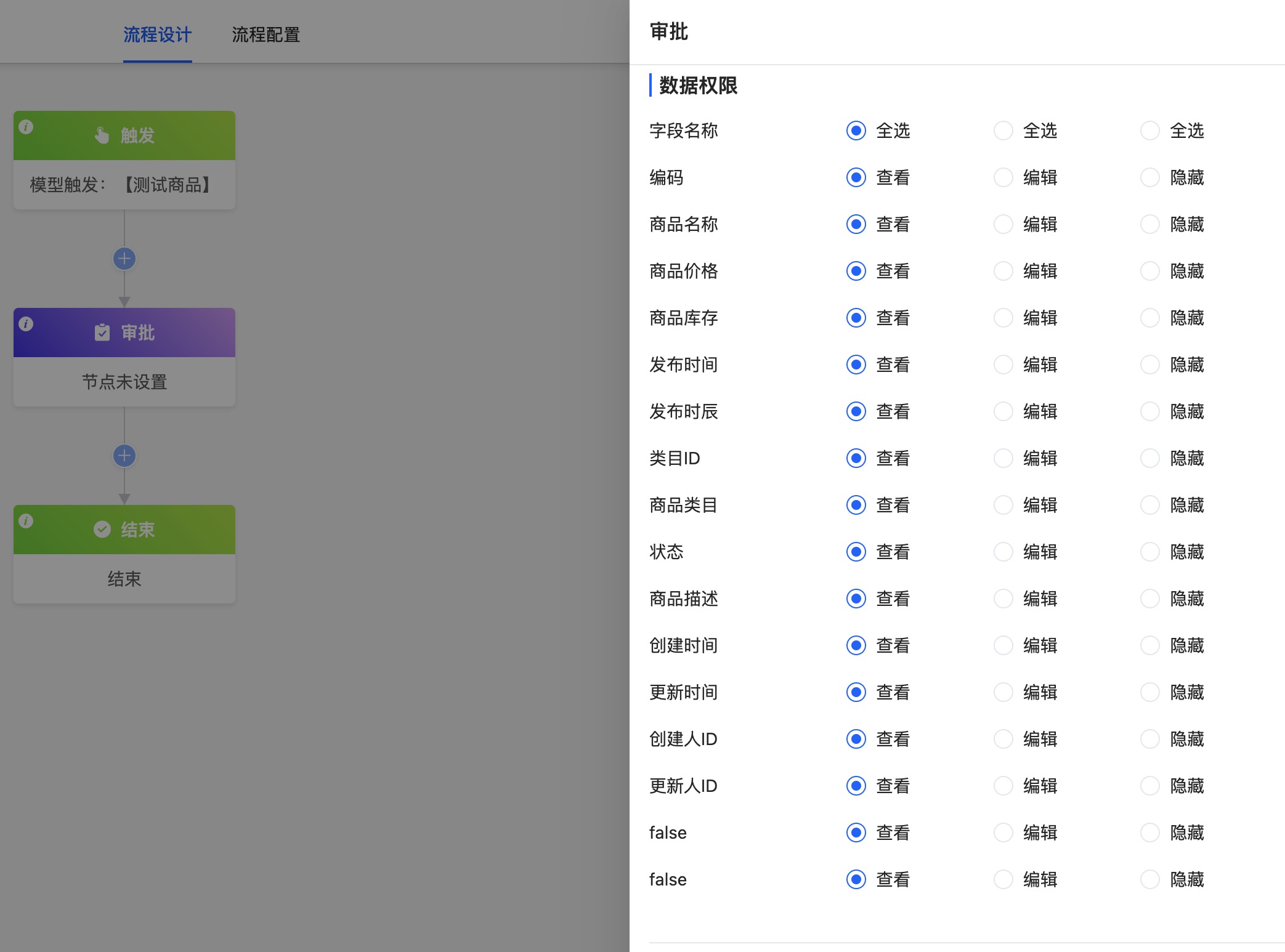
在工作流待办数据权限可在节点数据权限中可对字段设置查看、编辑、隐藏

Oinone社区 作者:数式-海波原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/7224.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验

在界面设计器中创建对应模型的表单视图,可根据业务场景需要自定义所需流程待办的审批页面
2. 在审批/填写节点中选择刚创建的视图
在工作流待办数据权限可在节点数据权限中可对字段设置查看、编辑、隐藏
Oinone社区 作者:数式-海波原创文章,如若转载,请注明出处:https://doc.oinone.top/backend/7224.html
访问Oinone官网:https://www.oinone.top获取数式Oinone低代码应用平台体验
总体介绍 在共库共Redis的情况下,某些场景存在需要过滤掉特定Hook和扩展点(extpoint)的情况。本文介绍排除掉的配置方法 1. Oinone如何排除特定的Hook 配置: pamirs: framework: hook: excludes: – 排除的扩展点列表 示例: pamirs: framework: hook: excludes: – pro.shushi.pamirs.timezone.hook.TimezoneHookBefore – pro.shushi.pamirs.timezone.hook.TimezoneHookAfter – pro.shushi.pamirs.timezone.hook.TimezoneSessionInitHook – pro.shushi.pamirs.translate.hook.TranslateAfterHook 2. Oinone如何排除特定的扩展点 配置 pamirs: framework: extpoint: excludes: – 排除的扩展点列表 示例: pamirs: framework: extpoint: excludes: – pro.shushi.pamirs.demo.core.extpoint.PetCatTypeExtPoint
总体描述 引入Oinone的搜索(即Channel模块)后,因错误的配置、缺少配置或者少引入一些Jar包,会出现一些报错。 问题1:启动报类JCTree找不到 具体现象 启动过程可能会出现报错:java.lang.NoClassDefFoundError: com/sun/tools/javac/tree/JCTree$JCExpression 产生原因 引入Channel模块后,启动过程中会扫描Class包找寻Enhance的注解,Pamirs底层有使用到jdk的tools中的类, com/sun/tools/javac/tree/JCTree$JCExpression 特定版本的jdk可能会缺少tools.jar导致启动失败 具体报错 at org.springframework.boot.loader.Launcher.launch(Launcher.java:107) [pamirs-venus-boot.jar:na] at org.springframework.boot.loader.Launcher.launch(Launcher.java:58) [pamirs-venus-boot.jar:na] at org.springframework.boot.loader.JarLauncher.main(JarLauncher.java:88) [pamirs-venus-boot.jar:na] Caused by: java.util.concurrent.ExecutionException: java.lang.NoClassDefFoundError: com/sun/tools/javac/tree/JCTree$JCExpression at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357) ~[na:1.8.0_381] at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908) ~[na:1.8.0_381] at pro.shushi.pamirs.boot.common.initial.PamirsBootMainInitial.init(PamirsBootMainInitial.java:66) ~[pamirs-boot-api-4.6.10.jar!/:na] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_381] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_381] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_381] at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_381] at org.springframework.context.event.ApplicationListenerMethodAdapter.doInvoke(ApplicationListenerMethodAdapter.java:305) ~[spring-context-5.2.12.RELEASE.jar!/:5.2.12.RELEASE] … 20 common frames omitted Caused by: java.lang.NoClassDefFoundError: com/sun/tools/javac/tree/JCTree$JCExpression at java.lang.Class.forName0(Native Method) ~[na:1.8.0_381] at java.lang.Class.forName(Class.java:264) ~[na:1.8.0_381] at pro.shushi.pamirs.meta.util.ClassUtils.getClasses(ClassUtils.java:157) ~[pamirs-meta-model-4.6.8.jar!/:na] at pro.shushi.pamirs.meta.util.ClassUtils.getClassesByPacks(ClassUtils.java:73) ~[pamirs-meta-model-4.6.8.jar!/:na] at pro.shushi.pamirs.channel.core.manager.EnhanceModelScanner.enhanceModel(EnhanceModelScanner.java:51) ~[pamirs-channel-core-4.6.15.jar!/:na] at pro.shushi.pamirs.channel.core.init.ChannelSystemBootAfterInit.init(ChannelSystemBootAfterInit.java:31) 解决办法 方式一【推荐】、配置channel的扫描路径 pamirs: channel: packages: – com.pamirs.ic 方式二、使用Oracle版本的jdk,确保jdk的lib目录,tools.jar有com/sun/tools/javac/tree/JCTree对应的类 问题2:启动报类JsonProvider找不到 具体报错 如果启动报错信息如下: Caused by: java.lang.NoClassDefFoundError: jakarta/json/spi/JsonProvider at java.lang.ClassLoader.defineClass1(Native Method) ~[na:1.8.0_181] at java.lang.ClassLoader.defineClass(ClassLoader.java:763) ~[na:1.8.0_181] at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) ~[na:1.8.0_181] at java.net.URLClassLoader.defineClass(URLClassLoader.java:467) ~[na:1.8.0_181] 产生原因 项目中只引入了pamirs-channel-core,但未引入elasticsearch相关的包 解决办法 <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-client</artifactId> <version>8.4.1</version> </dependency> <dependency> <groupId>jakarta.json</groupId> <artifactId>jakarta.json-api</artifactId> <version>2.1.1</version> </dependency> 其他参考: Oinone引入搜索引擎步骤:https://doc.oinone.top/backend/7235.html
低无一体使用 (后端) 低无一体应用 打开低无一体应用。 选择应用模块 在选择模块选择框中,下拉选择需要使用低无一体的应用模块。 生成SDK 点击生成SDK, 生成当前选择应用模块的低无一体SDK。 点击之后的系统消息 提示"生成SDK成功",表示操作完成。 生成扩展工程 点击下载扩展工程模板, 生成当前选择应用模块的低无一体SDK。 点击之后的系统消息 提示"下载扩展工程模板成功",表示操作完成。 之后刷新页面 下载扩展工程 使用系统消息中的链接或者详情页中的下载地址下载扩展工程 扩展工程结构概览 自定义Action示例 import org.springframework.stereotype.Component; import pro.shushi.oinone.stand.testExt.model.Model0000000001; import pro.shushi.pamirs.meta.annotation.Action; import pro.shushi.pamirs.meta.annotation.Function; import pro.shushi.pamirs.meta.annotation.Model; import pro.shushi.pamirs.meta.api.dto.condition.Pagination; import pro.shushi.pamirs.meta.api.dto.wrapper.IWrapper; import pro.shushi.pamirs.meta.constant.FunctionConstants; import pro.shushi.pamirs.meta.enmu.FunctionOpenEnum; import pro.shushi.pamirs.meta.enmu.FunctionTypeEnum; /** * Model0000000001Action * * @author yakir on 2025/01/20 14:59. */ @Component @Model.model(Model0000000001.MODEL_MODEL) public class Model0000000001Action { @Function.Advanced(type = FunctionTypeEnum.QUERY) @Function.fun(FunctionConstants.queryPage) @Function(openLevel = {FunctionOpenEnum.API}) public Pagination<Model0000000001> queryPage(Pagination<Model0000000001> page, IWrapper<Model0000000001> queryWrapper) { return new Model0000000001().queryPage(page, queryWrapper); } @Action(displayName = "sayHello") @Action.Advanced(type = FunctionTypeEnum.QUERY) public Model0000000001 sayHello(Model0000000001 query) { query.setName(query.getName() + System.currentTimeMillis()); return query; } } 注意事项 ⚠️⚠️⚠️ Oinone底层依赖版本与设计器和业务应用一致 (参考 版本更新日志 ) 扩展工程如需独立启动, 手动修改application.yml中安装模块和pom.xml中模块jar的依赖配置
概述 Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。 Oinone平台默认使用dubbo-v2.7.22版本,本文以该版本为例进行描述。 基本概念 Dubbo在注册provider/consumer时使用Netty作为RPC调用的核心服务,其具备客户端/服务端(C/S)的基本特性。即:provider作为服务端,consumer作为客户端。 客户端通过服务中心发现有服务可被调用时,将通过服务中心提供的服务端调用信息,连接服务端并发起请求,从而实现远程调用。 服务注册(绑定Host/Port) JAVA程序启动时,需要将provider的信息注册到服务中心,并在当前环境为Netty服务开启Host/Port监听,以实现服务注册功能。 在下文中,我们通过绑定Host/Port表示Netty服务的访问地址,通过注册Host/Port表示客户端的访问地址。 使用yaml配置绑定Host/Port PS:该配置可在多种环境中通用,改变部署方式无需修改此配置。 dubbo: protocol: name: dubbo # host: 0.0.0.0 port: -1 假设当前环境的可用IP为192.168.1.100 以上配置将使得Netty服务默认绑定在0.0.0.0:20880地址,服务注册地址为192.168.1.100:20880 客户端将通过192.168.1.100:20880调用服务端服务 若发生20880端口占用,则自动向后查找可用端口。如20881、20882等等 若当前可用端口为20881,则以上配置将使得Netty服务默认绑定在0.0.0.0:20881地址,服务注册地址为192.168.1.100:20881 使用环境变量配置注册Host/Port 当服务端被放置在容器环境中时,由于容器环境的特殊性,其内部的网络配置相对于宿主机而言是独立的。因此为保证客户端可以正常调用服务端,还需在容器中配置环境变量,以确保客户端可以通过指定的注册Host/Port进行访问。 以下示例为体现无法使用20880端口的情况,将宿主机可访问端口从20880改为20881。 DUBBO_IP_TO_REGISTRY=192.168.1.100 DUBBO_PORT_TO_REGISTRY=20881 假设当前宿主机环境的可用IP为192.168.1.100 以上配置将使得Netty服务默认绑定在0.0.0.0:20881地址,服务注册地址为192.168.1.100:20881 客户端将通过192.168.1.100:20881调用服务端服务 使用docker/docker-compose启动 需添加端口映射,将20881端口映射至宿主机20881端口。(此处容器内的端口发生变化,若需要了解具体原因,可参考题外话章节) docker-run IP=192.168.1.100 docker run -d –name designer-allinone-full \ -e DUBBO_IP_TO_REGISTRY=$IP \ -e DUBBO_PORT_TO_REGISTRY=20881 \ -p 20881:20881 \ docker-compose services: backend: container_name: designer-backend image: harbor.oinone.top/oinone/designer-backend-v5.0 restart: always environment: DUBBO_IP_TO_REGISTRY: 192.168.1.100 DUBBO_PORT_TO_REGISTRY: 20881 ports: – 20881:20881 # dubbo端口 使用kubernetes启动 工作负载(Deployment) kind: Deployment apiVersion: apps/v1 spec: replicas: 1 template: spec: containers: – name: designer-backend image: harbor.oinone.top/oinone/designer-backend-v5.0 ports: – name: dubbo containerPort: 20881 protocol: TCP env: – name: DUBBO_IP_TO_REGISTRY value: "192.168.1.100" – name: DUBBO_PORT_TO_REGISTRY value: "20881" 服务(Services) kind: Service apiVersion: v1 spec: type: NodePort ports: – name: dubbo protocol: TCP port: 20881 targetPort: dubbo nodePort: 20881 PS:此处的targetPort为对应Deployment#spec. template.spec.containers.ports.name配置的端口名称。若未配置,可使用20881直接指定对应容器的端口号。 使用kubernetes其他暴露服务方式 在Kubernetes中部署服务,有多种配置方式均可用暴露服务。上述配置仅用于通过Service/NodePort将20881端口暴露至宿主机,其他服务可用通过任意Kubernetes节点IP进行调用。 若其他服务也在Kubernetes中进行部署,则可以通过Service/Service方式进行调用。将DUBBO_IP_TO_REGISTRY配置为${serviceName}.${namespace}即可。 若其他服务无法直接访问Kubernetes的master服务,则可以通过Ingress/Service方式进行调用。将DUBBO_IP_TO_REGISTRY配置为Ingress可解析域名即可。 Dubbo调用链路图解 PS: Consumer的绑定Host/Port是其作为Provider使用的,下面所有图解仅演示单向的调用链路。 名词解释 Provider: 服务提供者(JVM) Physical Machine Provider: 服务提供者所在物理机 Provider Container: 服务提供者所在容器 Kubernetes Service: Kubernetes Service资源类型 Consumer: 服务消费者(JVM) Registration Center: 注册中心;可以是zookeeper、nacos等。 bind: 服务绑定Host/Port到指定ip:port。 registry: 服务注册;注册Host/Port到注册中心的信息。 discovery: 服务发现;注册Host/Port到消费者的信息。 invoke: 服务调用;消费者通过注册中心提供的提供者信息向提供者发起服务调用。 forward: 网络转发;通常在容器环境需要进行必要的网络转发,以使得服务调用可以到达服务提供者。 物理机/物理机调用链路 “` mermaidsequenceDiagram participant p as Provider<br>(bind 0.0.0.0:20880)participant m as Physical Machine Provider<br>(bind 192.168.1.100:20881)participant…